Наперегонки со временем: на что способен Python в однопоточных вычислениях?

Многие знают, что Python в чистом виде — не лучший язык для научных вычислений. Однако никто не мешает провести эксперимент по его ускорению.

Валерий Голенков
разработчик из компании Sibedge
Языки программирования изначально проектируются для решения определённых групп задач, и каждый по-своему удобен и уникален. Известный долгожитель, язык C, используется в разработке системного программного обеспечения. C#, детище компании Microsoft, незаменим при написании десктопных приложений для Windows, а старичок PHP по-прежнему полезен в работе с бэкендом. Неужели за десятилетия существования программирования не было попыток создать единый, универсальный язык, подобный кольцу всевластия, которое правит всеми?
К сожалению, всё не так просто. Как не существует универсального закона Вселенной, так не существует и языка, способного эту Вселенную описать. Каждый язык программирования, спроектированный с прицелом на решение определённого набора задач, в чём-то сильно уступает остальным языкам. Где проходят границы применимости языков? В поиске ответа на этот вопрос некоторые программисты осуществляют интересные эксперименты. Об одном из таких опытов пойдёт речь чуть ниже.
Разработчик Валерий Голенков из компании Sibedge более 10 лет пишет приложения на разных языках. Однажды знакомый попросил его помочь с объёмным расчётом систем уравнений для научного проекта. Валерий решил попробовать решить задачу при помощи языка Python, который, согласно исследованиям IEEE Spectrum, занимает первое место в рейтинге популярности среди программистов, а также активно используется для научных расчётов в составе пакета Anaconda.
Слишком много данных
Вот так выглядят исходные системы уравнений:

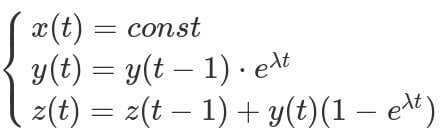
Пусть вас не пугает массивность систем — даже начинающий программист сможет перевести эти формулы в код. Но здесь, прямо как в старом анекдоте, есть один нюанс: каждое последующее вычисление функций зависит от предыдущего. Это значит, что распараллелить процесс не получится и считать всё придётся последовательно. Ситуация усугубляется ещё и тем, что значение функций нужно рассчитать на временном отрезке протяжённостью в 10 дней с частотой в 1 наносекунду. Ядерная физика — это вам не шутки. 1 миллиард вычислений в секунду по четырём значениям с плавающей точкой и 864 триллиона вычислений в общей сложности.
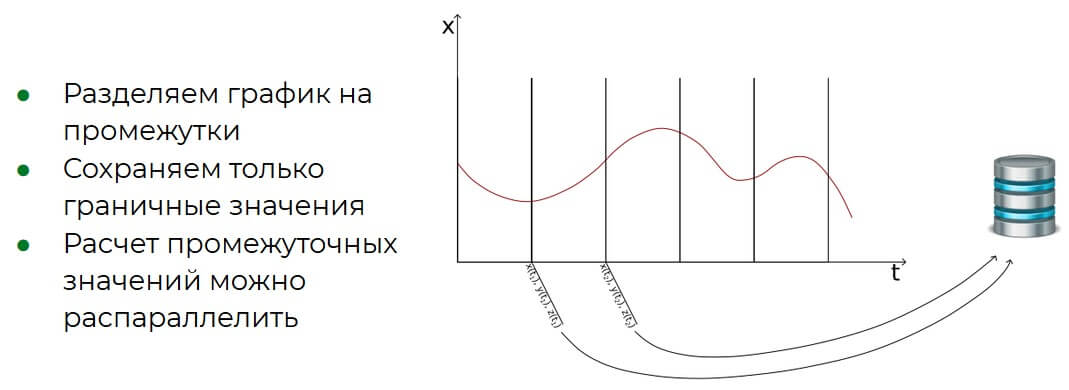
Все эти вычисления требуются для изображения различных временных участков на графике, что позволит учёным оценить поведение системы. Назревает вопрос: как системе управления базами данных не захлебнуться от такого огромного потока информации? Решение было найдено быстро. Раз системы меняются по очереди, в базу можно сохранять только пограничные значения режимов, при необходимости рассчитывая промежуточные данные на ходу. При таком подходе процесс можно будет частично распараллелить, передавая на потоки отдельные временные промежутки.
Первые расчёты
Как пелось в одной небезызвестной песне: «В жизни важен первый шаг». Таким шагом на пути к решению нашей задачи является черновой вариант программы, созданный для примерной оценки времени расчёта. В нём системы уравнений реализованы как функции языка (в листинге ниже приведён фрагмент с расчётом второй системы). На вход они получают четыре рациональных числа (x, y, z, t), а обратно возвращают три (x, y, z).
Начальные значения функций, длительность расчёта и прочие константы будем хранить во внешнем файле формата JSON и загружать его при запуске в статическое поле класса настроек с помощью статического же метода. Для удобства упростим обращение к полям в классе настроек при помощи метакласса. В функции main создадим основной цикл с управляющей переменной mode. Эта переменная будет хранить информацию о том, по какой системе в данную итерацию считать значения функций. Здесь же производится вызов расчёта функций. Easy!
Считает наша программа отлично, но медленно. На обработку отрезка в 0.1 секунды уходит 338.19 секунд реального времени. Внезапно наступает осознание того, что до конца расчёта десятидневного отрезка руководитель проекта может не дожить. Ведь окончания процесса ему придётся ждать более 90 лет. Не будем изобретать машину времени, а вместо этого начнём оптимизировать программу.
Начинаем оптимизацию
Поработаем со структурами и алгоритмами. Когда накидываешь код вслепую, обычно рассматриваешь структуры с точки зрения удобства их использования. В нашем случае — это хранение всех настроек программы в модифицированном классе Settings. Однако, если в Python нужен быстрый доступ к некоторым настройкам, лучше рассмотреть вариант их раздельного хранения в структурах с быстрым доступом. Например, определённые константы для расчёта можно сохранить в namedtuple — immutable (read-only или неизменяемом) контейнере, или использовать самодельный класс с __slots__ как mutable (изменяемый, расширяемый). Причём второй в некоторых случаях лучше первого, так как специфика __slots__ разрабатывалась для экономии памяти.
Что это такое? Это статическое поле класса, в котором содержится список его атрибутов. Визуально просто, но сложно внутри. Если в классе содержится это поле, то все описанные атрибуты класса помещаются CPython в массив фиксированного размера, обращаться к которому будет намного быстрее. Минус такого подхода — больше вы не сможете присваивать другие параметры объектам данного класса. Но в нашем случае скорость важнее.
Мы активно используем в функциях класс Settings для получения констант расчётов. Давайте вынесем все необходимые константы в структуру namedtuple, которую мы и будем передавать функциям в качестве аргумента вместо класса Settings.
Что в итоге нам это дало? Продолжительность расчёта отрезка в 0.1 секунды сократилась до 215 секунд. А это уже всего 58 лет. Закончить эксперимент желательно до выхода на пенсию, поэтому продолжаем играть в оптимизацию.
Меньше вызовов
Задумывались ли вы над тем, как часто вызываются наши функции? В CPython каждый вызов влечёт за собой обращение к методу __call__ объекта функции, который требует времени интерпретатора для запуска. При каждом таком обращении интерпретатор выделяет на стеке место для аргументов, определяет тип функции, выполняет её, а затем очищает стек. На первый взгляд этот набор рутинных операций не кажется таким уж «балластом». Но в нашем случае он выполняется каждую итерацию цикла, что влечёт за собой колоссальные временные затраты.
Постараемся сократить количество вызовов функций Python в циклах. Для этого перенесём часть цикла внутрь функций: теперь каждая функция производит расчёт не на одну итерацию, а на несколько, вплоть до того момента, когда значения x, y и z потребуется начать считать уже по другой системе уравнений. Раз уж мы стараемся уменьшить объём хранимых расчётных данных, сохраняя лишь пограничные значения, то и функциям достаточно возвращать только последние из них.
В это сложно поверить, но время расчёта отрезка продолжительностью в 0.1 секунды резко сократилось до 25.04 секунд! Всего-то 7 лет нужно подождать. Однако если приложить дополнительные усилия, можно добиться ещё более впечатляющих результатов.
Локальные переменные
Воспользуемся ещё одной хитростью. Несмотря на то, что мы добились хороших результатов при использовании namedtuple, это ещё не значит, что больше тут оптимизировать нечего. Ради дополнительного прироста скорости имеет смысл извлечь константы (из namedtuple) в локальные переменные, ведь это убирает ещё одну функцию-посредника (__getitem__) при обращении к константам.
И снова уменьшение времени с 25.04 до 20.56 секунд. Конечно, кому-то может показаться, что в сравнении с грамотным проектированием вызовов из предыдущего шага, сокращение на пять секунд не такое впечатляющее. Да только вот при длительных расчётах эти пять секунд могут превратиться в день, два, а то и в целый год! При текущей оптимизации наш расчёт будет длиться менее 6 лет!
От интерпретатора к компилятору
Python — это стандарт языка, по которому существуют его отдельные реализации на C, Java и других языках. Есть даже такой необычный вариант, как Python на Python, или PyPy («ПайПай»). Но это уже не просто интерпретатор, а полноценный JIT-компилятор, на который портированы популярные библиотеки и фреймворки вроде NumPy, SQLAlchemy и Django. Благодаря тому, что байт-код компилируется в машинный код и исполняется процессором, работает это всё ощутимо быстрее, чем на CPython. Попробуем взять наш код и запустить его через PyPy. Что же получилось? Время расчёта интервала в 0.1 секунды снизилось аж до 3.29 секунд! Меньше 1 года понадобится, чтобы завершить процесс.
Если PyPy даёт такой впечатляющий прирост к скорости, то почему разработчики не используют этот компилятор повсеместно? На то есть две причины. Во-первых, он поддерживает далеко не все библиотеки. А во-вторых, для операционных систем Windows существует только 32-разрядная версия компилятора, а это значит, что и библиотеки-зависимости тоже требуются 32-разрядные.
Можно ещё быстрее
С помощью всевозможных ухищрений нам удалось достичь впечатляющих результатов. Но есть ещё один способ значительно ускорить расчёт. И способ этот, как ни смешно, — переписать программу на языке C++. Таким образом мы сможем рассчитывать интервал в 0.1 секунды всего за 0.44 секунды, а на весь процесс уйдёт 44 дня.
Итоги эксперимента

В ходе оптимизации нам удалось повысить скорость расчёта более чем в 100 раз. И всё же использование низкоуровневого языка C++ в нашем случае всё равно оказалось более эффективным. Делаем вполне предсказуемый вывод: Python не подходит для объёмных однопоточных вычислений. Нужно всегда помнить о рамках применимости языка и грамотно выбирать инструменты для решения той или иной задачи. Оптимизация и поиск обходных путей — очень увлекательный процесс. Но время и силы можно потратить и с большей пользой.

12К открытий12К показов

Рассказал, как работают анонимные и стрелочные функции в PHP. А также, на что заменить create_function при переходе с PHP 7.4 на PHP 8.

Рассказываем, почему запрос компаний на миддл-специалистов остаётся высоким, и куда пропали мидлы с IT-рынка.

Твиттер официально сменил название и логотип на Х. Сайт пока открывается по адресу twitter.com, но и домен x.com также открывает соцсеть.

В этой части расписала шаги: от старта разработки ботов на Python до регулярной поддержки. И рассказала про вспомогательные фичи.