


Самоизменяющаяся программа на C под x86_64

10К открытий10К показов

Зачем вообще может понадобиться писать программу, которая меняет свой код во время выполнения? Это ужасно!
Да, да, я знаю. И все-таки, зачем? Ну, например, это хороший учебный пример. Но главная причина — потому что могу.
Самоизменяющиеся программы сами по себе не очень полезны. Они сложны в отладке, платформо-зависимы, код ужасно нечитаем, если вы, конечно, не эксперт в ассемблере. Единственное хорошее применение им — скрытие вредоносного кода. Но мой интерес чисто академический, поэтому ничего такого тут не будет.
Дисклеймер: в этой статье очень много ассемблерного кода под x86_64, в котором я не эксперт. Многому я научился в процессе написания статьи, поэтому возможно (почти наверняка) в тексте есть ошибки. Если вы найдете ошибку, пришлите мне е-мейл, чтобы я мог ее исправить.
Первый шаг к написанию самоизменяющейся программы — получение возможности изменять код во время выполнения. Когда-то давно программисты поняли, что это плохая идея и с тех пор добавили защиту на изменение выполняемого кода. Для начала разберемся, где хранятся инструкции, когда программа выполняется. Перед выполнением загрузчик помещает всю программу целиком в память. Затем программа запускается в виртуальном адресном пространстве, управляемом ядром ОС. Адресное пространство разбито на различные области, как показано на рисунке.

В нашем случае, нас интересует только область инструкций (text segment). Именно туда загружаются команды процессора. Адресное пространство размечено на страницы, которыми и управляет ядро. Страницы соответствуют физической памяти компьютера. Ядро также управляет правами доступа к страницам. По умолчанию область инструкций можно читать и выполнять оттуда команды. Писать в нее нельзя. Для того, чтобы изменять инструкции в этой области памяти, мы должны изменить права доступа.
Изменить права доступа можно функцией mprotect() (man mprotect). Единственная сложность в том, что указатель, передаваемый в функцию, должен быть выровнен по началу страницы памяти. Вот функция, которая по данному ей указателю находит адрес начала страницы и устанавливает права на чтение, запись и выполнение на ней.
Теперь, если мы передадим функции указатель, она сделает страницу памяти с этим адресом перезаписываемой. Важно заметить, что некоторые ОС могут отказаться устанавливать права доступа на запись в область инструкций. Я использую Linux, который позволяет сделать это. Если вы используете другую систему, убедитесь, что проверяете значение, возвращенное mprotect(). В примера дальше по тексту предполагается, что код, который мы будем менять, находится целиком на одной странице памяти. Для длинных участков кода это может не сработать.
Итак, мы можем писать в область инструкций. Следующий вопрос — что мы будет туда записывать?
Давайте начнем с простого. Допусти, у меня есть такая функция:
foo() создает локальную переменную i и присваивает ей значение 0, затем инкрементирует это значение и выводит в stdout. Посмотрим, сможем ли мы поменять число, которое прибавляется к i.
Для того, чтобы это сделать, нам надо посмотреть не только инструкции, которые сгенерирует компилятор для foo(), но и машинный код. Давайте напишем полную программу с использованием foo():
Теперь, когда у нас есть программа, использующая foo(), мы можем ее скомпилировать.
И вот тут начинается самое интересное. Нам надо дизассемблировать бинарник, созданный gcc и посмотреть, какие инструкции соответствуют foo(). Мы можем это сделать с помощью утилиты objdump.
Если вы откроете файл foo.dis в текстовом редакторе, примерно на 128 строке (в зависимости от версии компилятора, foo() может быть собрана с помощью разных инструкций) вы увидите дизассемблированную функцию foo(). Выглядит она примерно так:
Если вы раньше не сталкивались с ассемблерным кодом под x86_64, вы можете потеряться. Вот что здесь происходит: мы смещаем стек на 4 байта (размер int на моей машине) для того, чтобы освободить место для переменной i. Затем инициализируем эти 4 байта нулями и прибавляем 1 к этому значению. Все, что после адреса 40054b — это подготовка к вызову функции printf().
Итак, если мы хотим изменить число, прибавляемое к i, надо поменять вот эту инструкцию:
Прежде чем продолжать, давайте посмотрим, из чего состоит инструкция.

Рассмотрим саму инструкцию и ее операнды:

Теперь, когда мы разобрали человекочитаемую форму записи инструкции, давайте посмотрим на машинный код. Все инструкции для x86_64 имеют следующий формат:

Здесь возникают сложности. Дело в том, что инструкции для x86_64 могут иметь переменную длину, их разбор вручную сложен и занимает много времени. Задачу облегчают различные источники документации. На x86ref.net есть отличная документация. Для смелых есть также документация Intel в виде PDF на 3000 страниц.
В нашем случае эти байты означают следующее:

В документации есть полезная таблица, в которой объясняется значение каждого ModR/M байта. Также эта таблица есть в руководстве, упомянутом выше, таблица 2-2 в разделе 2-5 тома 2A (455 страница PDF-файла).
Теперь мы знаем какой байт в какой инструкции небходимо поменять, осталось понять, как это сделать.
Итак, мы хотим поменять байт 01 в инструкции addl $0x1,-0x4(%rbp).
Для этого нам нужно знать адрес этого байта. Мы можем без затруднений найти адрес начала функции, так что нам нужно знать только смещение. Есть два способа это сделать:
- Посмотреть на дизассемблированный код и посчитать число байт между началом функции и интересующим байтом.
- Написать функцию, которая последовательно напечатает инструкции
foo()со смещением относительно начала функции
Почему бы не сделать и то, и другое?
Посмотрим сначала на дизассемблированную функцию:
Функция начинается с адреса 400538, а байт, который нас интересует — на 400550 (400547 + 3), следовательно, смещение будет равно 400550 – 400538 = 18.
Можно убедиться в этом, написав короткую процедуру, которая выводит на экран инструкции для данной функции. Вот слегка измененная программа:
Заметьте, что для того, чтобы определить длину функции foo(), я добавил пустую функцию bar() после foo(). Теперь, когда сразу после foo() расположена bar(), мы можем определить длину foo() вычитанием адреса bar() из адреса foo().
Вот что выводит эта программа:
Наш байт 0x1 расположен по адресу 0x40057e. Можем убедиться, что смещение действительно 18.
Примечание переводчика: На текущей версии gcc этот код требует для компиляции специальных опций. Поскольку в редакции использовалась система, отличная от той, что у автора статьи, мы приводим код, который работает у нас: http://ideone.com/Ufvzba
Теперь все готово для изменения кода во время выполнения. Имея указатель на foo() мы можем получить указатель типа unsigned char на байт, которым хотим поменять.
Если мы все сделали правильно, эта строка поменяет аргумент команды addl на 0x2A или 42. Теперь, когда мы вызовем foo(), она напечатает 42 вместо 1.
Теперь соберем все вместе:
Скомпилируем это:
И запустим:
Ура! Первый вызов foo() выводит 1, как и указано в коде. Затем, после того, как мы его изменили, она выводит 42.
Теперь у нас есть самоизменяющаяся программа! Однако, она довольно скучная. Все что мы сделали — поменяли 1 на 42. Было бы круто, если бы мы смогли заставить foo() делать что-то совсем другое. Например вызывать шелл код с помощью exec().
Итак, как мы можем заставить foo() вызывать шелл код? Самый простой способ — использовать системный вызов execve. Но это уже сложнее, чем просто замена байта.
Если мы хотим подменить foo() системным вызовом, нам потребуются код для этого вызова. К счастью для нас, специалисты по безопасности любят использовать машинный код для запуска шелла, так что мы може этим воспользоваться. Поиск по «x86_64 shellcode» дал вот такой результат:
Я взял этот код отсюда и немного изменил:
- Я добавил
xor %rax, %raxдля того, чтобы обнулить%rax. Иначе он мог вызвать сегфолт. - Я заменил значение
$0x68732f6e69622f2fна$0x68732f6e69622f00. Таким образом я избавился от сдвига и сохранил размер кода в пределах 30 байт. Обычно шелл код вроде этого инжектируется через переполнение буфера или другими способами атаки. Строки в C заканчиваются нулевым байтом. Поэтому большинство функций для работы со строками из стандартной библиотеки возвращают результат когда встречают нулевой байт. Специалисты по безопасности избегают использования нуль-терминатора по этой причине, но в нашем случае в этом нет ничего страшного, поэтому мы заменяем0x2fна0x00и избавляемся от команды сдвига. См. оригинал кода по ссылке.
Прежде чем продолжать, давайте разберемся, как работает вышеприведенный код. Сначала рассмотрим системный вызов. Системный вызов — это вызов функции ядра ОС с запросом о каком-либо действии. Это может быть что-то, на что есть права доступа только у ядра, поэтому мы к нему и обращаемся. В нашем случае системный вызов execve говорит ядру, что мы хотим запустить другой процесс и заменить адресное пространства нашего процесса адресным пространством нового. Это значит, что при успешном вызове execve наш процесс завершится.
Для того, чтобы вызвать системную функцию на x86_64, нам необходимо его подготовить, поместив в правильные регистры определенные значения, а затем, собственно, вызвать системную функцию. Значения и регистры зависят от конкретной системы. Я пишу под Linux, поэтому привожу документацию для execve в Linux.

Важно помнить, что в регистрах должны быть указатели на реальные значения в памяти. Это значит, что мы должны положить корректные значения в стек, а затем поместить их адреса в стеке в регистры. Самое время сказать, что скучаешь по простоте указателей в C.
Полный список системных вызовов можно найти здесь.
Если вы знакомы с прототипом execve() в C (я привел его ниже для справки), вы заметите, насколько системный вызов в C похож на вызов функции.
Стоит также заметить, что вызов системной процедуры отличается в x86 и x86_64. Отдельной инструкции для системного вызова на x86 вообще нет, вместо этого он производится вызовом прерывания. Более того, на Linux, номер системного вызова execve разный для x86 и x86_64. (11 на x86; 59 на x86_64).
Теперь, когда мы знаем, как вызвать системную функцию, рассмотрим подробно каждый шаг нашего кода:

Ух! Тут много всего. Но зато теперь мы можем заменить foo() на вызов шелла.
Теперь, вместо того, чтобы изменить один байт в теле функции foo(), нам надо поменять ее полностью. Это можно сделать с помощью memcpy(). Имея указатель на начало foo() и указатель на шелл код, мы можем скопировать шелл код на место foo() так:
Нужно быть осторожным, чтобы не зайти за пределы foo(). В нашем случае foo() занимает 41 байт, а шелл код — 29 байт, так что все в порядке. Заметьте, что наш шелл код это строка, и в ее конце стоит нулевой байт. Так как мы хотим скопировать только код, то мы вычитаем единицу из sizeof(shellcode) когда передаем аргумент в memcpy()
Отлично! Теперь соберем все вместе:
И скомпилируем:
Пора скрестить пальцы и запустить.
Вот! Теперь у нас есть самоизменяющаяся программа на C.
Перевод статьи «Writing a Self-Mutating x86_64 C Program»

10К открытий10К показов

Платформа для изучения GPU-программирования через решение задач на GLSL и HLSL. Более 250 интерактивных заданий, сгруппированных по темам: от базовых функций и математики до освещения и постобработки.

Почему корпоративная почта до сих пор работает на стандартах прошлого века? И можно ли это изменить без отказа от привычного формата? Разбираемся на примере стандартных протоколов и рассказываем, как мы в «МБК Лаб» подошли к решению этой проблемы.

Разработчики обсуждают Git 3.0: Rust может стать обязательной зависимостью, улучшая безопасность и скорость, но усложняя сборку
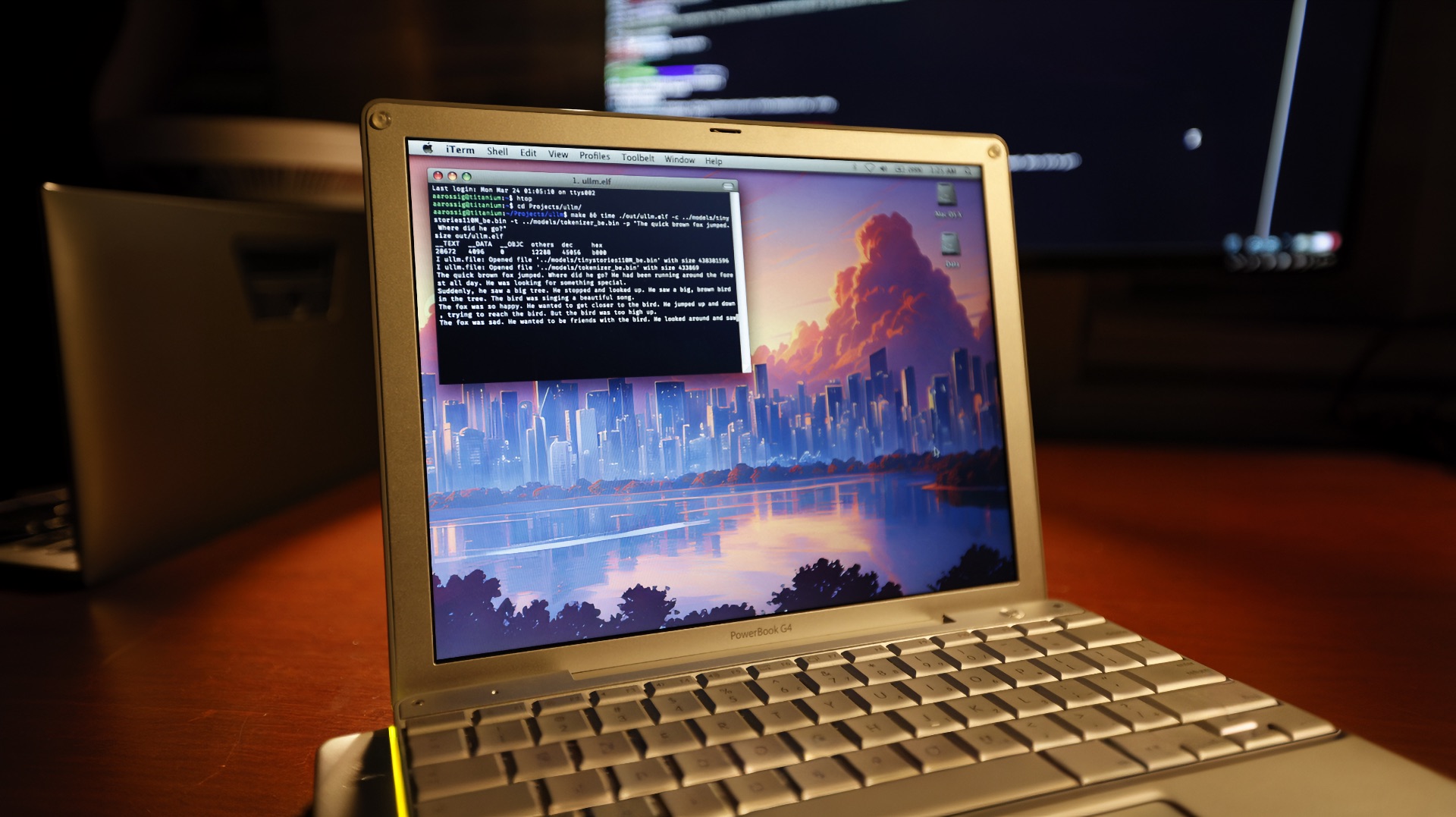
Llama 2 на 20-летнем PowerBook G4: как llama2.c от сооснователя OpenAI запускает нейросети без GPU и библиотек даже на старом Mac