


Как «Строки» подбирают контент, который понравится читателям
Рассказали, какие рекомендательные системы используют и как их улучшают в онлайн-сервисе для читающих людей от МТС.
1К открытий10К показов

«Строки» — стремительно развивающийся книжный онлайн-сервис от МТС. В каталоге «Строк» есть электронные и аудиокниги, газеты, журналы, подкасты, в том числе эксклюзивные. Важная часть сервиса — уникальные рекомендательные системы от Big Data МТС. Именно они помогают читателю выбрать в огромном массиве книжек, текстов, подкастов и аудио то, что ему наверняка будет интересно и необходимо. Как работают рекомендательные системы «Строк» и что мы для этого делаем, рассказывает

Олеся Рвач
ML-разработчик
Рекомендательные системы: какие бывают и какие мы используем в «Строках»
Рекомендательные системы — алгоритмы, которые анализируют обобщённые обезличенные данные о предпочтениях пользователей и, опираясь на большой объём накопленной информации, предлагают им услуги, контент или другие элементы, которые могут заинтересовать.
Рассмотрим методы фильтрации, которые используются для построения рекомендаций внутри «Строк».
Фильтрация по контенту (content-based filtering). Данный метод предлагает контент, который похож на те произведения, с которыми раньше взаимодействовал пользователь. Например, рекомендательная система видит, что уже прочёл пользователь, типизирует его предпочтения на основе контента и будет предлагать книги, которые похожи на то, что ему нравится.
Коллаборативная фильтрация (collaborative filtering). Метод коллаборативной фильтрации анализирует предпочтения множества пользователей, типизирует их и на основе сходства между пользователями (users) и товарами (items) строит рекомендации. Пользователи — это клиенты сервиса, товары — объекты, которые предлагает сервис (книги, аудиокниги, подкасты и пресса).
В «Строках» применяются гибридные рекомендательные системы, которые сочетают в себе оба метода фильтрации. Гибридный подход позволяет использовать преимущества коллаборативной фильтрации и фильтрации по контенту, тем самым повышая качество и соответствие рекомендаций потребностям читателей.
Рассмотрим на примерах.
User-to-item рекомендации
Такой вид рекомендаций можно найти в «Строках» на главной странице, а также на странице книг и аудиокниг в разделе «Специально для вас». Там представлены персональные рекомендации текстового и аудиоконтента, которые сформированы с учётом предпочтений и интересов пользователя.
Для построения качественных user-to-item рекомендаций требуется пользовательская история взаимодействия с контентом: прочтения или прослушивания книг, добавления понравившихся в «отложенное», а также доступная мета-информация о пользователе, например, его пол и возраст.
Чем больше пользователи взаимодействуют с контентом и сервисом, тем больше полезной информации о поведении и интересах получают рекомендательные системы.

Item-to-item рекомендации
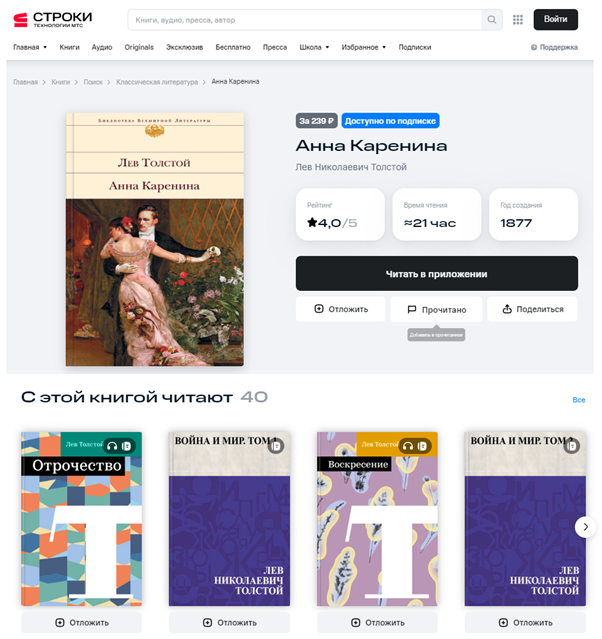
На странице с описанием книги, подкаста или другого контента, в разделе «С этой книгой читают» пользователи получают рекомендации, которые основаны на фильтрации по контенту.
При построении item-to-item рекомендаций в «Строках» система формирует релевантные подборки, исходя из различных свойств самой книги, таких как жанры, авторы и название. Эта информация носит обобщённый характер, её сервис получает от партнёров-издателей, поэтому встречаются погрешности в данных, которые влияют на качество рекомендаций.
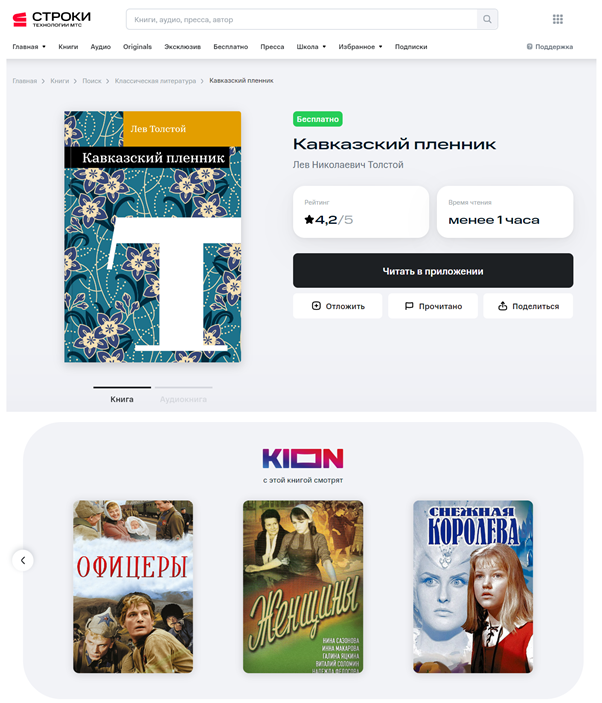
Кроме того, в «Строках» также используются системы кросс-рекомендаций с онлайн-кинотеатром KION. Пользователь получает item-to-item рекомендации фильмов, которые были сняты по книге, или похожие кино.
Как в «Строках» улучшают системы рекомендаций
Чтобы рекомендации в «Строках» были интересными и разнообразными, мы разработали алгоритм, с помощью которого пытаемся улучшить работу рекомендательных систем.
Формирование гипотезы
Сначала генерируется идея, которая поможет улучшить качество рекомендаций, — гипотеза. Например, чтобы сделать контент разнообразнее, добавим в систему правило: 75% подборки рекомендаций формируется из контента, который доступен для пользователя.
Обучение модели
Затем происходит обучение модели с внедрением необходимых изменений. Разработчик вносит правки в существующие алгоритмы и заново обучает модель на неизменном наборе данных.
В данном случае набор данных — это обезличенная информация о поведении пользователя внутри сервиса и о книгах. Если гипотеза касается изменения данных, сначала разработчики и дата-инженеры редактируют данные, а затем обучают модель.
Формирование рекомендаций
После обучения модели происходит прогнозирование рекомендаций для каждого пользователя, если мы говорим про user-to-item рекомендации. Если рекомендации вида item-to-item, то ожидаем подборки рекомендаций для книг.
Оценка офлайн-метрик качества рекомендаций
Внутри «Строк» мы ориентируемся на конверсию попадания рекомендаций из подборки в читалку или плеер пользователя. Этот показатель можно измерить только при запуске обновлённой рекомендательной системы на реальных пользователях.
Однако важным шагом перед запуском обновлённой рекомендательной системы в продуктивную среду является оценка офлайн-метрик качества, которые рассчитываются на исторических данных. Офлайн-метрики позволяют разработчику убедиться, что новые рекомендации корректны с точки зрения точности и полноты предсказаний. Но полностью доверять офлайн-метрикам не стоит, так как предугадать поведение и настроение пользователей в реальном времени рекомендательная система не может.
Чаще всего разработчики нашего сервиса ориентируются на следующие офлайн-метрики:
- Точность предсказаний. Интерпретируется как доля релевантных рекомендаций.
- Полнота предсказаний. Интерпретируется как доля релевантных объектов, попавших в рекомендации.
- Средняя точность по пользователям. Считается как средняя точность предсказаний для пользователя по всем релевантным позициям, далее полученное значение усредняется по всем пользователям.
- Новизна. Под новизной понимается доля новых для пользователя товаров среди рекомендованных.
- Разнообразие. Под разнообразием понимается степень сходства товаров внутри подборки рекомендаций.
Если значения офлайн-метрик качества новой рекомендательной системы выросли или не изменились, то можно переходить к следующему шагу тестирования рекомендаций. Но если разработчик замечает сильное ухудшение офлайн-метрик качества, то процесс внедрения рекомендательной системы в продуктивную среду останавливается. И разработчик разбирается, почему произошёл спад метрик. Затем вносит изменения в алгоритм, после чего снова проверяет офлайн-метрики качества.
Визуальный анализ рекомендаций
В отличие от классического машинного обучения, при разработке рекомендательных систем очень сложно заранее смоделировать поведение пользователя. Невозможно предугадать, будет ли пользователь взаимодействовать с релевантными товарами, у которых высокие оценки офлайн-метрик.
Поэтому, когда мы тестируем рекомендации от обновлённой модели, обязательно проводим визуальный анализ. Разработчик просматривает подборки, которые предлагает рекомендательная система, и оценивает, насколько качественно сделаны рекомендации.
При визуальном анализе выделяются яркие представители различных групп пользователей. Группы могут формироваться в зависимости от количества взаимодействий с книгами и собирательного образа типичного пользователя сервиса. Также могут формироваться кластеры в зависимости от жанров и авторов. Например, кластеры «любителей боевого фэнтези» и «ценителей классической литературы».
Оценка онлайн-метрик качества рекомендаций
Если метрики, которые посчитаны на исторических данных, остались неизменными или выросли, а визуальный анализ показал хорошие результаты, то можно запускать A/B-тестирование (так мы называем оценку онлайн-метрик качества рекомендаций). A/B-тестирование сможет честно оценить эффект от изменений, внедрённых в модель рекомендаций.
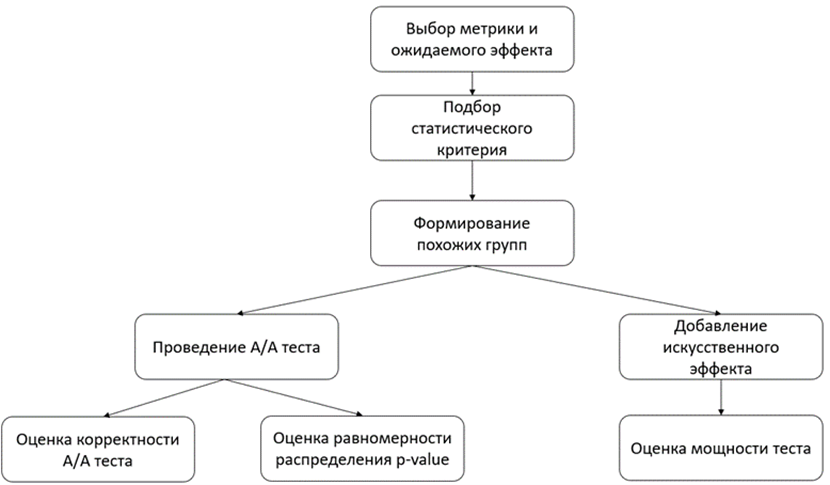
Сначала аналитик готовит А/B-тест к запуску на реальных пользователях. Первым шагом следует выбрать метрику, которую нужно оценить, и зафиксировать ожидаемый эффект для обеспечения достоверности и надёжности результатов теста. Внутри «Строк» целевая метрика — это конверсия попадания рекомендаций из подборки в читалку или плеер пользователя.
Затем аналитик подбирает статистический критерий в зависимости от данных, на которых проводится тестирование. Это мера статистической значимости, которая помогает определить, являются ли результаты теста надёжными, а не случайными.
Следующим шагом нужно поделить пользователей на группы. Главная задача здесь — распределить их поровну, чтобы гарантировать, что любые различия в результатах могут быть связаны с тестируемой рекомендательной системой, а не с другими факторами.
Далее проводится А/А-тест, где предполагается, что полученные на предыдущем шаге группы не имеют значимых отличий между собой.
Затем проводится оценка мощности А/B-теста. К одной из групп искусственно добавляется эффект, который планируется получить после внедрения новой модели в сервис, и рассчитывается время проведения А/B-теста на исторических данных.
После этих этапов A/B-тест запускается в продуктовой среде и продолжается необходимое количество времени, которое было заранее рассчитано на исторических данных.
После истечения рассчитанного времени результаты тестирования проверяются на статистическую значимость.
Внедрение обновлённой модели
Если результаты тестирования оказались статистически значимыми (А/B-тест признан успешным), обновлённую рекомендательную систему можно внедрять на всех пользователей сервиса.
Вместо заключения
Мы рассказали о том, какие виды рекомендаций представлены в онлайн-сервисе «Строки», а также кратко описали подходы, которые используем для их улучшения.
Возможно, у вас есть вопросы, как у пользователя сервиса «Строки», или вы сами работаете с рекомендательными системами и готовы поделиться опытом?
Добро пожаловать в комментарии!

1К открытий10К показов

Второй выпуск гайда по работе с библиотекой Pandas. Разбираемся, как эффективнее анализировать данные, и даём список альтернатив.

От ошибок не застрахованы даже опытные разработчики. Собрали в одном материале ключевые команды Git для управления кодом.

8 000 человек участвовали в олимпиаде, 250 попали в финал и только 12 стали призерами.

Он подойдет мидлам, которые хотят освоить разработку на Golang. Обучение бесплатное, кандидатам нужно будет пройти вступительные испытания.