


От GreenPlum к Mirrorship: Кейс трансформации Bank of Hangzhou Consumer Finance на основе архитектуры Lakehouse
Кейс: как финтех-компания Bank of Hangzhou Consumer Finance заменила GreenPlum на Mirrorship и построила Lakehouse-платформу. Решили критические проблемы с данными, отслеживаемостью и сверкой. Подробный разбор архитектуры и бизнес-результатов — внутри.
94 открытий3К показов

Введение: Инновационный путь, объединяющий озера данных и хранилища
Bank of Hangzhou Consumer Finance — лицензированная организация потребительского финансирования. Столкнувшись с вызовами, связанными с быстрым ростом бизнеса, компания начала трансформацию своей инфраструктуры данных, кульминацией которой стало создание платформы GLH Lakehouse на базе Mirrorship.
Платформа GLH представляет собой результат исследований и практического внедрения архитектуры Lakehouse, служа критически важным мостом, соединяющим бизнес-операции с передовыми технологиями.
I.Предпосылки создания платформы GLH: Инновации, продиктованные «болевыми точками» в данных
1. Требования бизнес-сценариев
Как организация, чья деятельность основана на «данных, сценариях, управлении рисками и технологиях», мы столкнулись с тем, что традиционная архитектура обработки данных больше не могла справляться с растущими потребностями. Эти потребности влияли не только на повседневные операции, но и на стратегические решения и соблюдение нормативных требований.
- Актуальность данных для стратегий: стратегии управления финансовыми рисками требуют своевременных данных для принятия решений. Задержка даже в несколько минут может привести к сбою в контроле рисков.
- Консистентность данных между таблицами: синхронизация данных между различными базами и таблицами должна поддерживать консистентность на определённый момент времени. Любое расхождение могло нарушить бизнес-логику.
- Точность бизнес-данных: ежедневные отчёты для руководства должны быть точными и своевременными, так как они напрямую влияют на стратегическое направление компании.
- Потребности в сверке данных: внутридневные данные необходимы для процессов сверки, и традиционные ETL-процессы не могли обеспечить требуемую оперативность.
- Соблюдение нормативных требований: данные, предоставляемые регуляторам, должны соответствовать строгим стандартам своевременности и точности.
2. Анализ ключевых «болевых точек»
При использовании традиционной архитектуры данных компания столкнулась с несколькими критическими проблемами:
Проблема 1: Сложность отслеживания данных (Data Traceability)
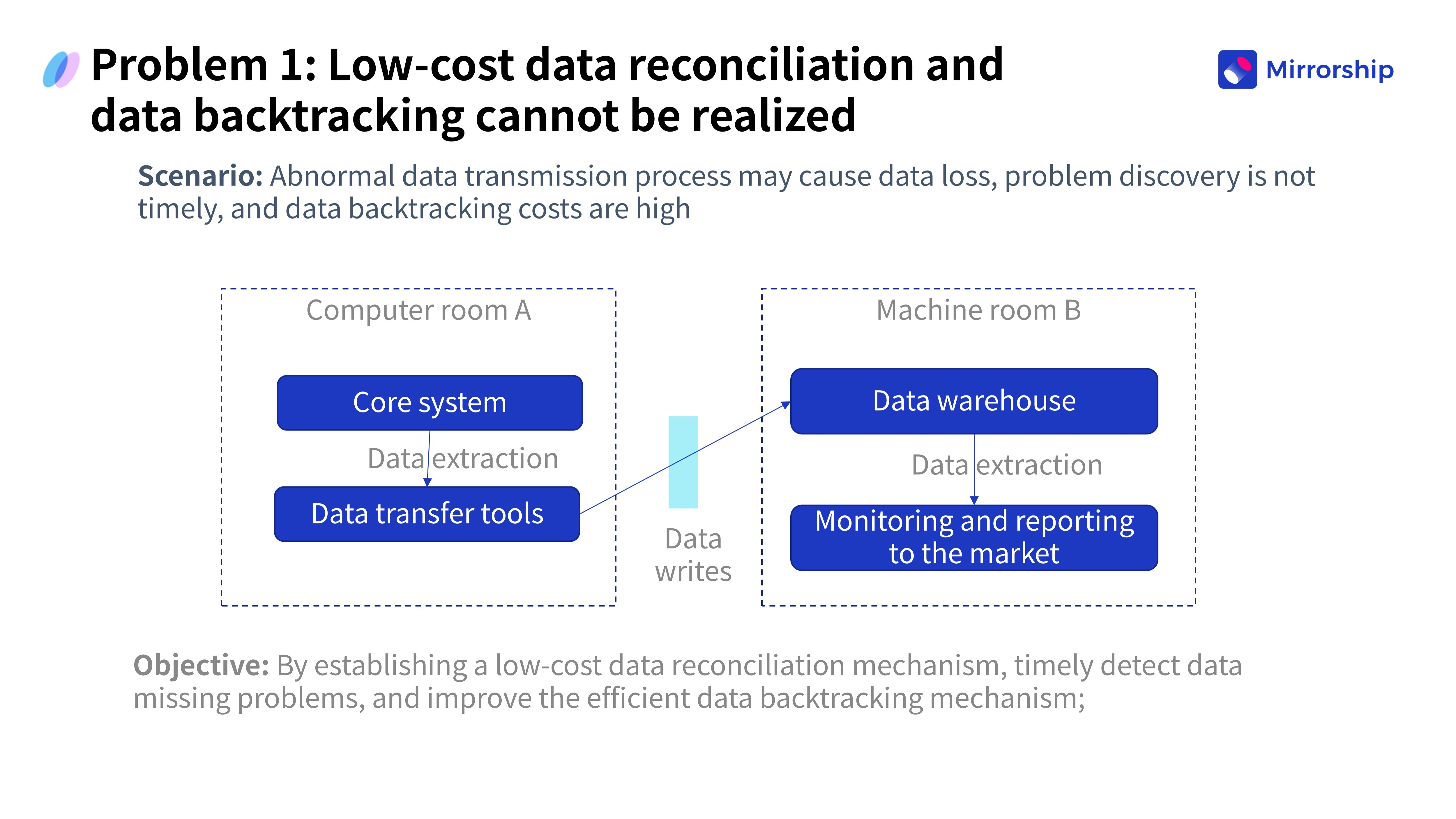
Аномалии при передаче данных могли приводить к их потере. Если проблемы не обнаруживались вовремя, стоимость восстановления и отслеживания истории данных была непомерно высокой.
Проблема 2: Отсутствие детализированных записей об изменениях
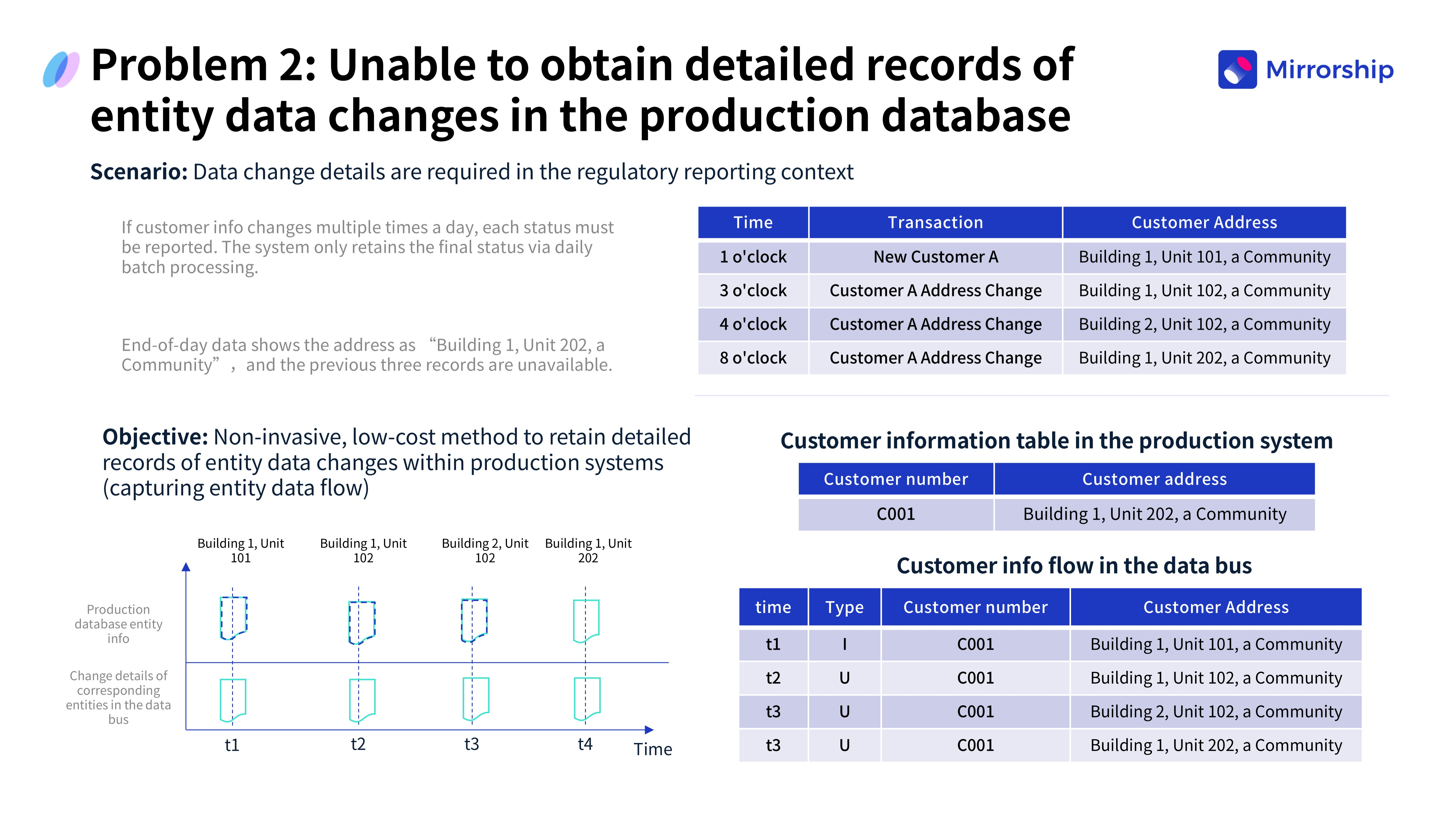
Для регуляторной отчётности требовалось сообщать о каждом изменении информации о клиенте в течение дня. Однако производственная система сохраняла только конечное состояние на конец суток, не фиксируя промежуточных изменений и не удовлетворяя требованиям полной отчётности.
Проблема 3: Неточность данных на определённый момент времени (Point-in-Time Data)
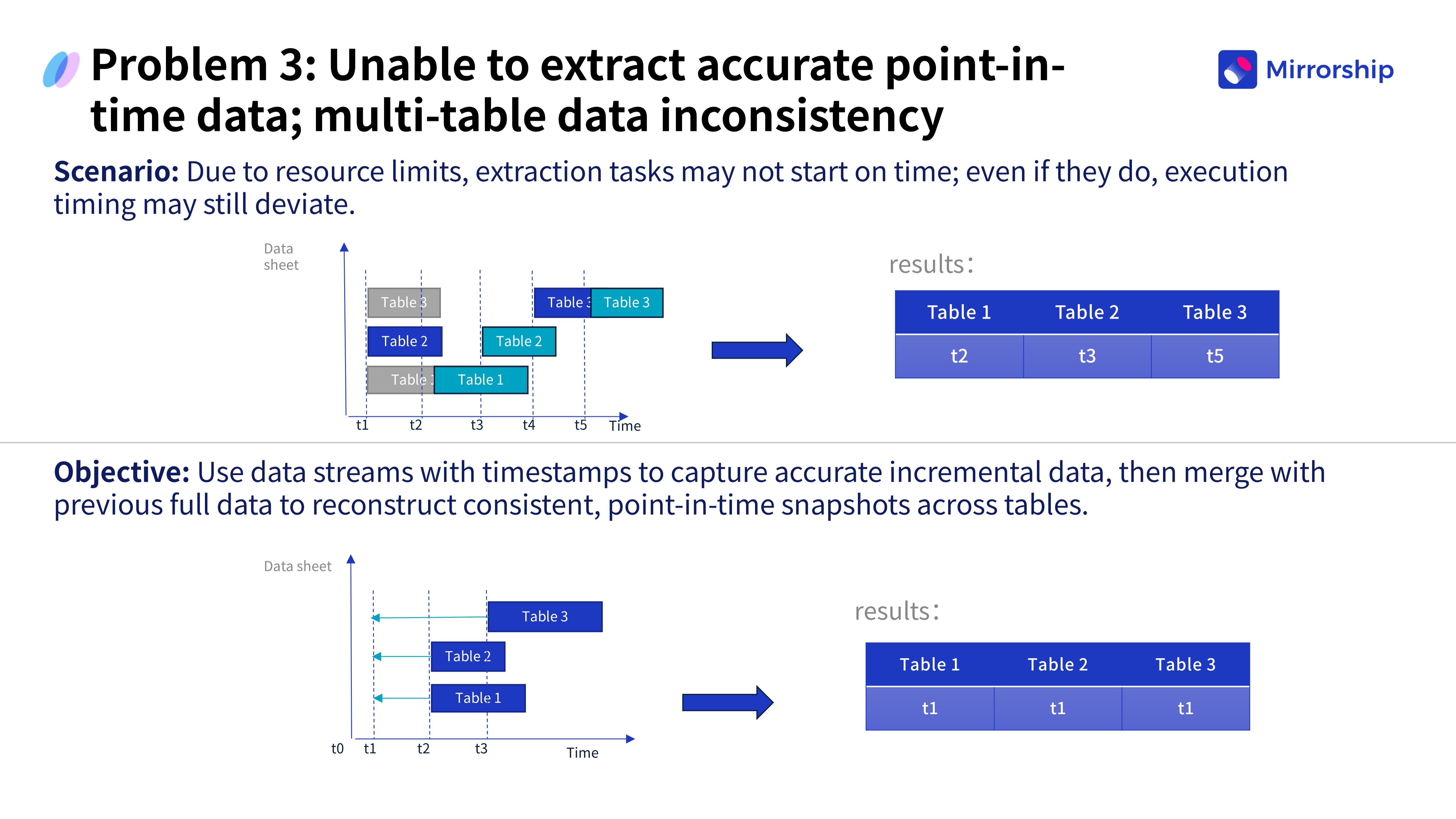
Из-за ограничений ресурсов задания по извлечению данных могли выполняться с задержкой или не выполняться вовсе, что приводило к временным лагам в синхронизации. Это вызывало несоответствие статусов одних и тех же бизнес-сущностей в разных таблицах, порождая хаос в бизнес-логике.
Проблема 4: Проблемы с ежедневным закрытием операционного дня (Daily Cut-off)
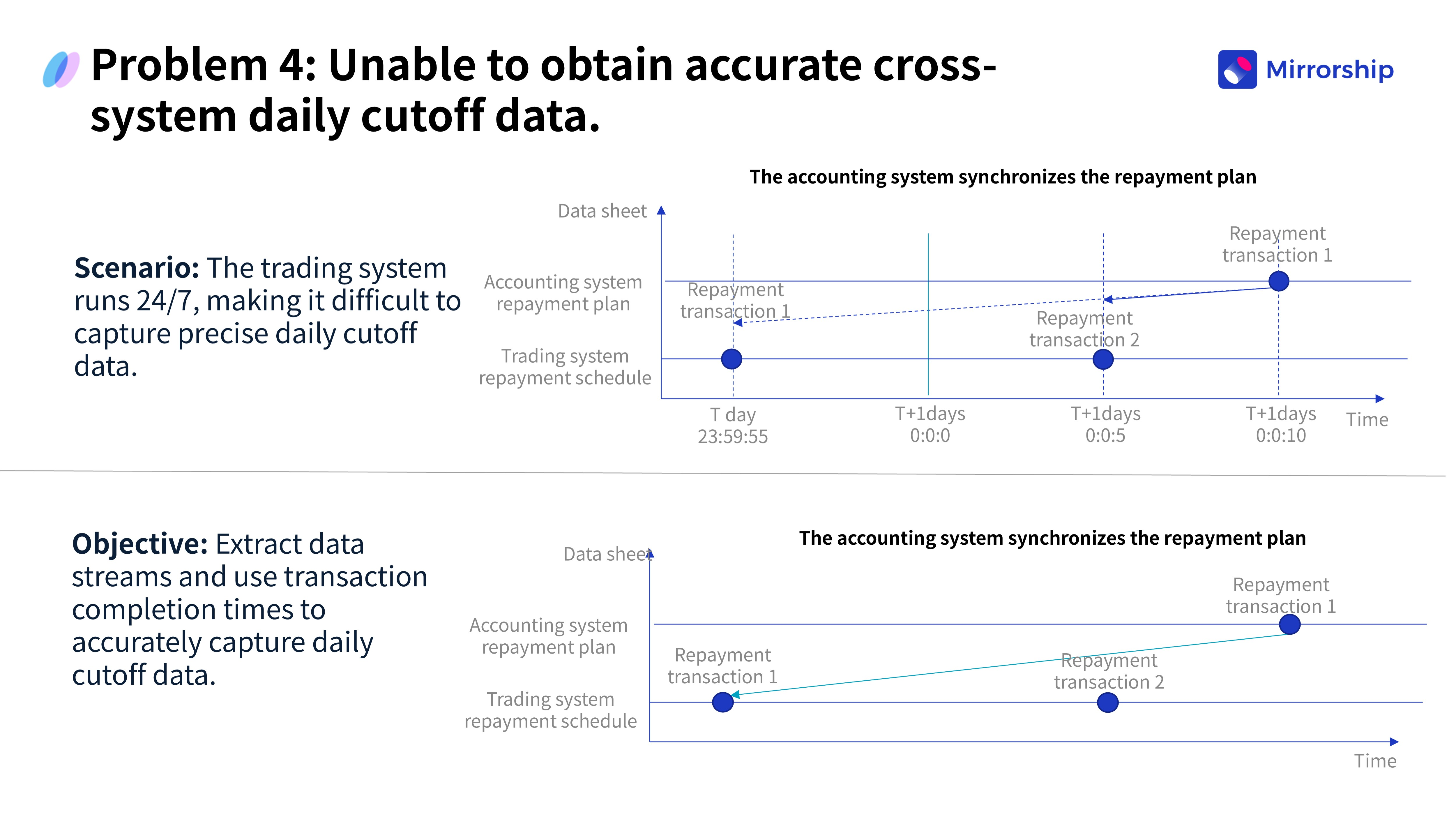
В сценариях сверки транзакций по погашению платежей разные системы (например, транзакционная и бухгалтерская) обрабатывали одну и ту же операцию в разное время. Это приводило к серьёзным неточностям в данных к концу дня, что напрямую влияло на сверку.
Эти «болевые точки» были не просто техническими трудностями — они создавали прямую угрозу для развития бизнеса. Невозможность синхронизировать данные в реальном времени снижала эффективность бизнес-стратегий, несогласованность данных затрудняла сверку, низкое качество данных создавало риски для комплаенса, а сложность отслеживания делала аудиты долгими и дорогостоящими.
II. Построение архитектуры Lakehouse с помощью Mirrorship
1. Техническая архитектура платформы GLH
Платформа GLH была спроектирована с использованием четырехуровневой архитектуры:
- Уровень приложений (Application Layer): включает узел управления (Manager Node), узлы выполнения (Execute Nodes), кастомные плагины и узел оповещений (Alerting Node).
- Уровень технических компонентов (Technical Component Layer): использует экосистему Spring Framework, MyBatis, собственный RPC-фреймворк, Log4j и др.
- Уровень промежуточного ПО (Middleware Layer): задействует ZooKeeper, Kafka и MySQL.
- Уровень эксплуатации (DevOps Layer): основан на Git, Jenkins, Docker & Kubernetes, Maven.
Эта архитектура не только отвечала функциональным требованиям, но и обеспечивала стабильность, масштабируемость и удобство сопровождения системы, заложив прочный фундамент для платформы Lakehouse.
2. Почему для замены GreenPlum выбрали Mirrorship?
Выбор хранилища данных был критически важным решением. После всесторонней оценки и тестирования команда выбрала Mirrorship (корпоративную версию StarRocks) в качестве основного движка для хранения и аналитики.
Выбор было продиктован насущными проблемами — производительность существующего 26-узлового кластера GreenPlum снижалась по мере роста объёма бизнеса, а расширение требовало значительных инвестиций.
- Снижение затрат и повышение эффективности: лицензионные платежи и стоимость горизонтального масштабирования GreenPlum были высокими. Mirrorship предложила более экономически эффективное решение, соответствующее стратегической цели компании.
- Возможности ingest-а данных в реальном времени: в отличие от традиционных инструментов, таких как Hive, Mirrorship поддерживает real-time ingest и транзакционные запросы, что дает ей естественное преимущество в сценариях с данными реального времени.
- Единая платформа данных: данные были разбросаны по разным системам, создавая «острова данных». Mirrorship предоставила единую платформу для хранения и вычислений, консолидировав данные и упростив доступ к ним.
- Дизайн архитектуры Lakehouse на базе Mirrorship
В новой архитектуре платформа GLH глубоко интегрирована с Mirrorship для создания истинной Lakehouse.
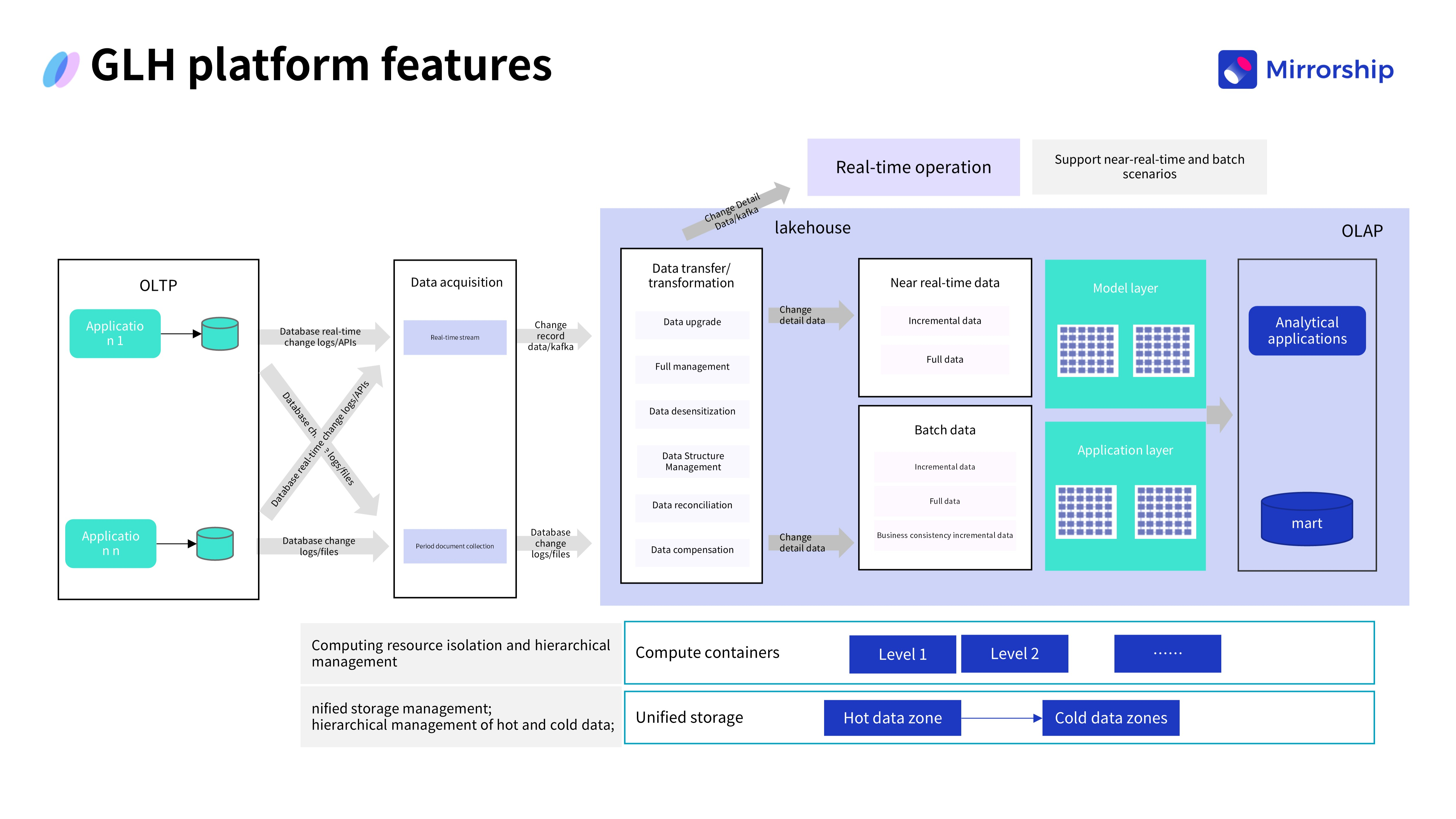
- Архитектура с разделением хранения и вычислений (Shared-Storage): в качестве базового хранилища используется HDFS (с планами миграции на S3), что обеспечивает гибкость для управления ростом данных при контроле затрат и сохранении производительности.
- Использование нескольких моделей таблиц: используя возможности Mirrorship для работы с детализированными (Detail tables) и широкими таблицами (Wide tables), команда разработала кастомные структуры таблиц, поддерживающие анализ временных рядов и отслеживание данных для различных бизнес-задач.
- Унифицированная обработка данных: придерживаясь принципа «сбор один раз, обработка многократно», все данные управляются через единый конвейер обработки. Это позволило избежать дублирования разработки, значительно повысив эффективность и консистентность данных.
- Гибкое распределение данных: платформа поддерживает распределение данных в другие системы через Kafka, что обеспечивает работу сценариев, таких как Flink CDC, и создает открытую, гибкую экосистему.
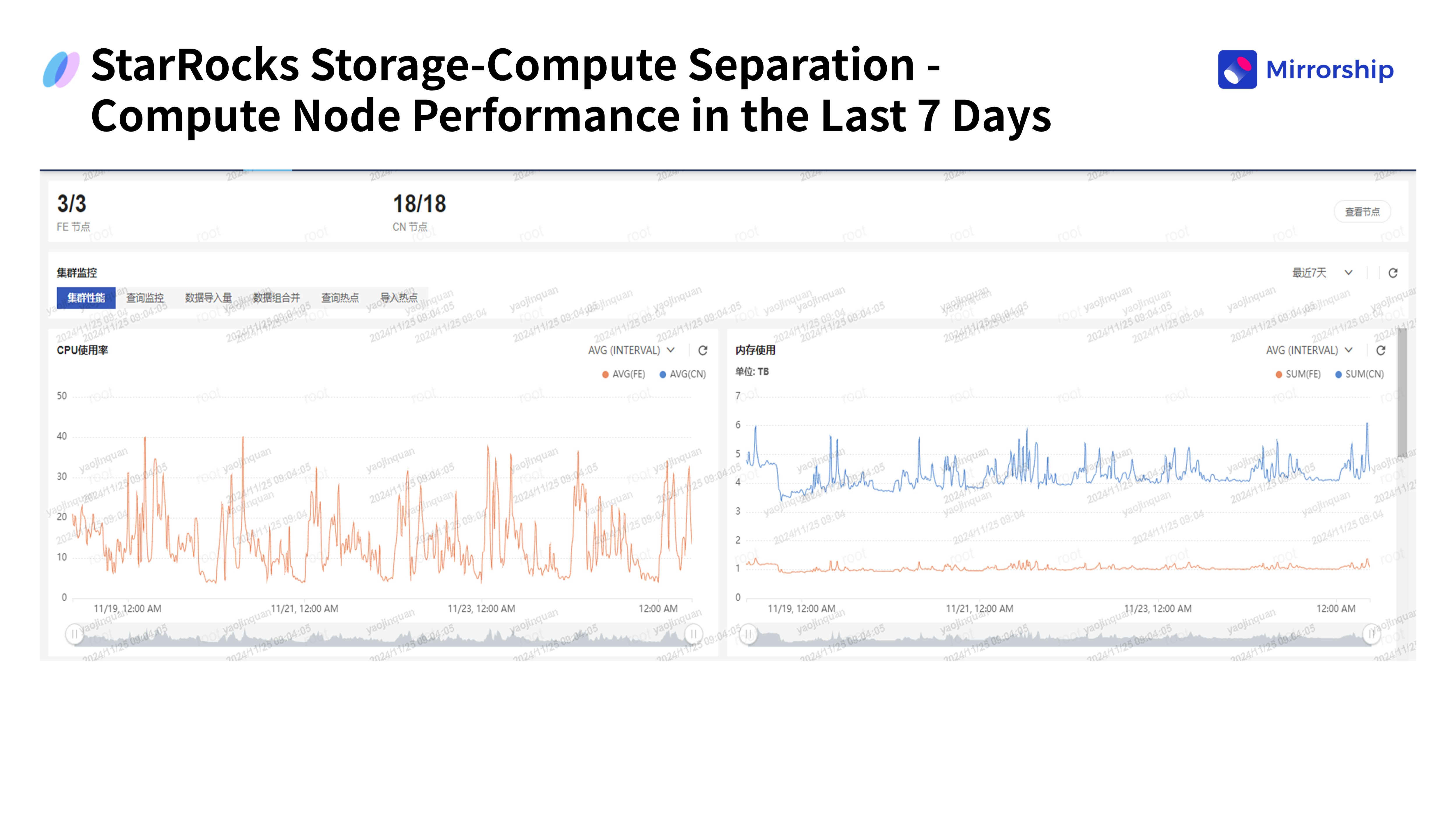
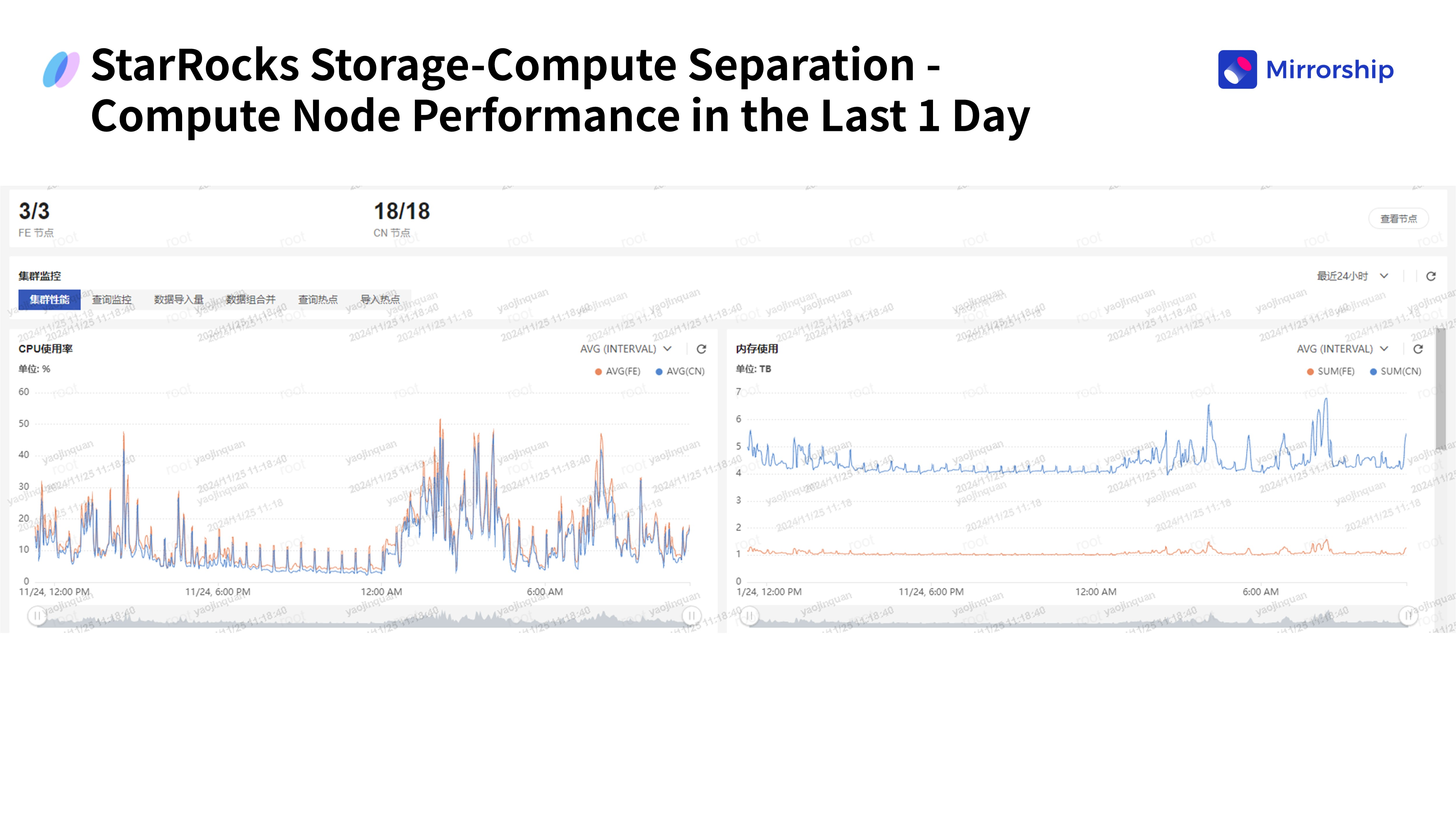
III. Результаты: баланс между производительностью и экономической эффективностью
В ходе внедрения команда накопила ценный опыт:
- Оптимизировали время пакетной обработки: команда применила дифференцированную стратегию синхронизации данных, настраивая интервалы в зависимости от бизнес-потребностей — от 5 секунд для одних таблиц до нескольких минут для других.
- Оптимизировали партиционирование и бакетирование: анализ бизнес-характеристик позволил переработать стратегию партиционирования, чтобы уменьшить накладные расходы на уплотнение (compaction) мелких файлов, что привело к значительному повышению производительности.
- Рационально распределили ресурсы: оптимизировано соотношение ресурсов между вычислительными узлами и узлами хранения. Мониторинг показал, что кластер стабильно работает с загрузкой ЦП ниже 50%, легко справляясь с пиковыми нагрузками.
Бизнес-результаты
Платформа GLH достигла впечатляющих результатов:
- Полный охват данных: более 3800 таблиц из всех бизнес-систем компании подключены к real-time потоку данных.
- Синхронизация на минутном уровне: время от генерации данных до их доступности сократилось до минут, что многократно повысило скорость реакции бизнеса по сравнению с традиционной моделью T+1.
- Увеличение мощности пакетной обработки: платформа обрабатывает более 6500 заданий в день, включая более 800 задач для хранилища данных, со значительным ростом эффективности.
- Углубление интеграции с бизнесом: снято ограничение на выполнение только пакетных запросов, благодаря открытию real-time query API, что позволило бизнес-системам напрямую получать доступ к актуальным данным.
Эти достижения — не просто цифры. Они трансформировались в ускоренную реакцию бизнеса и улучшенный клиентский опыт, внеся ощутимый вклад в повышение конкурентоспособности компании.
IV. Перспективы развития
Платформа GLH завершила разработку основного функционала. Будущее развитие будет сосредоточено на следующем:
- Более открытые интерфейсы: поддержка интеграции с более широким спектром вычислительных и движков хранения.
- Богатая экосистема плагинов: разработка большего количества плагинов для обработки данных.
- Более глубокая интеграция с бизнес-процессами: дальнейшая интеграция с бизнес-системами для предоставления более точных данных.
- Постоянное технологическое развитие: отслеживание развития технологий хранения с запланированной миграцией на объектное хранилище S3.

94 открытий3К показов

BrOk — графический low-code инструмент для управления популярными брокерами сообщений, такими как Kafka, RabbitMQ, Artemis, NATS и Redis. Узнайте, как упростить работу с очередями, шаблонами, сценариями и REST API без лишнего кода.

Новое исследование показало, что ChatGPT и другие ИИ-модели подвержены тем же когнитивным искажениям, что и люди — от переоценки собственных решений до страха перед риском. Разбираемся в деталях.

Как понять, что Excel больше не справляется: признаки, что вашей команде пора внедрять систему автоматизации поддержки

Исследование Tproger: 72% айтишников положительно относятся к ИИ в контенте. Узнайте, как 145 специалистов используют нейросети для генерации кода, идей и картинок, и какие модели предпочитают.