


Исследование утечек памяти в Go с помощью pprof

В Go непросто получить полный дамп памяти, из-за чего сложно найти утечки. Рассмотрим, как это сделать с помощью pprof на примере реального проекта.
33К открытий40К показов
Я работал с Go достаточно долго, внедряя масштабируемую блокчейн-инфраструктуру в Orbs. Мы выбрали Go из-за развитого сообщества и отличного набора инструментов.
На последних стадиях разработки могут возникнуть проблемы, связанные с производительностью, в частности утечки памяти. Мы нашли такую и в нашей системе. В этой статье я расскажу, как исследовать утечку памяти в Go, описав шаги, которые мы предприняли для её поиска.
Набор инструментов Golang имеет свои ограничения, и самое большое из них — невозможность исследовать полные дампы памяти. Полный дамп памяти — это содержимое памяти, занятое процессом, выполняющим программу.
Отображение памяти можно представить в виде дерева. Проход по этому дереву проведёт вас через различные размещения объектов в памяти. Всё, что находится в корне дерева, удерживает память от очистки сборщиком мусора. В Go нет простого способа проанализировать дамп, поэтому сложно добраться до корней объекта, который не очищается как мусор.
На момент написания статьи в Интернете не удалось найти какой-либо способ, который помог бы найти корневой объект, препятствующий освобождению памяти. Поскольку у дампов памяти существует формат, и есть достаточно простой способ экспортировать его из отладочного пакета, вероятно, есть хотя бы один подобный инструмент, который используется в Google. Судя по тому, что можно найти в сети, для Go планируется разработать инструмент для просмотра дампов памяти, но не похоже, чтобы кто-то над этим работал.
Утечки памяти
Утечки памяти (или давление памяти) могут принимать разные формы. Обычно мы считаем их багами, но истинная причина возникновения может крыться ещё на стадии проектирования.
Важно построить систему таким образом, чтобы избежать преждевременных оптимизаций и позволить выполнять их позже по мере развития кода, а не перегружать его с самого начала. Некоторые распространённые примеры возникновения проблем с памятью:
- слишком большое количество выделений памяти, неверное представление данных;
- интенсивное использование рефлексии или строк;
- использование глобальных переменных;
- «осиротевшие», бесконечные горутины.
Самый простой способ создать утечку памяти в Go — определить глобальную переменную, массив, и добавить в него данные.
Golang предлагает инструмент с именем pprof. Он может помочь обнаружить проблемы с памятью. Он также может быть использован при обнаружении проблем в работе процессора.
pprof создаёт файл дампа, в который кладёт сэмпл кучи. Этот файл можно потом проанализировать/визуализировать, чтобы получить карту:
- текущего выделения памяти;
- общего (накопительного) выделения памяти.
У инструмента есть возможность сравнивать снимки, сделанные в разное время. Это может быть полезно при стрессовых сценариях для определения проблемных областей кода.
Профили pprof
pprof работает с использованием профилей.
Профиль — это набор трассировок стека, показывающих последовательности вызовов, которые привели к появлению определённого события, например к выделению памяти.
Файл runtime/pprof/pprof.go содержит подробную информацию и реализацию профилей.
Go имеет несколько встроенных профилей, которые можно использовать в обычных случаях:
goroutine— следы всех текущих горутин;heap— выборка выделений памяти живых объектов;allocs— выборка всех прошлых выделений памяти;threadcreate— следы стека, которые привели к созданию новых потоков в операционной системе;block— следы стека, которые привели к блокировке примитивов синхронизации;mutex— следы стека держателей конфликтующих мьютексов.
Профиль allocs идентичен heap в отношении сбора данных. Разница заключается в том, как pprof читает во время запуска. Allocs запустит pprof в режиме, который отображает общее количество байтов, выделенных с момента запуска программы (включая байты, являющиеся мусором). Нам нужно знать выделение памяти по каждому объекту отдельно, поэтому сосредоточимся на профиле heap.
Heap
Heap (куча) — это абстрактное представление места, где операционная система хранит объекты, которые использует код. Впоследствии эта память очищается сборщиком мусора или освобождается вручную в языках программирования без сборки мусора.
Куча — не единственное место, где происходит выделение памяти. Часть также выделяется на стеке. Его цель — быстрый доступ к памяти. В Go стек обычно используется для присвоений, которые происходят в рамках функции. Другой момент, где Go использует стек, — когда компилятор «знает», сколько памяти необходимо зарезервировать перед выполнением (например для массивов фиксированного размера).
Данные кучи должны быть освобождены с использованием сборки мусора, в то время как данные стека — нет. Поэтому гораздо эффективнее использовать стек там, где это возможно.
Получение данных кучи с помощью pprof
Есть два основных способа полученить данные. Первый обычно используют в качестве части теста, и он включает импорт runtime/pprof и затем вызов pprof.WriteHeapProfile(some_file) для записи информации в кучу.
WriteHeapProfile() существует для обратной совместимости. Остальные профили не имеют таких возможностей, и вы должны использовать функцию Lookup(), чтобы получить данные профилей.
Второй, более интересный способ — пустить его через HTTP (по веб-адресу). Это позволит извлекать конкретные данные из запущенного контейнера в тестовой или e2e-среде или даже из продакшна. Всю документацию пакета pprof можно не читать, но как его включить, следует знать.
«Побочным эффектом» импорта net/http/pprof является регистрация конечных адресов на веб-сервере в корневом каталоге /debug/pprof. Используя curl, можно получить файлы с информацией для анализа.
Добавление http.ListenAndServe() в примере выше требуется только в случае, если ваша программа ранее не имела прослушивателя HTTP-сервера. Существуют также способы настроить его с помощью ServeMux.HandleFunc(), который понятнее для более сложной программы с поддержкой HTTP.
Использование pprof
Есть две основные стратегии анализа памяти с помощью pprof. Одна из них называется inuse и заключается в рассмотрении текущих выделений памяти (байтов или количества объектов). Другая носит название alloc и заключается в просматривании всех выделенных байтов или количества объектов во время выполнения программы.
Профиль heap является выборкой выделения памяти. «За кулисами» pprof использует функцию runtime.MemProfile(), которая по умолчанию собирает информацию о предоставлении памяти на каждые 512 КБ выделенных байтов. Можно изменить MemProfile() для сбора информации обо всех объектах, но скорее всего это замедлит работу приложения.
Как только файл профиля собран, пришло время загрузить его в интерактивную консоль pprof.
Посмотрим на отображаемую информацию:
Здесь важно отметить Type: inuse_space. Мы смотрим на данные выделения памяти в определённый момент (когда мы захватили профиль). Тип является значением конфигурации sample_index, а возможными значениями могут быть:
inuse_space— объём выделенной и ещё не освобождённой памяти;inuse_object s— количество выделенных и ещё не освобождённых объектов;alloc_space— общий объём выделенной памяти (независимо от освобождённой);alloc_objects— общее количество выделенных объектов (независимо от освобождённых).
Теперь введите top в интерактивной консоли, и на выводе будут главные потребители памяти.
Можно увидеть строку, показывающую Dropped Nodes (сброшенные узлы). Узел — это выделение объекта или «узел» в дереве. Удаление узлов — хорошая идея, чтобы уменьшить количество мусора, но иногда это может скрывать основную причину утечек памяти.
Если хотите включить все данные профиля, добавьте опцию -nodefraction=0 при запуске pprof или введите nodefraction=0 в интерактивной консоли.
В выводимом списке можно увидеть два значения — flat и cum.
flatозначает, что память выделена функцией и удерживается ей;cumозначает, что память выделена функцией или функцией, которая была вызвана стеком.
Этой информации может быть достаточно, чтобы понять, есть ли проблема. Например, функция отвечает за выделение большого объёма памяти, но не удерживает её. Это значит, что какой-то другой объект указывает на эту память и удерживает её, то есть может возникнуть утечка памяти или баг.
Команда top в интерактивной консоли по умолчанию выводит первые 10 позиций потребителей памяти. Но эта команда поддерживает формат topN, где N — количество записей, которые вы хотите увидеть. Например, при наборе top70, будут выведены все узлы.
Графическое представление потоков выделения памяти
Команда topN предоставляет текстовый список, но есть несколько полезных опций для визуального представления, которые есть в pprof. Можно использовать .png или .gif и многое другое (полный список можно увидеть по команде go tool pprof -help).
В нашей системе визуализация по умолчанию выглядит примерно так:
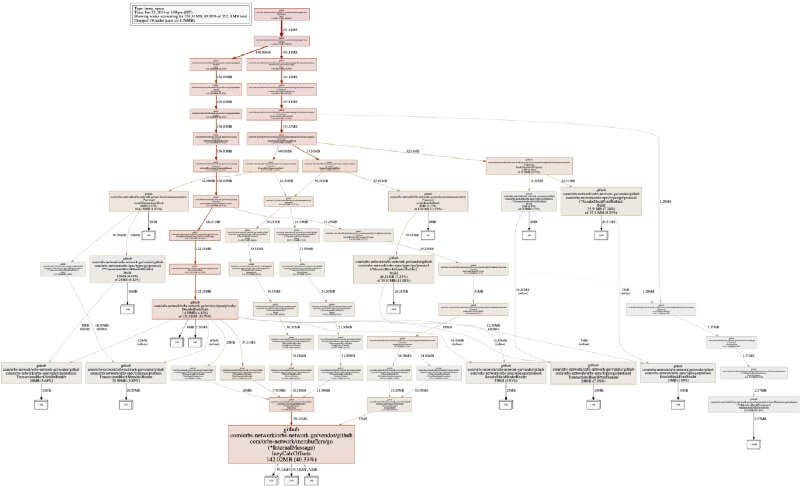
Это визуализация потоков выделения памяти в программе согласно трассировкам стека. Прочитать график не так сложно, как кажется. Белый квадрат с номером показывает выделенное пространство и совокупный объём памяти, который он занимает прямо сейчас. А каждый более широкий прямоугольник показывает выделившую память функцию.
Стоит отметить, что png-изображение выше было снято в режиме inuse_space. Ещё обратите внимание на inuse_objects, это также может помочь в поиске проблем с выделением.
Копаем глубже, чтобы найти первопричину
В нашем случае membuffers (библиотека сериализации данных) удерживает память. Но это не значит, что обязательно есть утечка в сегменте кода. Это значит, что память удерживается функцией. Важно понимать, как читать граф и вывод pprof в целом. В случае сериализации данных выделяется память для структур и примитивных объектов (int, string) и никогда не освобождается.
Неверно истолковав график, можно предположить, что один из узлов на пути к сериализации отвечает за сохранение памяти, например:
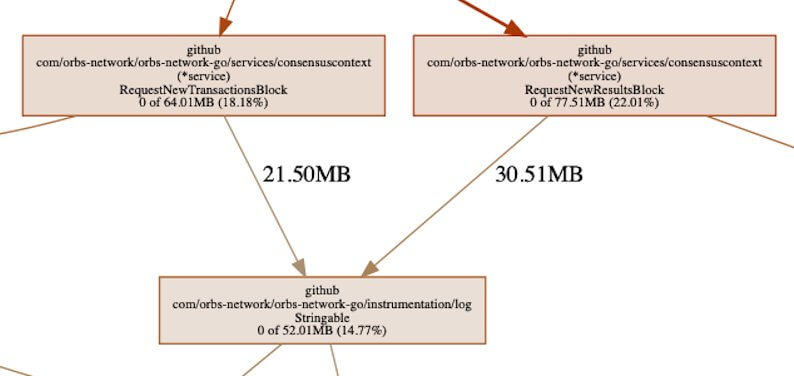
Где-то в цепочке можно увидеть библиотеку логирования, занимающую > 50 Мб выделенной памяти. Это память, которая выделяется функциями. Логгер в процессе своей работы вызывает выделение памяти, поскольку ему необходимо сериализовать данные для вывода их в журнал.
Из графа также видно, что память удерживается только сериализацией и больше ничем. Объём памяти самого логгера составляет около 30 % от общего объёма. Это значит, что проблема не в писателе. Он регистрирует что-то, чего не должно быть. А значит, утечка памяти не в журнале логов.
Знакомьтесь с командой list. Она принимает регулярное выражение, которое будет фильтровать то, что надо отобразить. Список (list) в действительности представляет собой исходный код с комментариями, относящийся к выделению. В контексте изучаемого логгера выполним list RequestNew, чтобы увидеть вызовы, сделанные в регистраторе. Эти вызовы поступают из двух функций, которые начинаются с одного и того же префикса.
Выделения памяти находятся в столбце cum. Это значит, что выделенная память сохраняется в стеке вызовов. Это соответствует тому, что показывает график. Причина выделения памяти писателем заключается в том, что мы отправили ему весь «блокирующий» объект. Нужно было как минимум сериализовать некоторые его части.
List может найти исходный код, если искать его в среде GOPATH. В случаях, когда корневой объект не совпадает (зависит от вашего сборщика), вы можете использовать опцию -trim_path. Она поможет исправить код и позволит увидеть аннотированный исходный код. Не забудьте установить свой Git на правильный коммит, который работал во время захвата профиля heap.
Так почему память удерживается?
В случае с Java или .Net можно использовать какой-нибудь анализатор корневых объектов и добраться до объекта, который создаёт утечку. Но с Go это невозможно из-за проблем со встроенными инструментами и из-за низкоуровневого представления памяти.
Не вдаваясь в детали, мы не думаем, что Go запоминает, какой объект по какому адресу хранится (за исключением, возможно, указателей). Для понимания, по какому адресу памяти хранится член объекта (структуры), потребуется карта вывода из профиля heap. Значит, перед захватом полного дампа ядра следует также захватить профиль heap, чтобы адреса могли быть сопоставлены с выделившими память строкой и файлом, а следовательно и объектом, представленным в памяти.
Установив значение nodefraction=0, можно увидеть всю карту выделенных объектов, включая самые маленькие.
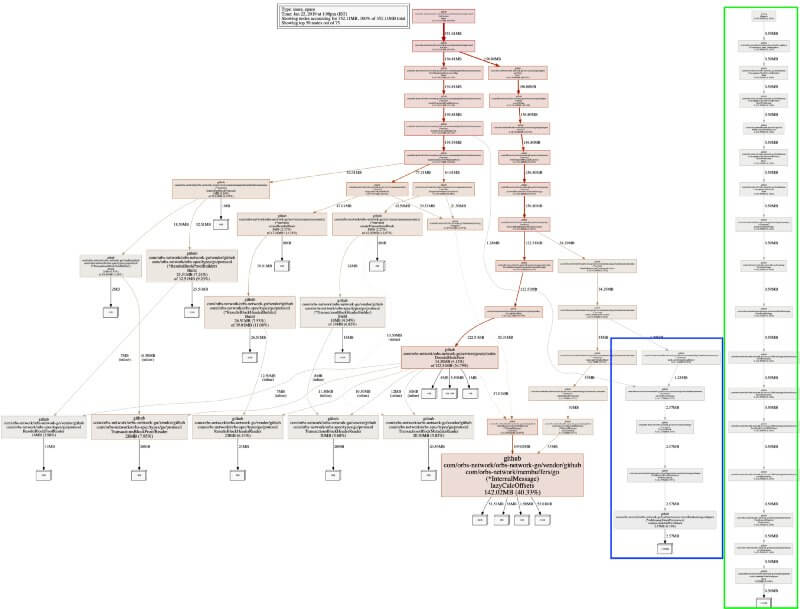
У нас есть два новых поддерева. Более длинное новое дерево зеленого цвета, которое полностью отсоединено от остальной системы, является тестовым прогоном, оно нам не интересно.

Небольшое поддерево синего цвета, соединённое ребром со всей системой, — это inMemoryBlockPersistance. Это бэкенд, который хранит все данные в памяти, но не сохраняет их на диске. Можно сразу увидеть, что в нём находятся два больших объекта. Два — потому что размер объекта составляет 1,28 Мб, а функция сохраняет 2,57 Мб, то есть в два раза больше.
Теперь проблема отчётливо ясна. Можно использовать отладчик и увидеть, что всему виной массив, который удерживает все блоки для постоянства памяти.
Что можно исправить?
Десериализованные данные занимали слишком много памяти. Откуда взялось 142 Мб для чего-то, что должно занимать существенно меньше памяти? Здесь может помочь pprof — он существует именно для того, чтобы точно отвечать на такие вопросы.
Чтобы просмотреть исходный код функции, запустим lazyCalcOffsets(). Теперь можем увидеть, что flat и cum одинаковы. Это указывает на то, что выделенная память также сохраняется этими точками выделения. Функция make() тоже занимает немного памяти, т. к. это указатель на структуру данных. Ещё можно увидеть, что занимает память выделение в строке 43.
Следует отметить, что функция make() в Go позволяет делать не только отображения, но и срезы. Присвоение отображению не то же самое, что присвоение простой переменной — использование переменных предполагает большие издержки ресурсов. Чем больше элементов, тем больше будут эти издержки по сравнению со срезом.
При использовании map[int]T когда данные не редки или могут быть преобразованы в последовательные индексы и потребление памяти является важным фактором, для большей эффективности следует использовать срез. Однако большой срез при расширении данных может замедлить операцию, в то время как для отображения это замедление будет незначительным. Как вы уже поняли, не существует волшебной формулы для оптимизации.
В нашей системе мы теперь используем срез вместо отображения. Из-за способа получения данных и того, как мы получаем к ним доступ, кроме пары строк и структуры данных, никаких других изменений кода не потребовалось. Посмотрим, как это повлияло на потребление памяти.
Взглянем на benchcmp для пары тестов.
Тесты на чтение инициализируют структуру данных, которая создаёт выделения. Время выполнения улучшилось на ~30 %, выделение сократилось на 50 %, а потребление памяти > 90 %.
Поскольку отображение (теперь уже срез) никогда не было заполнено большим количеством элементов, цифры показывают то, что мы увидим в продакшене. Результат зависит от энтропии данных, но могут быть случаи, когда улучшение как выделения, так и потребления памяти было бы ещё больше.
Ещё раз задействовав pprof и захватив профиль heap из того же теста, можно увидеть, что теперь потребление памяти фактически сократилось на ~90 %.

Вывод прост — для небольших наборов данных не следует использовать отображения, достаточно срезов. Отображения имеют большие издержки.
Полный дамп памяти
Именно здесь можно наблюдать самое большое ограничение инструментов Go. Этот язык развивается большими темпами, но это развитие имеет свою цену в случае полного дампа и выделения памяти. Формат полного дампа кучи по мере своих обновлений является обратно не совместимым. Помните это, когда будете использовать последнюю версию. Для записи полного дампа кучи вы можете использовать debug.WriteHeapDump().
Следует также отметить, что не существует хорошего решения для изучения полных дампов. Вот некоторые вещи, которые стоит игнорировать, если собираетесь попробовать открыть полный дамп самостоятельно, начиная с Go 1.11:
- В macOS нет способа открыть и отладить полный дамп ядра, это работает только в Linux.
- Инструменты в этом репозитории предназначены для Go 1.3. Существует форк для 1.7+, но он также не работает должным образом (не полностью).
- ViewCore из репозитория Go на самом деле не компилируется. Это достаточно легко исправить, указав внутренние пакеты на golang.org вместо github.com. Но это также не работает на macOS и может быть работает на Linux.
- Также corelib не работает на macOS.
Ещё одна важная деталь о pprof — это его интерфейс. Он может сэкономить много времени при исследовании проблем профилей, созданных с помощью pprof.

33К открытий40К показов

В этой серии статей Олег Филон, ментор Эйч Навыки, рассказывает, как прийти к крутому CI/CD пайплайну. Сегодня разбираемся, как работать с пайплайнами и хуками в Git.

Go запустили на PlayStation 2: энтузиаст адаптировал TinyGo и ps2dev для MIPS-процессора консоли и обошёл ограничения LLVMa

Valkey обогнал Redis: до +37% в SET и −60% по задержкам в GET — Amazon помог форку выжать максимум из многопоточности и сетевых оптимизаций

Как компаниям эффективно хранить и масштабировать big data? Разбираем решения с экспертом VK Cloud.