Инструмент fairseq от Facebook выполняет машинный перевод в 9 раз быстрее других систем

Команда Facebook AI Research (FAIR) опубликовала впечатляющие результаты работы по реализации fairseq, сверточной нейронной сети для машинного перевода.
Команда Facebook AI Research (FAIR) опубликовала впечатляющие результаты работы по реализации сверточной нейронной сети для машинного перевода. Она утверждает, что fairseq, новый инструмент, работает в 9 раз быстрее традиционных рекуррентных нейронных сетей, при этом совсем незначительно уступая им в точности. Все подготовленные модели и исходники выложены на GitHub.
Почему fairseq такой быстрый?
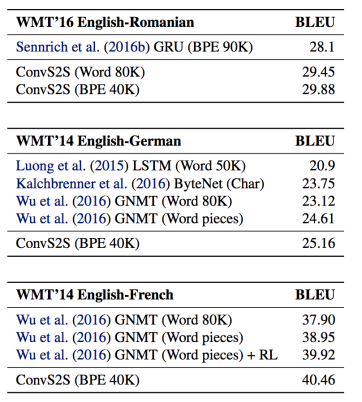
Для оценки качества машинного перевода используется алгоритм BLEU. Facebook оценивала свой результат по трем задачам — перевод с английского на румынский, перевод с английского на немецкий и перевод с английского на французский.
Дэвид Гранжер и Майкл Аули, одни из создателей сети, объяснили, что эти задачи были выбраны не потому, что они являются наиболее сложными для перевода, а потому что для этих пар языков достигнуты наиболее впечатляющие результаты.
Основываясь на этих показателях, применение свёрточных нейронных сетей для машинного перевода является хорошим решением. Но почему для перевода в первую очередь обычно используются рекуррентные сети? Они принимают во внимание информацию временных рядов, что делает их идеальными для решения последовательных задач. Чтение слева направо — отличный пример.
С другой стороны, в последние годы свёрточные сети стали популярными из-за их полезности для анализа визуальной информации. Они обрабатывают информацию одновременно, а не последовательно, что неудобно для машинного перевода. Чтобы такая сеть работала правильно, Facebook реализовала технологию «multi-hop attention» (многоуровневое внимание).

Проблемы машинного перевода
Машинный перевод — это двухэтапный процесс. Будучи людьми, мы можем сразу понимать иностранное предложение на нашем языке, но машине сперва нужно перевести его на свой язык, а потом — на требуемый.
Кроме того, мы не осознаём, что всё определяется вероятностями. Например, слово «пила» может быть как глаголом, так и существительным, и мы оцениваем предложение, подсознательно оценивая вероятности каждого из вариантов. Для этого нам приходится обращаться к контексту этого слова.
Для симуляции этих процессов технология многоуровневого внимания использует одновременный характер свёрточных сетей, позволяющий машинам обращаться к различными частям текста, чтобы понять их смысл во время перевода. Когда это будет сделано и будет создано векторное представление, может быть выведен перевод текста.
Гранжер и Аули считают, что их модели могут быть спроектированы для большего, чем просто машинный перевод. Их сеть может использоваться в любом сценарии, когда компьютер должен понимать текст и что-то выражать: например, для пересказа текста. Кроме того, команда надеется на дальнейшие эксперименты с применением многоуровневого внимания.

1К открытий1К показов
Opera анонсировала выпуск первой стабильной версии браузера Opera One, в который был встроен чат-бот Aria на базе GPT.
OpenAI подала заявку на регистрацию товарного знака GPT-5. Релиз новой версии GPT ожидают в декабре 2023 года.
Рассказываем, как научить GPT-3 рисовать. По умолчанию эта функция недоступна в GPT-3, и воспользоваться ей можно только в GPT-4.

Метод обучения без учителя помогает работать с неразмеченными данными. Разбираемся, какие алгоритмы использовать для решения таких задач.