


Петабайты каждый день: как хранить и использовать данные с умом

Как компаниям эффективно хранить и масштабировать big data? Разбираем решения с экспертом VK Cloud.
207 открытий5К показов

Каждый день в мире генерируется более 400 миллионов терабайт данных. Возможно, стоило бы отпраздновать эту цифру, но компаниям все сложнее хранить такие объемы. С одной стороны, — это вопрос оптимизации стоимости. С другой, — удобства использования и масштабирования.
В этом материале вместе со Станиславом Погоржельским, технологическим евангелистом платформы VK Cloud, разберем особенности решений для хранения и работы с большими данными.

Станислав Погоржельский
Технологический евангелист платформы VK Cloud
Особенности локальных хранилищ
Стоит держать в уме, что выбор таких решений не всегда зависит от архитектурных принципов и лучших практик, а чаще всего от наличия определенной экспертизы в компании. Проведем очную ставку трех основных моделей построения хранилищ.
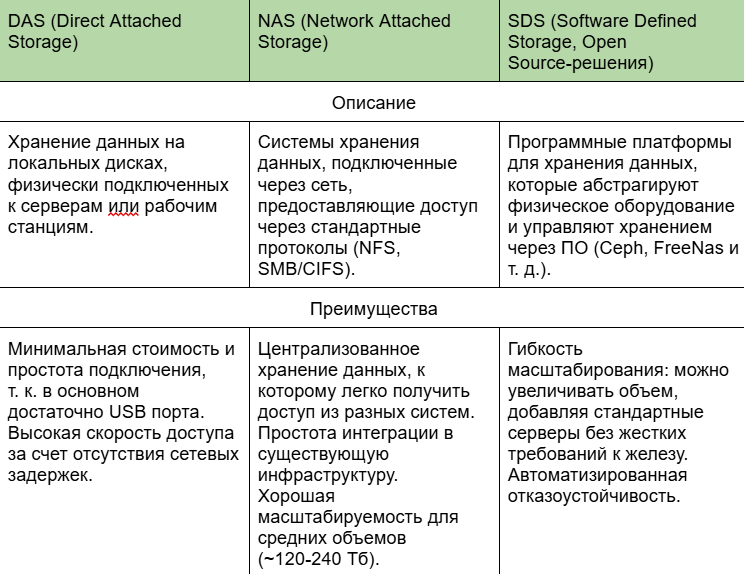
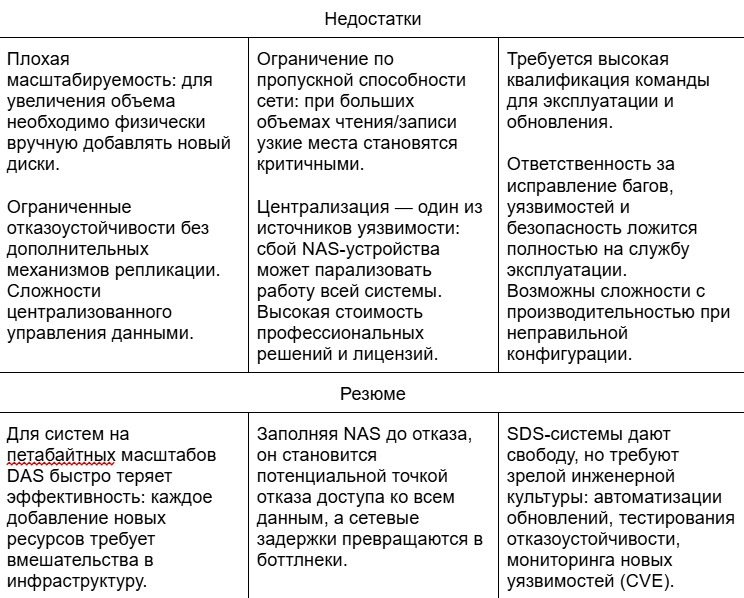
Семь «грехов» локальных кластеров
Теперь поговорим о том, какие неприятные особенности встречаются во время эксплуатации локальных кластеров.
Структура данных и хаос
В реальных системах данные редко бывают аккуратными. Вместо красивых таблиц разработчик часто сталкивается с миллионами мелких файлов по 1-2 Кб и, например, видео по несколько Гб. Такие крайности требуют противоположных стратегий хранения и кэширования.
Файловая система, не оптимизированная для работы с малыми файлами, быстро забивается inode'ами (переполнение файловых дескрипторов). Системы хранения начинают задыхаться не от общего объема, а от количества объектов, что критически влияет на производительность. Например, известны случаи, когда после миллиона объектов OpenStack Swift начинал терять метаданные, а в хранилищах висели призраки удаленных объектов.
RAID — не универсальное спасение
Настройка RAID-массивов кажется очевидным решением, но не все так однозначно:
- RAID 5 и 6 плохо переносят большие объемы из-за длительного времени восстановления.
- RAID 10 требует удвоения или утроения объема хранения ради скорости и отказоустойчивости.
- На петабайтных объемах пересборка массива после сбоя может занимать больше недели.
Поддержка архивов и ZIP-файлов
Архивирование данных (например, с помощью ZIP) спасает место, но приводит к другим проблемам: невозможность выборочного доступа к отдельным файлам без полной распаковки, рост времени обработки запросов, сложность мониторинга целостности данных.
Массовая работа с архивами требует настройки кэширования и часто вынуждает строить параллельные системы для индексации содержимого архивов.
Автоматизация мониторинга и ремонта
Любая система хранения живет с постоянным риском деградации: умирают диски, выходят из строя контроллеры, падают сети. На уровне сотен и тысяч узлов мониторинг «вручную» невозможен: требуется автоматизированная оркестрация алертов, самовосстановление, динамическая миграция данных на здоровые узлы. Иначе разрастание локальных отказов перерастает в потерю данных.
Шардирование данных: неизбежность и боль
На больших объемах данных (более 250 Тб) приходится шардировать — разбивать на независимые логические части, чтобы сохранить производительность. Но с шардированием есть проблемы:
- усложняет маршрутизацию запросов;
- увеличивает сложность восстановления данных при сбоях;
- требует отдельных механизмов ребалансировки шардов при добавлении новых узлов.
Более того, встроенные механизмы шардирования некоторых популярных СУБД (MongoDB, PostgreSQL с партиционированием) не рассчитаны на миллиарды записей и начинают деградировать.
Проблемы метаданных
Каждый файл и объект требуют метаданных: даты создания, размера, доступа, хеш-суммы. При росте числа объектов метаданные сами по себе становятся огромными: терабайты информации, требующие отдельного хранения, индексирования и защиты.
Резервное копирование на практике
Бэкап петабайта данных требует продуманной стратегии инкрементальных копий, дедупликации, постоянного тестирования восстановления. Локальное хранение больших объемов данных — это не про покупку железа и развертывание файлового сервера. Это бесконечная инженерная работа по балансировке между скоростью, надежностью, стоимостью и сложностью системы.
Хранение больших объемов обостряет вопросы производительности, резервного копирования и автоматизации мониторинга, где каждый аспект требует балансировки между скоростью, надежностью и сложностью ИТ-инфраструктуры.
Облачные хранилища
С локальными хранилищами разобрались, теперь рассмотрим технические особенности альтернативного решения.
Гибкость и масштабируемость без ограничений
В облаке увеличение объемов хранения происходит мгновенно:
- без ожидания закупки нового оборудования;
- без сложного планирования миграций;
- без перебоев в обслуживании приложений.
Эксплуатация и разработчики могут динамически добавлять терабайты и петабайты данных в рамках одного API-запроса. Облачное хранилище предлагает готовое решение для масштабирования от стартапов до международного уровня компаний.
Финансовая прозрачность и удобная модель оплаты
Модель Pay-As-You-Go (оплата по факту использования) дает бизнесу и разработчикам:
- предсказуемость расходов;
- возможность мгновенно адаптировать инфраструктуру под изменяющиеся требования;
- отсутствие необходимости капитальных затрат на старте;
- гибкость в выборе тарифов хранения (горячие, холодные, архивные данные).
Такая прозрачная модель помогает экономить бюджет без потери качества сервиса.
Надежность и отказоустойчивость «из коробки»
S3-совместимый Object Storage обеспечивает высокую доступность данных благодаря:
- автоматической репликации данных в нескольких географических регионах;
- встроенным механизмам самовосстановления данных;
- резервированию оборудования на уровне дата-центров;
- постоянному мониторингу целостности объектов.
Оптимизация работы с любыми типами данных
Хранилище позволяет одинаково эффективно работать:
- с миллионами мелких файлов (фото, документы, логи);
- с тяжелыми объектами (видео или архивами).
Облачная платформа автоматически оптимизирует хранение и доступ, снижая латентность и ускоряя обработку даже при экстремальных нагрузках.
Высокий уровень безопасности данных
В облаке предоставляется комплексная защита данных с помощью:
- шифрования на стороне клиента и сервера;
- гибкого управления правами доступа (ACL, IAM);
- соответствия требованиям хранения ПДН и прочих стандартов безопасности;
- автоматического обнаружения потенциальных уязвимостей.
Безопасность данных обеспечивается на каждом уровне инфраструктуры и подтверждается регулярными внешними аудитами.
Инструменты для разработчиков и автоматизации
Хранение данных в облаке ориентировано на удобство интеграции и масштабирование за счет:
- полного набора API и SDK для популярных языков программирования;
- готовых модулей для работы с данными в распределенных системах;
- продвинутых средств мониторинга, алертинга и автоскейлинга;
- поддержки DevOps практик через IaC-инструменты.
Автоматизация всех процессов упрощает разработку и сопровождение проектов, значительно снижая риски человеческих ошибок.
Опыт хранения больших данных
Когда речь идет о масштабных системах хранения — таких как S3-совместимый сервис Object Storage на платформе VK Cloud, — производительность определяется не только скоростью сети и дисков. Ключевую роль играют архитектурные особенности приложений: как именно данные распределяются, обрабатываются и индексируются.
Особенно важно это в системах с огромным количеством объектов, где миллионы или миллиарды файлов разного размера постоянно создаются, обновляются и удаляются.
Как измеряется производительность облачного хранилища
Для реальной оценки производительности облачного хранилища важно замерять:
- Количество операций в секунду (RPS): сколько запросов на чтение/запись способна обработать система.
- Среднюю и 99-ю персентиль задержек: критично для оценки качества обслуживания конечных пользователей.
- Производительность на больших объемах объектов: важно не просто тестировать один файл, а моделировать реальную работу приложений с множеством параллельных операций.
- Влияние мелких и крупных файлов: системы по-разному работают при миллионах маленьких объектов и гигабайтных видео.
Практические сценарии измерений:
- многопоточная загрузка 100 миллионов объектов размером 1–10 КБ;
- массовое чтение миллионов объектов через S3 API;
- удаление больших объемов объектов для оценки работы сборки мусора;
- сценарии с версионированием объектов, чтобы проверить нагрузку на метаданные.
Почему шардирование критически важно для облачного хранилища
Правильная организация шардирования данных — один из ключевых факторов производительности больших хранилищ.
Что происходит без правильного шардирования:
- «Горячие» бакеты (S3-бакеты) с высокой нагрузкой становятся узким местом.
- Распределение нагрузки по серверам становится неравномерным.
- Метаданные начинают тормозить операции доступа.
- Снижается общая масштабируемость системы.
Реальная практика VK Cloud:
- Метаданные объектов распределяются по кластерам через шардирование по диапазонам ключей.
- При превышении нагрузки шард автоматически расщепляется (split) для перераспределения нагрузки между нодами.
- Для хранения метаданных используется Tarantool как высокоскоростная in-memory база данных, способная выдерживать сотни тысяч операций в секунду на один шард.
Такой подход позволяет обеспечить:
- низкие задержки доступа даже при миллиардах объектов;
- линейное масштабирование — добавление новых серверов дает реальный прирост пропускной способности;
- быструю обработку как мелких, так и больших файлов без перегрузки одной ноды.
С увеличением объема метаданных нагрузка на отдельные узлы или компоненты системы возрастает, что ограничивает масштабируемость и может снижать производительность при высоких требованиях к обработке данных.
За что мы любим Tarantool
Принцип работы СУБД Tarantool кардинально отличается от классических SQL-баз (PostgreSQL, MySQL) в хранилищах:
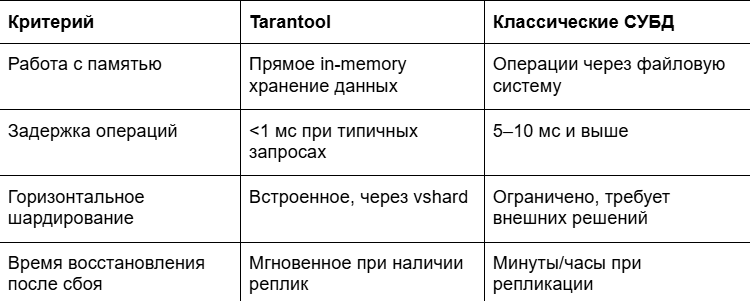
Tarantool позволяет работать с облачным хранилищем на скорости, которую классические базы не способны обеспечить без радикальных усилий по оптимизации.
Как правильно проектировать нагрузку на S3-совместимое облако
Если вы проектируете высоконагруженную систему, важно:
- Использовать естественное шардирование ключей (например, вставлять случайные префиксы в имена объектов).
- Ожидать миллионы объектов в бакете и строить приложения так, чтобы они не зависели от скорости листинга всех файлов.
- Минимизировать количество операций массового удаления объектов — использовать batch-удаление через S3 API.
- Понимать, что работа с метаданными так же важна, как и сама передача данных.
Производительность облачного хранилища определяется не только сетью и железом, но и архитектурой работы с данными. Правильное шардирование, оптимизация структуры ключей и использование быстрых конечных СУБД — основа эффективных и масштабируемых сервисов.
Заключение
Работа с петабайтными объемами данных требует серьезного подхода к проектированию инфраструктуры. На этом пути локальные решения сталкиваются с проблемами масштабирования, отказоустойчивости, обновления оборудования и обеспечения безопасности. Управление инфраструктурой превращается в отдельный проект со своими ресурсами.
Облачное хранилище обеспечивает:
- автоматическое масштабирование объема хранения без потерь в производительности;
- высокую доступность данных благодаря распределению по зонам отказа;
- прозрачную модель оплаты — вы платите только за реально используемые ресурсы;
- эффективную работу как с миллионами мелких файлов, так и с крупными объектами;
- безопасность данных с помощью встроенного шифрования и управления доступом через IAM;
- богатый инструментарий API для полной интеграции в любые архитектуры приложений.
Облачные хранилища предоставляют возможность компаниям сосредоточиться на развитии своих продуктов и бизнес-логики, передав инфраструктурные задачи профессиональной облачной платформе.

207 открытий5К показов

Python и SQL — самые популярные инструменты для работы с данными. Но какой из них изучать первым? Разбираемся в статье.

Исследуем этику искусственного интеллекта. Раскроем, как формируются этические нормы, регулирующие решения ИИ-систем. Кто ответственен за действия интеллектуальных машин: разработчики, пользователи или государство?

Stack Overflow навсегда запретил публикацию контента, созданного с помощью ИИ, из-за частых ошибок в таких ответах. Решение принято после того, как платформа столкнулась с массовым потоком низкокачественного контента, который затруднял поиск достоверных ответов

Узнайте, стоит ли использовать антивирус в 2025 году и как выбрать защиту для Windows и Linux. Анализ 7 главных мифов: от нагрузки на систему до эффективности против новых угроз. Обзор EDR-решений и встроенных защитников..