


Как машинное обучение помогает искать подходящие вакансии на SuperJob

Частично мы уже занимались ранжированием под текстовый запрос, но надо идти дальше. Мы решили подключить к нему машинное обучение.
2К открытий2К показов

Теван Саркисян
Ведущий разработчик SuperJob в группе «Поиск»
За годы работы сервиса мы много сделали для улучшения полноты поисковой выдачи и удобства использования. У нас масса идей и гипотез, которые мы постоянно проверяем. То, что выстреливает, внедряем в продакшн. В итоге в нашем поиске реализовано довольно много интересных фич.
К примеру, мы разработали очень подробный справочник синонимов профессий для обогащения результатов, автоматически исправляем опечатки в запросах и исключаем из него некоторые неважные слова. Умеем кластеризовать объявления — объединять в единое целое дубли и близкие по описанию вакансии (вот тут хорошая статья на эту тему от моего коллеги) и расширять географию, если в домашнем регионе результатов недостаточно. Есть свои фокусы и для ранжирования результатов поисковой выдачи в соответствии с текстовым запросом.
Учитывая, какую работу мы уже проделали, придумывать что-то новое все тяжелее. Поняв, что все «низко висящие фрукты» уже собраны, мы решили попробовать внедрить машинное обучение.
Зачем всё это
Одна из проблем, с которой сталкивается соискатель, — лимит времени. Фактически у него есть фиксированное окно, когда он может зайти на сайт, поискать вакансии и откликнуться на них. Но предложений гораздо больше, чем он может изучить за этот период. То есть часть вакансий он просто не видит.
Наша задача — попытаться ранжировать поисковую выдачу, чтобы поднять наверх самые подходящие вакансии для него. И вместить в это ограниченное окошко времени максимум полезных действий (откликов).
Частично мы уже занимались ранжированием под текстовый запрос, но надо идти дальше. И мы решили подключить к нему машинное обучение. А раз это эксперимент, поставили цель сделать всё максимально быстро, просто и дешево. И без дополнительных вложений в инструменты.
Выбор подхода для обучения модели
Первый вопрос — на чём обучать нашу модель? В классическом варианте для задачи ранжирования мы берём выборку запросов и соответствующих им документов, возлагая задачу оценки, насколько документы верно отсортированы, на асессоров. Но, к сожалению, данный вариант нам не подошёл. Ориентируясь на текст запроса, мы бы покрыли только половину поисковых обращений. Другая половина — это поиск с использованием фильтров вообще без текстового запроса, когда люди ищут вакансии у ближайшей станции метро, от определённого уровня зарплаты или, например, с вахтой.
Кроме того, у нас очень много так называемых общих запросов: «менеджер», «водитель», «администратор». Одинаково релевантно под запрос «менеджер» подходят совершенно разные вакансии — офис-менеджера, менеджера по продажам и так далее. Обучение модели при таких начальных данных силами асессоров будет выглядеть примерно так:
Поэтому мы выбрали другой подход. В качестве разметки взяли действия самих пользователей — поисковые логи, которые мы пишем достаточно давно.
Мы знаем пользовательские запросы, содержание выдачи и то, как именно пользователь с ними взаимодействовал. В нашем случае просмотр и отклик — это положительный таргет, а их отсутствие — отрицательный.
Остаётся добавить какие-то характеристики самого пользователя. В нашем случае оказалось, что в качестве вектора характеристики проще взять резюме (последнее из обновлявшихся, если у соискателя их несколько — таковых не более 17% пользователей).
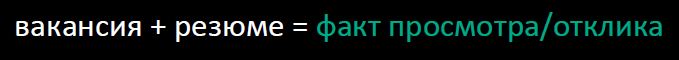
Фактически тут произошла подмена: мы уже решаем не задачу ранжирования, а задачу классификации. Пытаемся предсказать факт отклика или просмотра вакансии, возвращая не бинарные значения с классификатора, а вероятности этих событий. После этого будем сортировать поисковую выдачу в порядке убывания вероятности просмотра или отклика.
Мы по-прежнему теряем половину поисков, потому что их делают неавторизованные пользователи, которых нечем характеризовать. У них нет резюме. Также искажается выдача для тех, кто ищет со своего аккаунта вакансии для других людей (это, скорее, единичные кейсы, над которыми мы ещё поработаем). Тем не менее огромный плюс такого подхода — мы получаем выборку данных для машинного обучения очень быстро и совершенно бесплатно из логов.
Технические требования
Пора переходить к технической реализации. В качестве поискового движка мы используем Sphinx (мы уже в подробностях писали об этом на Хабре), бэкенд сайта реализован на PHP.
От модели нужно было очень быстрое время ответа, поскольку мы планировали применять её в онлайне.
Человек вводит поисковый запрос, попадает на бэкенд в Sphinx, где формируется выдача. В этот момент её нужно пересортировать и отдать пользователю, внеся небольшую задержку во время ответа. До внедрения машинного обучения 95-перцентиль ответа Sphinx был 40 мс. Добавить мы могли максимум 20-30 мс. Кстати, на проде в пике у нас приходит до 1000 запросов в секунду.
У нас есть собственный дата-центр. С одной стороны, это хорошо для машинного обучения. Но с другой — накладывает определённые ограничения, так как у нас нет серверных GPU. Поэтому наша модель должна обучаться на CPU и легко интегрироваться в наш контур.
С учётом описанных ограничений мы выбирали всего из двух вариантов:
- линейной модели;
- градиентного бустинга.
Обе устраивали нас по скорости, но в нашем дата-сете довольно много категориальных данных. Чтобы линейные модели хорошо с ними работали, данные необходимо преобразовывать в вещественные признаки, а это обычно сложные функции, статистика по каждой категории и тому подобное. Для обучения моделей код мы бы писали на Python, но потом в момент применения модели, скорее всего, пришлось бы переносить его на C++. Это повышает вероятность ошибок, которые привели бы к мусору — и на входе, и на выходе.
Поэтому мы выбрали CatBoost. Его киллер-фича — способность из коробки работать именно с категориальными признаками. В него мы могли подать свой дата-сет как есть, ничего не меняя.
Метрики качества модели
Фактически мы обучали классификатор, но планировали его использовать в качестве ранжирующей модели. Среди всех метрик для классификации важнее всего ROC-AUC. Её вероятностный смысл заключается в том, что случайно взятый объект положительного класса (то есть вакансия, которую пользователь просмотрит или на которую откликнется) получит оценку от модели выше, чем случайно взятый объект отрицательного класса. Чем выше эта метрика, тем меньше вероятность где-то вверху списка встретить вакансию, на которую не будет отклика.
К сожалению, для текущей формулы ранжирования (используемой Sphinx без машинного обучения) мы никак не можем рассчитать ROC-AUC. Для расчёта необходимо знать вероятность клика на каждый объект. А мы можем говорить только о фактах. И тут на помощь приходят классические метрики качества именно ранжирования — nDCG, MRR, MAP (вот тут статья на Хабре по этой теме). С помощью них мы можем сравнить выдачу Sphinx и результат нашей сортировки, ведь метрики ранжирования никак не связаны с машинным обучением. Та же nDCG показывает, насколько много объектов с отрицательным таргетом попало вверх поиска (над объектами с положительным таргетом).
В ходе экспериментов мы поняли, что есть корреляция между ROC-AUC метрикам ранжирования, например nDCG. Чем выше ROC-AUC, тем выше будет nDCG. Поэтому использовали метрики ранжирования на начальном этапе, а дальше в обучении сосредоточились уже на ROC-AUC.
Обучение и его скорость
Выбрав подход, мы начали обучать модель на логах поиска за небольшой промежуток времени — около месяца.
Хотя у нас собраны данные за 21 год работы, на тот момент просто не хватило мощностей одного старого сервера. В сумме это было порядка 10 миллионов пар «резюме-вакансия», где четверть — это положительный таргет (просмотр или отклик).
В ходе первых экспериментов с обучением один прогон у нас занимал от 50 минут до пары часов.
Вывод в прод
Обычно мы обучаем модели в Python. Пишем простенький веб-сервер, пакуем модель в веб-приложение, докеризуем и раскатываем на сервере. Но здесь сетевой подход на большой выборке данных обеспечил бы слишком серьёзную задержку. Поэтому решили использовать механизм расширения Sphinx. Мой коллега помог написать табличную функцию, которая принимала на вход типичный запрос в Sphinx, но с некоторыми отличиями.
Отличие в том, что здесь появляются новые колонки: - vacancy_feature_1, …, vacancy_feature_N, resume_feature_1, …, resume_feature_N — это признаки вакансии и соискателя, необходимые модели для построения предсказания.
vacancy_feature— признаки вакансии, которые хранятся непосредственно в индексе,resume_feature— вектор нашего соискателя, который подставляется в запрос в момент его формирования на бэкенде в виде констант.
Помимо запроса, вторым аргументом мы передаём в табличную функцию путь к файлу с предобученной моделью (model-file-name.cbm).
Что получили в итоге
Все изменения у нас уходят в продакшен через AB-тесты. Модель ранжирования, конечно, не была исключением. Но здесь мы провели AAB-тесты — у нас было две контрольные группы и одна тестовая, для которых мы смотрели на ключевые метрики — отклики и просмотры вакансий.
Для подведения итогов ААБ-тестов использовали метод Bootstrap.
За две недели тесты показали статистически значимые изменения. В тестовой группе прирост откликов составил 5,6% (доверительный интервал — 95%). Прирост просмотров — на 8,7% (с тем же доверительным интервалом). Для продукта это значительное увеличение метрик. Другие нововведения, затрагивавшие всех пользователей, давали прирост соизмеримый или меньший. Следующим шагом мы планируем добавить новые текстовые признаки. Ожидаем, что число откликов и просмотров ещё немного подрастет.
Правим баги
Думаете на этом всё закончилось? Нет. Как только выкатили модель в продакшн, посыпались баги. Один из самых ярких — поломка кода на бэкенде, в результате которой на вход модели попадало всегда одно и то же резюме. Итог — модель работала неправильно для всех пользователей.
Баг исправили, но чтобы в будущем не сталкиваться с подобным, нашли библиотеку greatexpectations.io. Она позволяет добавить проверок. Среди прочего можно в онлайн-режиме убедиться, что признаки, которые мы подаём на вход модели, взяты из того же распределения, на котором она обучалась.
Ускоряем обучение
Мы продолжаем думать над новыми фичами, которые можно добавить в модель, чтобы улучшить качество ранжирования. План обучения и тестирования модели мы настроили так, что теперь можем каждые 4-6 недель выкатывать в продакшен новую версию.
Поле для экспериментов огромно. Первое, на что мы обратили внимание, — это скорость обучения. Как я говорил выше, мы ограничивались данными за месяц, использовали и просмотры, и отклики в качестве положительного таргета. Но прогон все равно длился до 2,5 часов.
Коллеги из CatBoost утверждают, что на GPU обучение проходит быстрее — предполагали ускорение до 10 раз. Мы попробовали домашний компьютер одного из коллег, и действительно, модель обучалась быстрее раз в восемь, но качество результата после обучения на CPU было ощутимо выше.
Проблема оказалась в баге, который мы даже нашли на GitHub. Так мы поняли, что пока GPU не выход. Нужно ускоряться по-другому.
Обучение на более современных процессорах обещало ускорение в 4-5 раз. Поэтому мы решили попробовать облако Яндекса. Развернули обучение на спотовых инстансах, и это действительно помогло ускорить процесс.
А дальше попробуем сфокусироваться на приглашениях
Главная цель соискателя — приглашение на собеседование. На первом этапе мы эту сущность не трогали, поскольку приглашений, по статистике, оказалось примерно в восемь раз меньше, чем откликов, а у нас и так обучение занимало продолжительное время. Ускорившись, мы продолжили эксперимент именно в этом направлении. Сейчас мы ждём тестирования модели, где в таргете нет просмотров — есть только отклики.
Конечно, было бы еще лучше, если бы мы научились измерять не только приглашения на собеседования, но и офферы. У работодателей ведь своя воронка. Но проблема в том, что многие крупные клиенты после отклика специалиста ведут общение с ним вне нашего сервиса. Другие вовсе не размещают вакансии, а используют SuperJob как базу резюме, выгружая их в свои системы. Поэтому дальнейшая картина у нас неполная. Впрочем, есть идеи, как этот недостаток можно восполнить.

2К открытий2К показов