


Python RegEx: практическое применение регулярок

Разберём регулярные выражения в Python, их синтаксис, популярные методы специального модуля re, а также попрактикуемся на задачах.
1М открытий2М показов
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
Основы регулярных выражений
Регулярками в Python называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
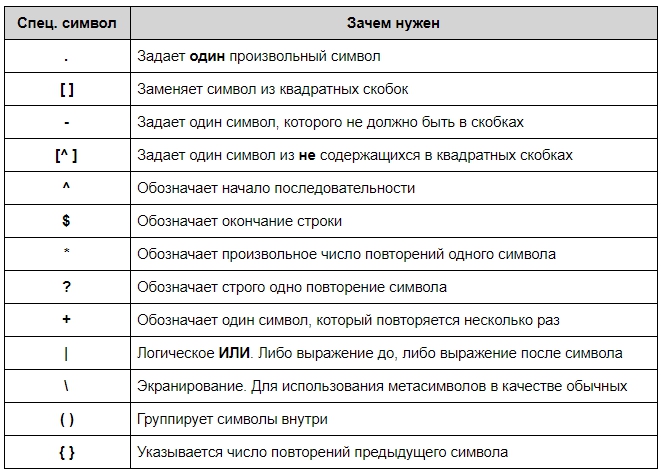
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
- \d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- \D — исключает все цифры и заменяет [^0-9];
- \w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- \W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- \s — соответствует любому пробельному символу;
- \S — описывает любой непробельный символ.
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
Регулярные выражения в Python
В Python для работы с регулярками есть модуль re. Его нужно просто импортировать:
А вот наиболее популярные методы, которые предоставляет модуль:
re.match()re.search()re.findall()re.split()re.sub()re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
Теперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None:
Также есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match(), но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
Метод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall(), так как он может работать и как re.search(), и как re.match().
re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
re.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:

Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .)
Для того, чтобы в конечный результат не попал пробел, используем вместо . \w.
Теперь попробуем достать каждое слово (используя * или +)
И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем +:
Теперь вытащим первое слово, используя ^:
Если мы используем $ вместо ^, то мы получим последнее слово, а не первое:
Вернуть первые два символа каждого слова
Вариант 1: используя \w, вытащить два последовательных символа, кроме пробельных, из каждого слова:
Вариант 2: вытащить два последовательных символа, используя символ границы слова (\b):
Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
Второй вариант — вытащить только домен верхнего уровня, используя группировку — ( ):
Извлечь дату из строки
Используем \d для извлечения цифр.
Для извлечения только года нам опять помогут скобки:
Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
А теперь — только те, которые начинаются на определенные буквы (используя []):
Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем \b для обозначения границы слова:
Также мы можем использовать ^ внутри квадратных скобок для инвертирования группы:
В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
Разбить строку по нескольким разделителям
Возможное решение:
Также мы можем использовать метод re.sub() для замены всех разделителей пробелами:
Извлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между <td> и </td>, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.
Пример содержимого html-файла:
С помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную test_str):

1М открытий2М показов
Есть поговорка, что разработчики трудятся по принципу «работает, не трогай», но откуда тогда появляются прорывные решения? Рассмотрим, как создаются быстрые и конкурентоспособные ИТ-продукты на реальных кейсах: обсудим ИИ-ассистентов, разговоры с Пушкиным (как в «Черном зеркале») и конечно затронем тему найма разработчиков.

Спрос на инженеров данных растет, и магистратура — лучший способ освоить профессию. Читайте, как программы Нетологии и НИУ ВШЭ готовят специалистов для работы с данными и что нужно для поступления в 2025 году.

Лучшие онлайн-курсы C++ и C#. Список школ, осуществляющих обучение на бесплатной или платной основе, а также цены на курсы по языкам программирования C++ и C#

Микросервисы — это не всегда решение. Эксперт разобрал главные минусы: хаос в архитектуре, рост затрат, сложная отладка и непредсказуемость системы