


Создание настраиваемой библиотеки на Rust — опыт Cloudflare

В этом материале разработчик из Cloudflare рассказывает о создании настраиваемой библиотеки Rust для написания и исполнения Wireshark®-подобных фильтров
3К открытий4К показов

Рассказывает Ingvar Stepanyan, CloudFlare
В этой статье вы узнаете о создании настраиваемой библиотеки Rust для написания и исполнения Wireshark®-подобных фильтров в разных частях стека Cloudflare, написанных на Go, Lua, C, C++ и JavaScript.

Cloudflare открыли исходный код этой библиотеки в своём аккаунте GitHub. Этот пост погрузит вас в её разработку; объяснит, почему мы не использовали генератор парсеров; а также поможет понять как наш движок исполнения балансирует между безопасностью, производительностью и ценой компиляции для сгенерированных фильтров.
Парсинг синтаксиса Wireshark
При создании предметно-ориентированного языка (DSL — Domain Specific Language) первое, что нам нужно было сделать, это проанализировать его. Это дало бы промежуточное представление (обычно называемое абстрактным синтаксическим деревом), которое можно изучать, просматривать, анализировать и, возможно, сериализовывать.
Есть разные способы выполнить такой переход:
- ручной посимвольный парсинг, использующий стейт-машины, регулярные выражения или нативные строковые API;
- парсер-комбинаторы, которые используют высокоуровневые функции для объединения нескольких парсеров вместе (например, nom, chomp, combine и другие);
- полностью автоматизированные генераторы, которые, основываясь на грамматике, могут создавать полностью рабочий парсер (например, peg, pest, LALRPOP и др.).
Синтаксис Wireshark
Прежде чем пытаться выяснить, какой подход лучше всего подошёл бы для нас, давайте взглянем на несколько простых официальных примеров Wireshark, чтобы понять, с чем мы имеем дело:
ip.len le 1500udp contains 81:60:03sip.To contains “a1762”http.request.uri matches “gl=se$”eth.dst == ff:ff:ff:ff:ff:ffip.addr == 192.168.0.1ipv6.addr == ::1
В правой части выражения может быть число, адрес IPv4/IPv6, набор байтов или строка. Они все взаимозаменяемы без какого-либо особого представления о типе. Что хорошо, если учесть, что их легко отличить.
Давайте посмотрим на некоторые формы представления IPv6 в Википедии:
2001:0db8:0000:0000:0000:ff00:0042:83292001:db8:0:0:0:ff00:42:83292001:db8::ff00:42:8329
IPv6 может быть записан в виде набора до 8 шестнадцатеричных чисел, разделённых двоеточиями, каждое из которых содержит до 4 цифр с ведущими нулями, опущенными для удобства. Это очень похоже на последовательность байтов. Действительно, если вы попробуете выписать последовательность как 2f:31:32:33:34:35:36:37, с точки зрения синтаксиса Wireshark это будет одновременно и корректный IPv6, и байтовая последовательность.
Нельзя точно сказать, что на самом деле представляет эта последовательность, не глядя на область её использования. Если вы попытаетесь использовать эту последовательность в Wireshark, то заметите, что это так:
ipv6.addr == 2f:31:32:33:34:35:36:37— правая часть анализируется и используется как адрес IPv6http.request.uri == 2f:31:32:33:34:35:36:37— правая часть анализируется и используется как последовательность байтов (будет соответствовать URL"/1234567")
Есть и другие примеры таких коллизий. Например, вы можете попробовать использовать одно десятичное двухразрядное число:
tcp.port == 80— соответствует любому трафику на порту 80 (HTTP);http.file_data == 80— соответствует любому HTTP-запросу/ответу с телом, содержащим один байт (0x80)
Мы могли бы сделать то же самое с адресом в локальной сети, определённым как отдельный тип в Wireshark. Но для простоты представим его обычной последовательностью байтов в данной реализации, поэтому здесь не будет двусмысленности.
Выбор подхода к парсингу
Подход состоит в том, что необходимо сохранять соответствие между областью имён и областью типов заранее (назовём такой подход Scheme), и использовать это для контекстного парсинга. Это ограничение исключает множество (если не большинство) парсер-генераторов.
Мы могли бы по-прежнему использовать один из таких наиболее сложных генераторов (например, LALRPOP), который позволяет заменить лексику регулярных выражений вашим собственным пользовательским кодом. Но в данный момент мы так близки к полному анализатору DSL-языка, что эта сложность перевешивает любые преимущества использования малоизвестного парсер-генератора.
Вместо этого будем использовать ручной подход к парсингу. Это может показаться пугающим в небезопасных языках, таких как C/C++, но в Rust для всех строк по умолчанию выполняется проверка выхода за границы строки. Rust также предоставляет богатый API для работы со строками, который вы можете использовать для создания более сложных вспомогательных инструментов, в конечном итоге получая полный анализатор.
Этот подход, на самом деле, очень похож на парсер-комбинаторы в том, что парсер не сохраняет состояние, а только передаёт необработанную часть входных данных узконаправленным, специфичным функциям. Как и в парсер-комбинаторах, отсутствие состояния также позволяет легко тестировать и поддерживать каждый из парсеров для одних частей синтаксиса независимо от других. По сравнению с популярными библиотеками парсер-комбинаторов на Rust, одно из отличий состоит в том, что данные парсеры — это не автономные функции, а типы, которые реализуют общие черты:
Метод lex() или его контекстный вариант lex_with() может возвращать как успешную пару (экземпляр типа, остальная часть ввода), так и пару с ошбиками (вид ошибки, соответствующий диапазон ввода).

Особенность Lex() используется для целевых типов, которые могут быть проанализированы независимо от контекста (например, область имён или литералов), в то время как LexWith() используется для типов, которым требуется наш метод Scheme для однозначного анализа.
Ещё большее отличие состоит в том, что вместо использования высокоуровневых функций для парсер-комбинаторов используется обычный императивный синтаксис вызова функций. Например, когда мы хотим выполнить последовательный парсинг, всё, что мы делаем, это вызываем несколько парсеров подряд, используя деструктурирование кортежей для промежуточных результатов:
И, когда вы хотите попробовать другие альтернативные способы, вы можете использовать нативное сопоставление с шаблоном и игнорировать ошибки:
Наконец, когда вы хотите автоматизировать парсинг некоторых более сложных структур данных, например, перечислений (enum), Rust предоставляет мощный синтаксис макросов:
Это даёт результат аналогичный парсер-генераторам, но при этом всё ещё используется нативный синтаксис, что позволяет нам контролировать все детали реализации.
Движок исполнения
Поскольку наша грамматика и операции довольно просты, изначально мы использовали прямую интерпретацию AST так, чтобы все узлы реализовывали типаж, включающий метод execute.
ExecutionContext очень похож на Scheme, но вместо сопоставления произвольных имён с их типами, он сопоставляет их с выполняемыми входными значениями, предоставленными вызывающей стороной.
Как и в Scheme, первоначально ExecutionContext использовал внутренний HashMap для регистрации этих произвольных соответствий String → RhsValue. Во время выполняемого вызова реализация AST будет рекурсивно вычислять себя и искать все ссылки на отображение (объект, хранящий соответствие имён и типов), возвращая значение или выявляя ошибку на отсутствие слотов и несоответствия типов.
Этого было достаточно для первоначальной реализации, но использование HashMap имеет издержки, которые мы хотели бы устранить. Мы уже использовали более эффективный хэшер (Fnv) потому что все ключи под контролем и DoS-атаки на хэш не страшны, но мы всё ещё могли сделать больше.
Ускорение доступа к полям
Если посмотреть на задействованные структуры данных, то можно увидеть, что схема всегда чётко определена заранее. Ожидается, что все выполняемые значения в механизме в конечном итоге будут соответствовать этой схеме, даже если порядок или точный набор областей не гарантирован.
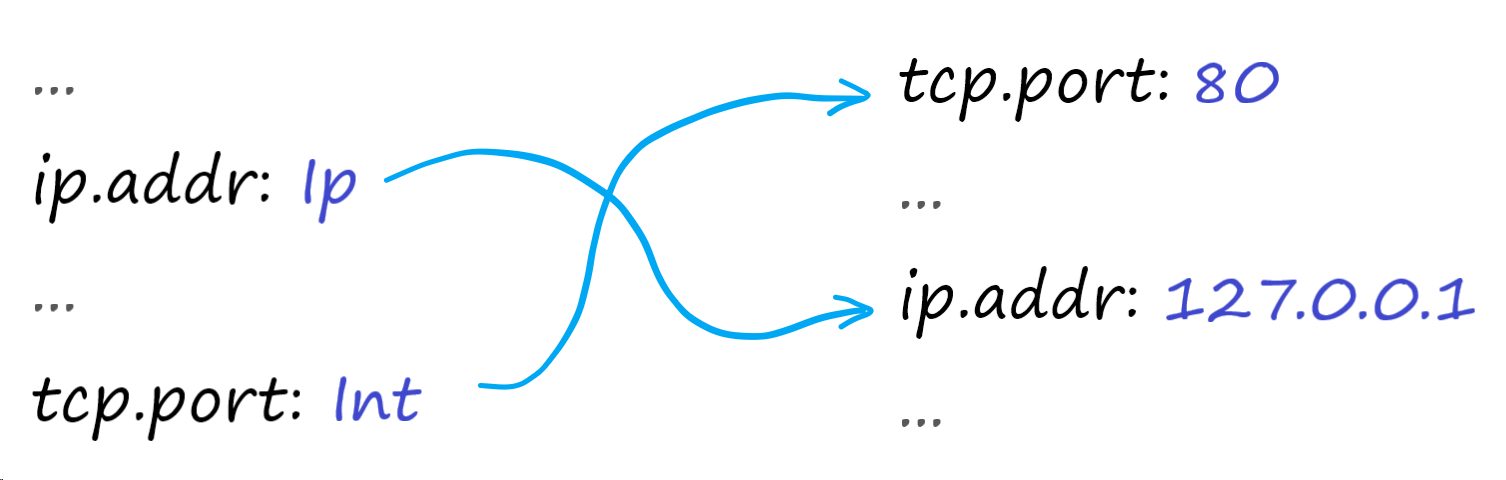
Что, если вообще отбросить второе отображение и вместо этого использовать массив значений фиксированного размера? Индексирование массива должно быть легче, чем поиск по мапу, который требует некоторых усилий.
Количество элементов уже известно (благодаря предопределённой схеме), поэтому можно определить размер резервного хранилища. Чтобы смоделировать дыры в HashMap для неустановленных значений, можно обернуть каждый элемент в Option<...>:
Единственный недостающий элемент — это индекс, который может отображать обе структуры друг на друга. Как вы, возможно, помните, в Scheme по-прежнему используется HashMap для регистрации полей, а HashMap обычно предполагается рандомизировать и индексировать только по предопределённому ключу.
С одной стороны мы могли бы объединить значение и автоинкрементный индекс вместе в простую структуру, но есть решение лучше: IndexMap. IndexMap — это заменитель HashMap, который сохраняет порядок и позволяет получить индекс любого элемента и наоборот — именно то, что нам нужно.
После замены HashMap на IndexMap мы можем изменить парсинг, чтобы распределить все проанализированные области имён по их индексам прямо на месте и сохранить их в AST:
После этого в ExecutionContext нужно выделить массив фиксированного размера и использовать эти индексы для распределения значений во время выполнения:
Это даёт значительный прирост производительности (почти двукратный).
До:
После:
Это делает наш API удобнее, поскольку любые ошибки типов теперь обнаруживаются гораздо раньше, когда значения просто устанавливаются в контексте, а не откладываются до выполнения фильтра.
[не] JIT-компиляция
Как и с любым другим языком, одной из идей было в какой-то момент добавить нативную компиляцию, чтобы сделать всё супер-быстрым. Но на практике нативная компиляция является сложной задачей, и даже не из-за нехватки инструментов.
Прежде всего, возникает вопрос хранения нативного кода. Можно статически скомпилировать каждый фильтр в своего рода отдельную библиотеку и записать в хранилище типа ключ-значение, но его будет нелегко поддерживать:
- необходимо скомпилировать каждый фильтр для нескольких платформ (x86-64, ARM, WASM,…);
- накладные расходы нативных библиотек значительно превысят полезный размер исполняемого файла, так как большинство фильтров маленькие;
- каждый раз, когда мы хотим изменить нашу логику выполнения, будь то её оптимизация или исправление ошибки, нам придется перекомпилировать и переиздавать все ранее сохранённые фильтры;
- даже если мы уверены в надёжности выбранного хранилища, выполнение динамически извлечённого нативного кода «как он есть» не является чем-то простым.
Гибкой альтернативой, которая решает большинство из этих проблем, является Just-in-Time-компиляция (JIT).
Когда вы компилируете код непосредственно на целевой машине, вы получаете возможность повторно перепроверить ввод (выраженный как ограниченный DSL). Вы можете скомпилировать его только для текущей платформы на месте и вам больше не нужно повторно публиковать актуальные правила.
Но не всё так идеально. Как и в случае с любой другой технологией, здесь есть компромиссы, и вы можете выбрать только те, которые больше подходят для ваших вариантов использования. JIT-компиляция — не исключение.
Даже если вы не загружаете ненадёжный код по сети, вам всё равно нужно сгенерировать его в память, пометить эту память как исполняемую и полагать, что она всегда будет содержать действительный код, а не мусор или что-то ещё хуже. В зависимости от вашего выбора библиотек и сложности DSL, вы, возможно, захотите довериться ему или поместить его в глубокую песочницу, но в любом случае это риск, который нужно принять.
Ещё одна проблема — затраты на саму компиляцию. Обычно при измерении скорости нативного кода по сравнению с интерпретацией затраты на компиляцию не учитываются, поскольку она происходит вне процесса.
С JIT-компиляторами всё по-другому, поскольку вы компилируете код в тот момент, когда он используется, и кэшируете нативный код только в течение ограниченного времени. Генерация нативного кода может быть довольно дорогой, поэтому вы должны быть абсолютно уверены что затраты на компиляцию не перевесят выгоду, полученную от ускорения нативного выполнения.
Есть кое-что ещё, что мы можем сделать, чтобы получить наилучший баланс между безопасностью, производительностью и затратами на компиляцию.
Динамическое связывание и замыкания
В Rust типажи Fn, FnMut и FnOnce автоматически реализуются для соответствующих функций и замыканий. В случае с Fn ограничение заключается в том, что они не должны изменять своё окружение, а только заимствовать его.
Обычно это используется в контексте обобщений (generics) для поддержки произвольных обратных вызовов с заданным аргументом и возвращаемыми типами. Это важно, потому что в Rust каждая функция и замыкание реализуют уникальный тип, и любое обобщённое использование будет компилироваться в прямой вызов именно этой функции.
Такое поведение называется ранним (статическим) связыванием и является стандартным в Rust. Оно будет предпочтительным по соображениям производительности.
Однако, если все возможные типы во время компиляции не известны, Rust позволяет вместо этого выбрать позднее (динамическое) связывание:
Динамически связываемые объекты не имеют статически известного размера, потому что он зависит от деталей реализации конкретного передаваемого типа. Они должны быть переданы по ссылки или сохранены в выделенной упаковке (Box) в “куче” (heap), а затем использованы точно так же, как в общей реализации.
В нашем случае это позволяет создавать, возвращать и хранить произвольные замыкания, а затем вызывать их как обычные функции:
Замыкание (упакованная Fn) также автоматически включает данные среды, необходимые для выполнения.

Это означает, что можно оптимизировать представление данных во время выполнения как часть процесса компиляции без изменения AST или парсера. Например, когда мы хотели оптимизировать проверки диапазона IP-адресов, разделяя их для разных типов IP-адресов, мы могли сделать это без изменения каких-либо существующих структур:
Упакованные замыкания могут быть частью захваченного окружения. Это означает, что можно преобразовать каждое простое сравнение в замыкание, а затем объединить его с другими замыканиями и продолжать до тех пор, пока не получится одно замыкание верхнего уровня, которое можно вызывать как обычную функцию для оценки всего выражения.
Плюсы такого подхода:
- Выполнение больше не привязано к AST. И можно быть настолько гибкими с оптимизацией и представлением данных, насколько захотите, не затрагивая связанные с парсером части кода.
- Несмотря на то, что каждый узел изначально компилируется в отдельное замыкание, в будущем возможно довольно легко сужать определённые комбинации выражений в их собственных замыканиях и, таким образом, повысить скорость выполнения для обычных случаев. Потребуется только отдельная ветка match, возвращающая замыкание, оптимизированное только для этого случая.
- Компиляция малозатратна по сравнению с генерацией реального кода. Хотя может показаться, что выделение множества небольших объектов (одно упакованное замыкание на одно выражение) не очень эффективно и что было бы лучше заменить его каким-либо пулом памяти. На практике влияние на производительность получилось незначительным.
- Во время выполнения нативный код не генерируется. Это означает, что выполняется только тот код, который был статически проверен Rust во время компиляции и скомпилирован в статическую функцию. Всё, что мы делаем во время выполнения — это вызываем существующие функции с разными значениями.
- Выполнение происходит быстрее. Это стало неожиданностью, поскольку есть мнение, что динамическое связывание является затратным, и она должна была проявить себя хуже, чем интерпретация AST. Практика показала немедленное улучшение времени выполнения на ~ 10-15 % в тестах и на реальных примерах.
Единственным очевидным недостатком является то, что каждый уровень AST требует отдельного динамически связываемого вызова вместо единого встраиваемого (inlined) кода для всего выражения. Это можно сделать даже с базовым шаблонным JIT.
К сожалению, такой вывод может быть достигнут только при реальной генерации нативного кода. В нашем случае упомянутые недостатки и риски перевесят преимущества времени выполнения. Поэтому выбор пал на безопасный и гибкий подход, а именно замыкания.
Бонус: поддержка WebAssembly
Мы выбрали Rust в качестве безопасного языка высокого уровня, который позволяет легко интегрироваться с другими частями нашего стека, написанными на Go, C и Lua через C FFI. Но у Rust есть ещё одно применение, с которым он справляется особенно хорошо: WebAssembly.
Кроме частей стека, где выполняются правила, и API, который их публикует, также есть пользователи, которым нравится писать свои собственные правила. Для этого они используют UI-редактор (графический редактор), который позволяет либо писать сырые выражения в синтаксисе Wireshark, либо в качестве компоновщика WYSIWYG.
WebAssembly может быть намечена через обычную C FFI, но в этом случае вам нужно будет вручную предоставить для JavaScript всё “склеивание”, чтобы хранить и преобразовывать строки, массивы и объекты.
В Rust всем этим занимается wasm-bindgen. Он предоставляет различные атрибуты и методы для прямых преобразований. Самый простой способ — активировать опцию serde, которая автоматически преобразует типы с использованием JSON.parse(), JSON.stringify() и serde_json.
В данном случае создания оболочки для парсера всего с 20 строками кода было достаточно, чтобы начать работу и иметь весь необходимый код WASM + прослойку JavaScript:
А благодаря wasm-pack, инструменту более высокого уровня, мы также получили автоматическую генерацию npm-пакетов и публикацию без каких-либо затрат.
Изложенное в этом посте ещё не используется в production, потому что всё ещё нужно выяснить некоторые нюансы для неподдерживаемых браузеров. Также должна быть возможность запускать фильтры в Cloudflare Workers путём расширения и повторного использования одного и того же пакета (которые также поддерживают WebAssembly). Но код в текущем состоянии уже хорошо выполняет свою работу и мы рады поделиться им с сообществом открытого кода Rust.
Познакомиться с полной историей синтаксического анализа вы можете здесь.

3К открытий4К показов

Хакеры пишут вирусы на Haskell, Delphi и Rust — такие вредоносы труднее анализировать и обнаружить традиционным антивирусам

Гайд по Rust. Показываем, что нужно знать, чтобы научиться языку программирования Раст. Рассматриваем пошаговую инструкцию и практические примеры ✔ Tproger

Узнайте, сколько CO₂ генерирует ваш код в 2025 году и как снизить углеродный след в IT. Практические советы по оптимизации архитектуры, выбору «зеленых» технологий и реальные кейсы компаний. Экологичное программирование — новый тренд для разработчиков и бизнеса.

Список разбит по категориям: от браузеров и гейминга до утилит безопасности и инструментов для продуктивности.