Microsoft Cognitive Toolkit (CNTK): руководство для начала работы с библиотекой
Что такое Microsoft Cognitive Toolkit, зачем вам её использовать, как установить библиотеку и запустить свою первую нейронную сеть.

- Вступление, несколько слов о библиотеке:Кому полезна;Какие задачи решает;Необходимое оборудование;
- Гайд по конфигурации:Список всех дистрибутивов/библиотек и т.д.;Установка библиотеки;Проверка работоспособности библиотеки;
- Описание проблемы XOR:Создание сети, объяснение того, как работает InputVariable (Placeholder) в CNTK;Конфигурация слоя, описание CNTK.Function;Запуск и обучение сети, графическая визуализация процесса обучения.
Вступление и несколько слов о библиотеке
За последние 5–7 лет Python стал самым популярным языком для решения задач машинного обучения. Глаза разбегаются, когда пытаешься выбрать инструментарий для решения своей задачи. Тем не менее, если вы занимаетесь глубоким обучением, 3–4 года назад трудно было найти что-то сложнее, чем модель вида Multi-Layered-Perceptron. Настоящим прорывом была TensorFlow: библиотека поставила все на более «функциональные» рейки, позволила более тонкую настройку модели, а также более сложные архитектуры моделей. В начале 2016 Microsoft нанесла ответный удар, и вышел Microsoft Cognitive Toolkit, он же CNTK.
Библиотека делает упор именно на Deep Learning, если быть еще более точным, — на нейронные сети с рекуррентной архитектурой. То есть вы не найдете здесь привычные вам SVM, Decision Tree, NBC и т.д. Только нейронные сети и ничего больше.
Исходный код находится в открытом доступе, и лично я сейчас активно слежу за поддержкой архитектуры Volta, которая позволяет делать вычисления еще быстрее.
Вы можете задать вопрос: «а почему я должен использовать CNTK, а не тот же Tensorflow или MXNet?» Около года назад началась «гонка вычислений», которую явно вел CNTK: он делал вычисления на одной/нескольких GPU, Tensorflow же на тот момент предлагал только 1 GPU. Производительность на CIFAR-10, MNIST у CNTK также немного выше. Сейчас же библиотеки идут практически «ноздря к ноздре», и главным критерием выбора я бы назвал инфраструктуру вашего проекта. CNTK в этом плане более гибкий, так как вы можете использовать .Net совместно с Python. Также стоит отметить введение формата ONNX, который делает модели совместимыми с Caffe2, MXNet и т.д.
Итого:
- Простота эксплуатации модели в продакшене;
- Возможность экспортирования и создания модели на различные платформы, в том числе .Net;
- Возможность тонкой настройки модели;
- Возможность еще более тонкой настройки процесса обучения;
- Возможность использования GPU, а лучше GPU-кластера;
- Ясный график и активное развитие библиотеки.
Если хотя бы 3 пункта из 5 вам подходят — CNTK будет хорошим выбором. Хотя решающим в большинстве случаев будет второй пункт.
Для начала работы хватит даже CPU, операционная система — Windows, Linux. Если же у вас есть видеокарта, то это должна быть NVidia с поддержкой CUDA-ядер. Приступим к установке библиотеки на Windows. Это будет Python GPU, гайд по конфигурации для .Net сильно отличается, поэтому его вы найдете в другой части.
Конфигурация
Заходим на GitHub CNTK. Выбираем версию в соответствии с конфигурацией вашей машины.
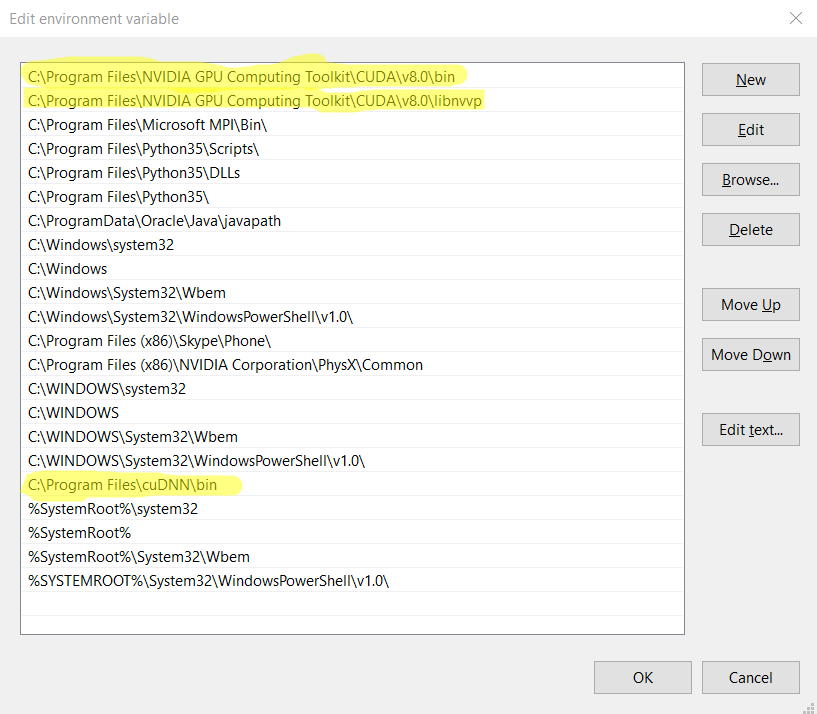
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\libnvvp;C:\Program Files\cuDNN\bin.
Давайте проверим работоспособность библиотеки. Во многом она схожа с Tensorflow, поэтому подход будет скорее функциональный, нежели императивный.
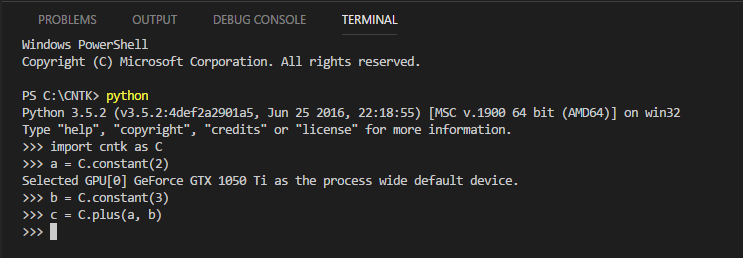
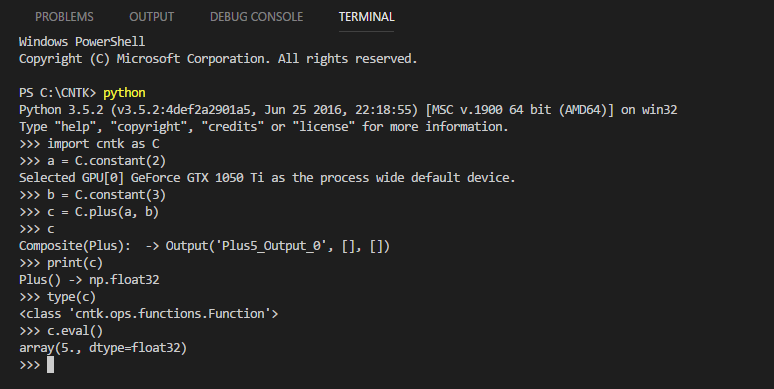
Мы объявили 2 константы — a и b — и присвоили им значения, а их сумму записали в переменную c. Давайте выведем ее значение.
Видим, что переменная c — это Function. В CNTK 70% всего, с чем вы будете работать, представляет собой Function. А у каждой функции есть метод eval, при вызове которого функция вернет значение, что и произошло ниже:
Сама по себе нейронная сеть будет композицией нескольких таких функций, которые не намного сложнее операции плюс. Каждый слой — это некая функция умножения матрицы на вектор и сложения результата с вектором и покомпонентного применения некой функции активации (в большинстве случаев). Визуально это выглядит так:
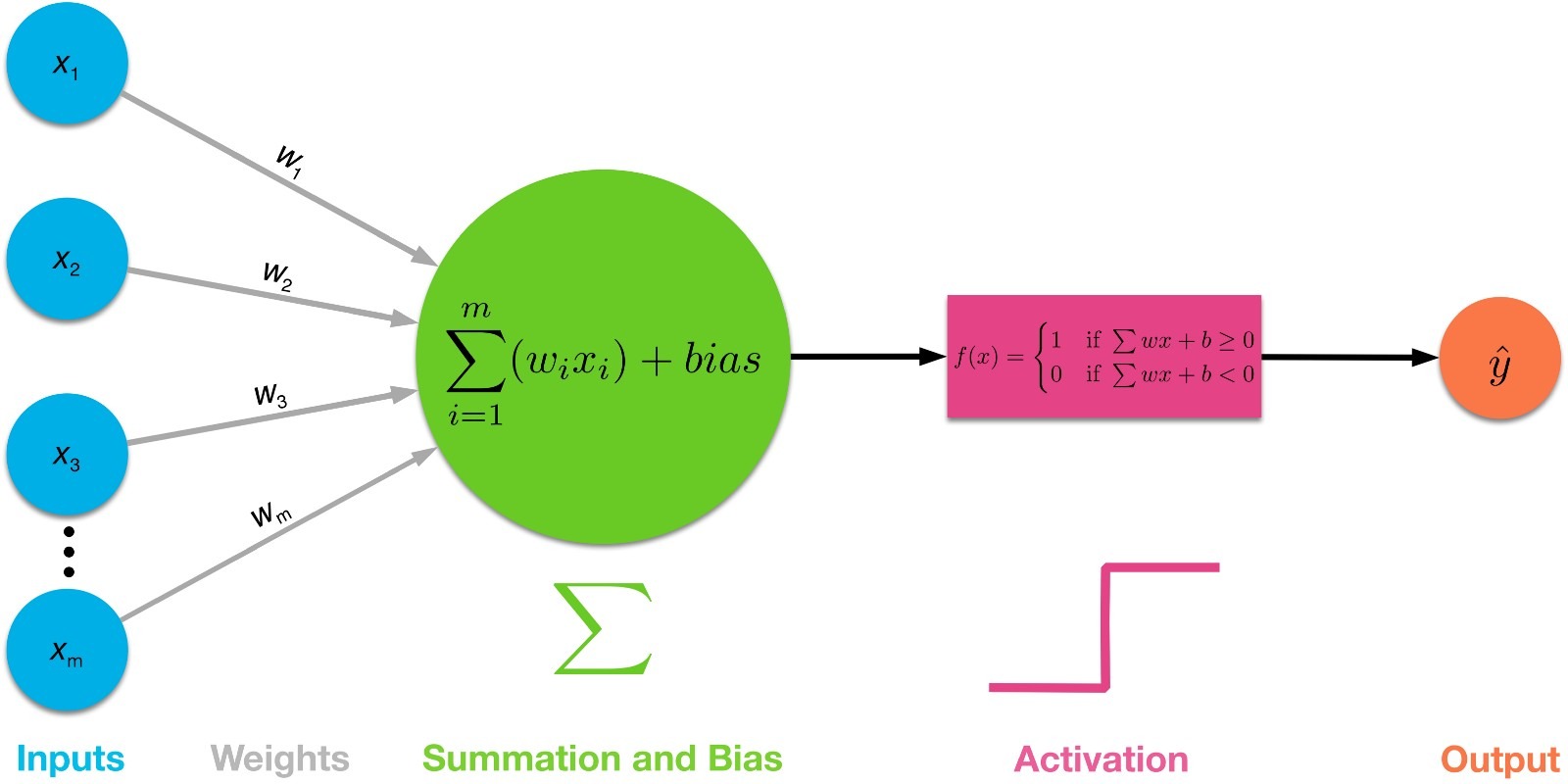
Постановка задачи
Раз мы знаем устройство элементарной компоненты, давайте попробуем решить какую-либо задачу с её помощью. Поскольку это Neural Hello World, задача будет простой — обучение операции XOR.

Казалось бы, задача довольно примитивная и зачем вообще использовать нейронную сеть для такой ерунды. Но для нейронных сетей эта операция многое значит. Обычная регрессия эту задачу решить не может, так как пространство не является линейно разделимым. Нейронной сети это не помеха, хватит даже трех нейронов. Визуально наша сеть будет выглядеть так:

Давайте создадим в CNTK сеть из рисунка выше, а в качестве функции активации попробуем тангенс гиперболический (он же tanh) и классику жанра — сигмоид.
Импортируем необходимые модули и сконфигурируем некоторые гиперпараметры.
Гиперпараметры — это параметры, которые, в основном, определяют наше обучение/конфигурацию модели, а согласно Википедии — это параметры, значения которых присваиваются до процесса обучения. Вот примеры тех гиперпараметров, которые мы будем использовать:
EpochsCount— проще говоря, кол-во раз, которые мы покажем датасет нейронной сети. Как говорится, повторение — мать учения;LearningRate— шаг обучения, то, насколько быстро мы учимся;Input_Dim— размерность наших входных данных. Исходя из того, что операция бинарная, размерность наших данных — 2;Output_Dim— размерность результата операции. Имеет размерность 1.
Как было написано выше, у библиотеки несколько функциональный подход. Есть свои особенности задания размерности данных. Это делается при помощи создания некого плейсхолдера — input_variable, который и «подвязывает» мир к сети (input_) и результат работы сети к миру (ouput_) во время обучения.
Теперь самое интересное — объявление сети. Пока сделаем версию с тангенсом. Что происходит ниже: мы создали модель (функцию), которая содержит в себе 3 слоя (C.layers.Dense(N) — этой функцией можно объявить полносвязный слой, где N — кол-во нейронов в слое). В первом слое у нас 2 нейрона, в следующем — 1, а последний — это выходной слой. Дело в том, что мы еще не подключили входной слой. Это происходит в return’е функции, где мы параметром передаем «входной слой», а вернее некий плейсхолдер для него, всем остальным слоям, которые представлены композицией функций. Параметр init отвечает за случайное распределение, которое инициализирует веса сети.
Объявим наши датасеты, здесь все просто и понятно:
Теперь второй по сложности этап — конфигурация обучения. Она будет состоять из расписания, алгоритма оптимизации и тренера.
Расписание
Здесь мы задаем шаг обучения и то, как мы учимся, весь датасет/батч датасета или же «поштучно» берем каждый образец из датасета и обучаемся относительно него одного. Об этом подробнее будет рассказано в более поздних статьях, так как это уже продвинутые вещи.
lr_schedule = C.learning_rate_schedule(LEARNING_RATE, C.UnitType.minibatch)
Алгоритм оптимизации
Я решил выбрать один из самых универсальных методов градиентного спуска — ADAM. Если не знаете, какой метод использовать, всегда берите ADAM с ускорением 0.9. Его преимущество в том, что он сам знает, когда ему нужно ускориться, а когда замедлиться в процессе обучения, хотя это вновь достаточно высокая материя. Далее идет функция потерь — всем знакомый Squared Error.
Тренер
Далее, нашу модель, функцию потерь и алгоритм оптимизации необходимо передать тренеру, который и будет обучать нейронную сеть.
Визуально процесс обучения будет выглядеть следующим образом:

Финишная прямая
«Причешем» датасет под ту форму, в которой его может принять тренер. Для этого создадим датамап, который имеет некую структуру входных и выходных данных, которую мы сконфигурировали ранее:
Для того, чтобы иметь возможность следить за процессом обучения, будем сохранять значение функции потерь с каждой итерации (эпохи).
losses = []
И, собственно, вот блок, ответственный за обучение на протяжении 200 эпох с сохранением значения функции потерь.
Тренер принимает входные данные, привязанные к плейсхолдерам, с которыми может работать сеть, и проводит обучение.
Для наглядности будем выводить значение функции потерь каждые 10 эпох:
Нарисуем график функции потерь в зависимости от эпох:
У меня вышла следующая картина:
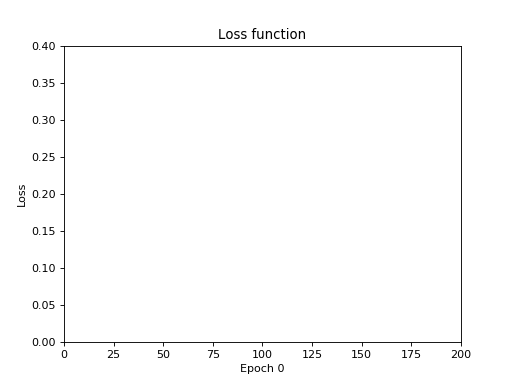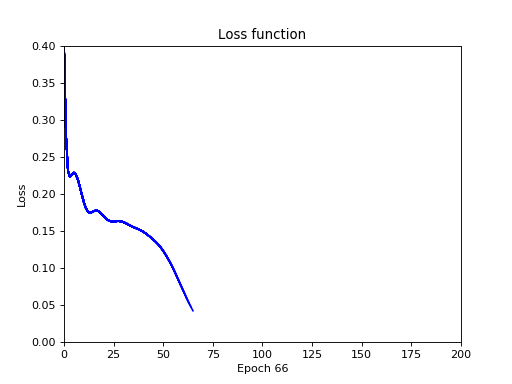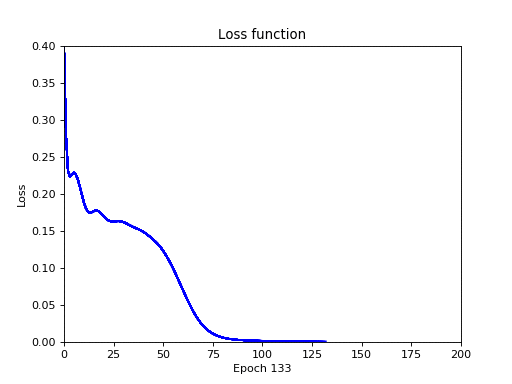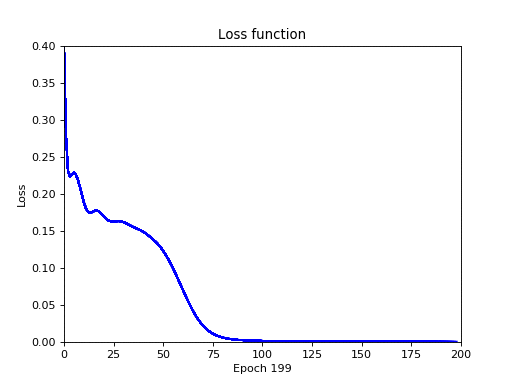
Чем ниже значение функции потерь (ошибок) — тем лучше. Неформально, это можно понимать как то, что начиная с 75-й эпохи нейронная сеть обучилась операции XOR полностью, а ошибка приравнялась к нулю.
Так как наша нейронная сеть — функция, ей можно передать некий аргумент и узнать значения, которые она выдала от него при помощи метода eval. Вновь-таки, помним, что все делается через плейсхолдеры, которые мы объявили выше:
У меня вышел следующий ответ:
Что эквивалентно [[ 0 ][ 1 ][ 1 ][ 0 ]] — результату операции при всех возможных аргументах.
Давайте теперь поэксперементируем, поменяем функцию активации на сигмоид.
Запускаем скрипт и смотрим на график функции потерь.
Ухудшилась вроде бы незначительно, а теперь посмотрим на ответ, который дает сеть:
Полная ерунда. Правильны только первые 2 ответа. Давайте увеличим кол-во эпох с 200 до 2000.
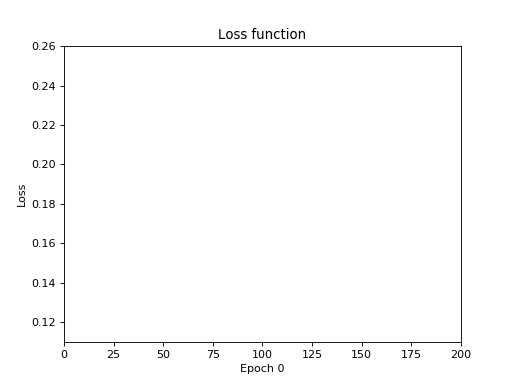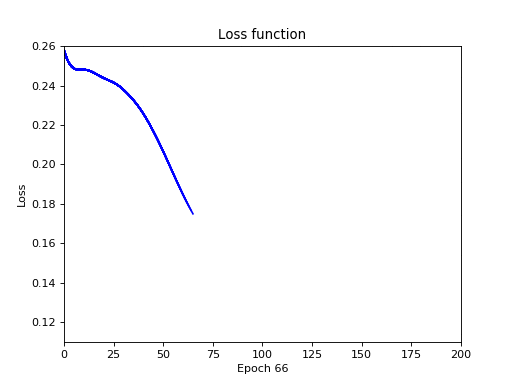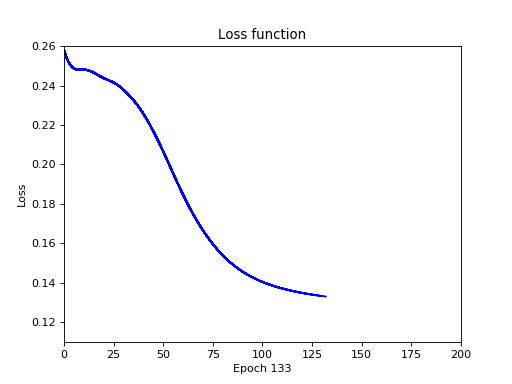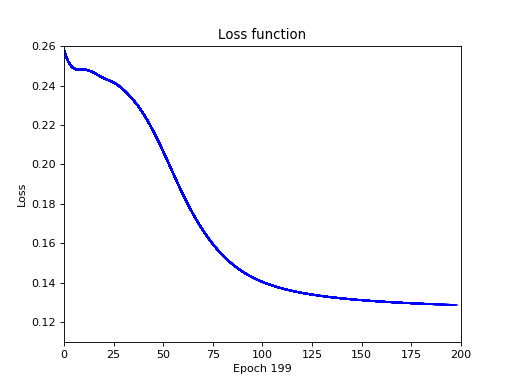
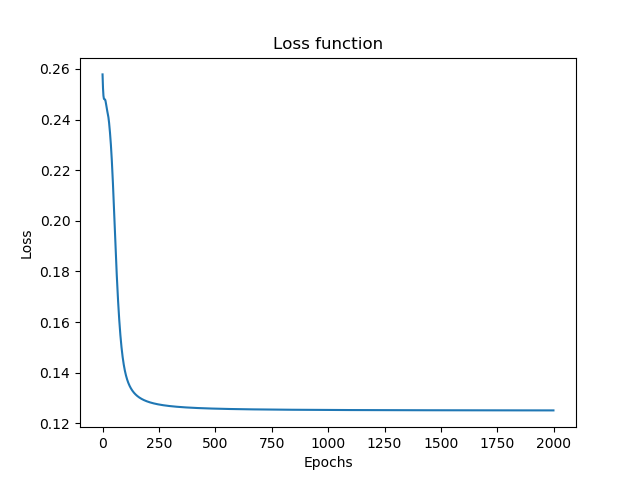
Не помогло. Давайте поступим более радикально и в корне поменяем архитектуру сети для сигмоида: сделаем 1 скрытый слой в 4 нейрона, а кол-во эпох — 500:
Запускаем и видим, что график функции потерь уже более-менее прилично выглядит:

Смотрим на результаты:
Уже лучше, погрешность есть, не сказать, что большая, не сказать, что маленькая. Тем не менее сеть обучилась и дает безошибочный результат. Мораль простая: экспериментируйте с функциями активаций и архитектурой сети, пользуясь одним простым правилом — не усложнять раньше срока. Начните с самой простой архитектуры сети, самых простых функций активации, а затем постепенно усложняйте ее и проверяйте производительность нейронной сети.
Продолжение следует…
Авторы:
Александр Ганджа, CTO DataTrading
Богдан Домненко, Data Scientist DataTrading

12К открытий12К показов

Рассказали о том, как стать цифровым кочевником, какие трудности могут возникнуть на пути и какие навыки потребуются для IT-специалиста.
За звание лучшего программиста в мире сразятся Линус Торвальдс и Бьёрн Страуструп, а за третье место — Андерс Гейлсберг и Билл Гейтс.

В США преступник, пытаясь скрыться от полиции, ранил робо-пса Boston Dynamics, трижды выстрелив в него из пистолета. Но это ему не помогло

Рассказали, как удалось масштабировать приложение при помощи виджетной разработки и как успешно внедрить виджеты.