


Как работает обучение без учителя
Метод обучения без учителя помогает работать с неразмеченными данными. Разбираемся, какие алгоритмы использовать для решения таких задач.
4К открытий15К показов
Что такое обучение без учителя и почему оно так называется? Какие задачи можно решить с помощью этих методов? А какими алгоритмами? Есть ли у него недостатки? Разбираемся как на банковских примерах, так и на более приземленных вещах — столах, стульях и шкафах.

Элизавета Вялых
Центр технологий искусственного интеллекта
Какие типы машинного обучения бывают и чем они друг от друга отличаются
Есть четыре типа машинного обучения:
- с учителем;
- без учителя;
- с подкреплением;
- с частичным привлечением учителя.
Они отличаются наборами данных, на которых модель обучается. Понять разницу между типами машинного обучения можно через аналогию. В комнате стоят стулья, столы, шкафы, мы ставим задачу определить, где что. При обучении с учителем мы показываем модели: это стул, а это — стол или шкаф. То есть датасет размеченный, информация о данных известна, мы точно знаем, какой результат хотим от них получить. За счет разметки модель понимает, как выглядят предметы, запоминает разные типы.
При обучении без учителя мы просто запускаем модель в большую комнату, и она самостоятельно изучает, какие объекты в ней есть. Спустя время она без наших подсказок понимает, какой объект перед ней находится. Данные не структурированы, о них практически ничего не известно, нет задачи получить конкретный результат. Мы хотим извлечь из данных новую информацию и увидеть в них закономерности.
При обучении с частичным привлечением учителя мы запускаем модель в комнату и выборочно называем ей некоторые предметы. Ей предстоит самостоятельно изучить большую часть объектов и понять, как они называются.
При обучении с подкреплением мы запускаем модель в темное помещение. Она взаимодействует со средой (environment), собирает сведения о ней. В роли «разметки» здесь выступает награда (reward). Это сигнал, насколько хорошо алгоритм справляется с поставленной ему задачей. Например, за каждый найденный стул вы получаете +1, а за каждый удар в стену вам прилетает -1. Она выдаётся после каждого шага взаимодействия со средой.
Для каких задач используют обучение без учителя
Выделяют четыре большие группы: кластеризацию, поиск аномалий, поиск ассоциаций и уменьшение размерности. Рассмотрим каждую подробнее и разберем, какие для них нужны алгоритмы.
Кластеризация
Это задача разделения данных на кластеры по общим признакам.
Классический пример — сегментация пользователей приложения банка. Например, пользователи часто покупают товары в спортивных магазинах. Можно выделить их в отдельную группу, используя транзакции как признак. А можно посмотреть, как часто пользователи заходят в приложение, сформировав из них «временные кластеры».
Другой пример — классификация клиентских обращений. По признакам, которые выделит модель, можно кластеризовать обращения клиентов на разные группы: жалобы, благодарности и просьбы о помощи.
Алгоритмов для этого класса задач много, рассмотрим четыре самых популярных.
Алгоритм k-средних (k-means)
Буква k в названии отвечает за количество выделенных центроидов — точек, которые формируют вокруг себя кластер. Удобнее, если они совпадают с точками выборки данных, но необязательно.
К примеру, возьмем значение k, равное 5. Дальше для каждой точки датасета посчитаем расстояние до каждого из пяти кластеров. Наименьшее расстояние от точки до центроида позволит модели предположить, что объект принадлежит к этому кластеру.
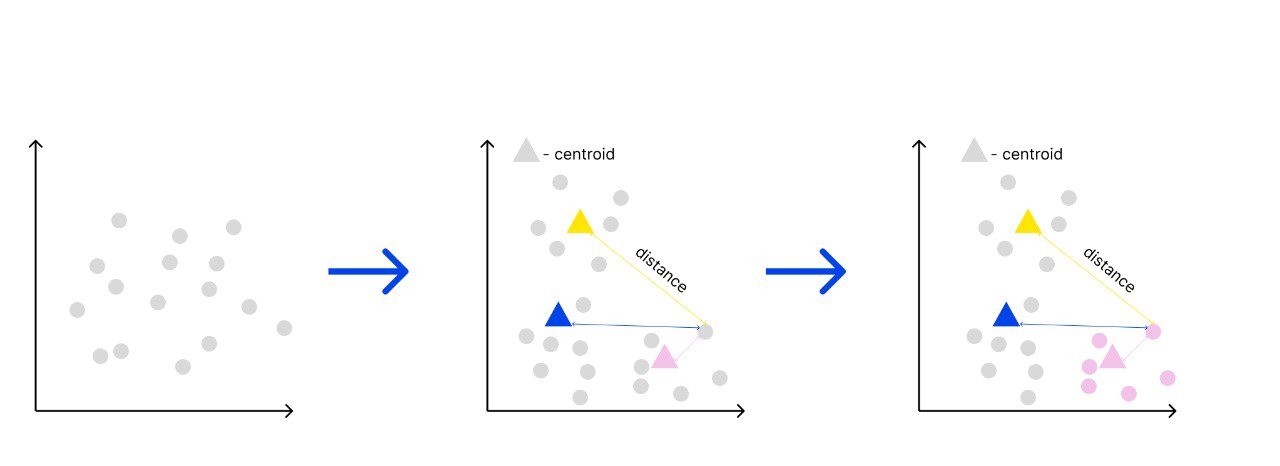
Это итеративный метод, так как после формирования кластеров координаты центроида должны быть пересчитаны, так как центральный элемент кластера может измениться после добавления элементов. Центроид может сместиться, поэтому в следующих итерациях алгоритма мы будем пересчитывать центры кластеров до тех пор, пока координаты центроида не перестанут меняться. Так, он будет представлять усредненное описание всех параметров кластера.
Чтобы оценить качество работы алгоритма, мы используем метрику WCSS (within-cluster sum of squares) — cумму квадратов внутрикластерных расстояний до центра кластера. Основная идея, лежащая в основе k-means, заключается как раз в определении таких кластеров, чтобы отклонения внутри минимальны.
У алгоритма есть ограничение: чаще всего мы не знаем, сколько кластеров предполагается. Можно последовательно брать разные k: 3, 5, 7, 9 и так далее — и строить график в координатах WCSS(k). По нему мы можем понять, какое k оптимальнее взять для задачи. До точки k = 3 наблюдается быстрое уменьшение отклонения, но потом скорость падения снижается, откуда мы делаем вывод, что k = 3 было точкой оптимума.

Иерархическая кластеризация
Изначально количество кластеров совпадает с количеством объектов, то есть каждый объект данных представляет собой кластер. Похожие кластеры объединяются по повторяющимся признакам.
Алгоритм последовательно объединяет меньшие кластеры в большие — это агломеративная иерархия. Либо наоборот — дробит один большой кластер на меньшие — это разделяющая иерархия.
Определить похожесть можно с помощью метрик евклидова расстояния. Они бывают разные: манхэттенское расстояние; расстояние Чебышева; степенное расстояние.
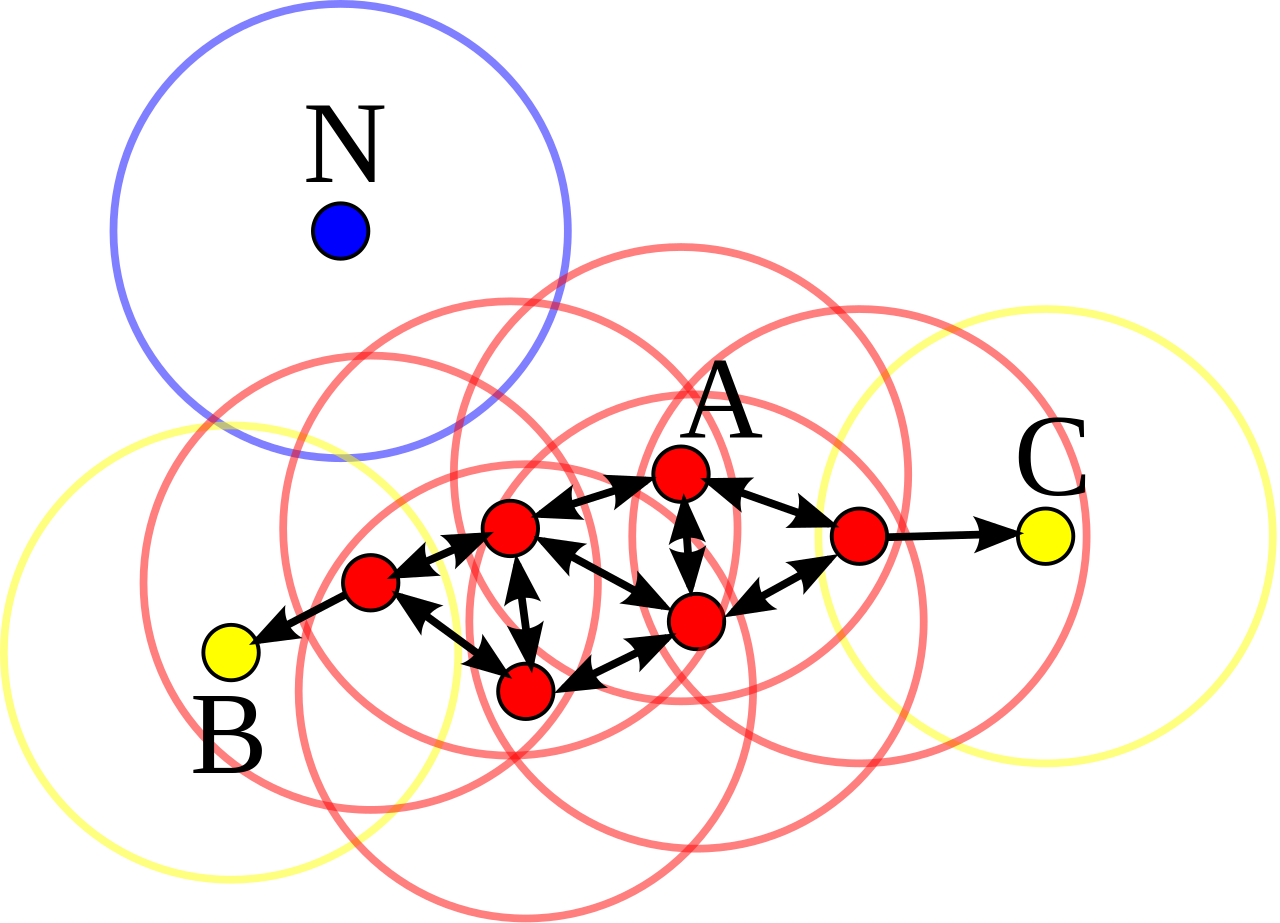
dbscan
В алгоритме есть два гиперпараметра: максимальное расстояние между точками и минимальное количество точек в окрестности. Мы задаем количество соседей внутри определенного радиуса, чтобы выделить их в кластер.
dbscan также справляется с задачей детекции аномалий (о которой поговорим ниже). Так как у нас сохраняется количество соседей в радиусе, то могут оставаться «одинокие» точки, которые туда не попадают. Они являются либо выбросом, либо аномалией.
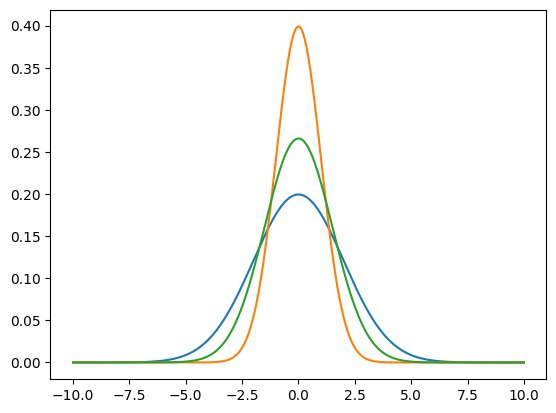
Алгоритм гауссовой смеси
В наборе данных выделяются гауссовы распределения, каждое из которых представляет собой единый кластер. Алгоритм используется в случае, когда наши данные имеют мультимодальное распределение, то есть имеют несколько «горбов».
Поиск ассоциаций
В этой задаче модель ищет взаимосвязи между существующими объектами.
Классический пример — взаимосвязь продуктов в корзине покупателя. Например, к молоку и яйцам рекомендательная система магазина может посоветовать взять муку. Чтобы получить такой «совет», нужно проанализировать, какие комбинации продуктов встречаются чаще всего.
Алгоритм Apriori
Он находит самые частые комбинации, и модель создает правила ассоциативности: когда встречаются два продукта, к ним присоединяется третий.
Для работы с алгоритмом нужно знать такие понятия.
- Support. Показывает минимальный порог встречаемости элемента, чтобы считаться частым.
- Confidence. Как часто выделенные взаимосвязи встречаются во всех объектах во всем датасете.
- Lift. Зависимость между объектами.
- Conviction. Как часто утверждается, что товары связаны, хотя на самом деле взаимосвязи нет.
Уменьшение размерности
Данные могут быть слишком взаимосвязаны между собой. В таком случае можно снизить размерность, заменив два признака на один. Особенно это актуально в больших данных, когда нужно сократить датасет и обработать меньшее количество данных.
Для этой задачи используется алгоритм PCA. Собственно, он как раз и «жертвует» каким-то некритичным количеством информации, подбирая новый признак, который будет включать в себя свойства обоих изначальных признаков.
Поиск аномалий и выбросов данных
Пример задачи — антифрод в банке. Модель должна определять мошеннические транзакции среди обычных и правильно на них реагировать.
При обучении с учителем не получится показать модели такую транзакцию сразу, потому что мы не знаем, как она выглядит. И, соответственно, у алгоритма этого знания тоже не будет. Поэтому когда модель встретится с фродом, то, скорее всего, либо не сможет его задетектировать, либо правильно интерпретировать.
При обучении без учителя модель может определять выбросы и аномалии. Аномалия — это принципиально новые данные, которых ещё не было в выборке, они возникают в реальном времени. Выброс — значение, редко встречающееся в наших данных.
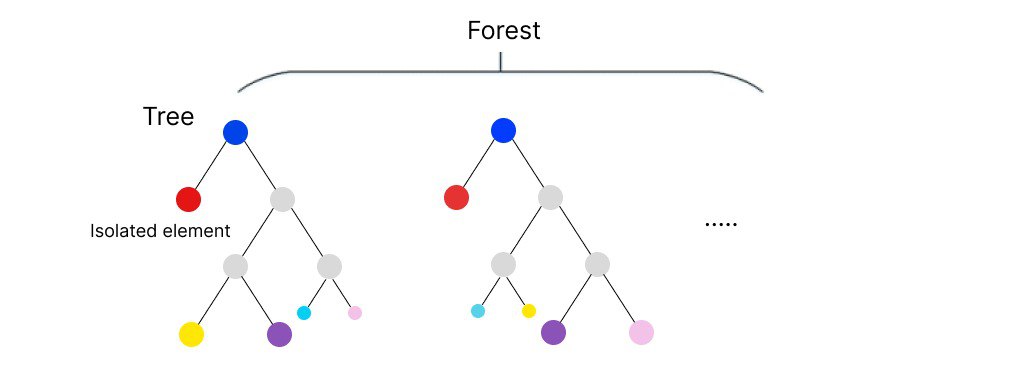
Изолированный лес
В его основе лежит модель классического алгоритма ML — дерева. Случайным образом задаем предикат, если объект датасета под него подходит, он уходит по этой ветви дерева. Объекты, которые не прошли глубже по веткам, а остались на глубине первого или второго уровня можно считать выбросами. Они «изолировались».
Какие есть ограничения у обучения без учителя
Во-первых, результаты не всегда интерпретируемы. Не каждому квалифицированному специалисту под силу объяснить выделившиеся закономерности.
Во-вторых, модель может ошибаться и выдавать не те корреляции, которые мы ожидали. В примере из начала статьи про комнату со стульями и столами модель может, например, выделить кластеры не по принадлежности к сущности (столы, стулья и т.д.), а по цвету: красные столы, стулья, шкафы. Да, это тоже может быть верно, у них действительно есть схожее свойство, но нам это было не нужно.
В таком случае, кстати, придется прибегнуть либо к обучению с подкреплением, либо к частичной разметке данных, чтобы хотя бы в какой-то степени показать модели, на что ей ориентироваться.
Когда же лучше использовать обучение без учителя
Метод обучения без учителя хорошо справляется с неразмеченными данными.
Разметка данных — это достаточно дорогой процесс. При большом количестве данных нужно нанимать асессоров, которые подготовят данные для обучения с учителем. Есть сервисы, где можно отдать данные специалистам на разметку, но за это нужно будет заплатить, подготовить тесты, по которым люди будут работать. И в конце оценить качество разметки. Если мы не хотим тратить на это ресурсы и время, то лучше использовать обучение без учителя.

4К открытий15К показов

Адель Валиуллин делится опытом участия в соревнованиях и рассказывает, как занять высокое место в рейтинге Kaggle.

Если бы у вас была машина времени и можно было вернуться в прошлое, чтобы дать совет двадцатилетнему себе, о чем бы сказали? Что бы посоветовали не упустить на старте карьеры? Мы решили не дожидаться изобретения путешествий во времени и в рамках Восточного экономического форума провели сессию «Знать бы в 20».
Вторая часть цикла статей про чистый код. В ней покажем пример некачественного кода и разберём основные ошибки.

Газпромбанк запустил подкаст про финтех. В этом выпуске поговорили про модели разработки и переход от сервисной модели к формату платформ.