


Персональный ИИ: запускаем Llama и Mistral локально на Mac и Windows


Как запустить Llama и Mistral локально на Mac и Windows: подробное руководство
2К открытий5К показов

Облачные нейросети требуют ежемесячных платежей, имеют лимиты запросов и передают ваши данные через интернет. Локальный ИИ можно развернуть за вечер прямо на своем устройстве.
Запустить Llama или Mistral локально — техническая задача, для решения которой потребуется выбрать подходящую версию, установить специализированное ПО и выполнить базовую настройку параметров.
Разберем процесс по шагам: от выбора модели до тонкой настройки под ваши запросы и требования
Зачем это нужно
Локальный ИИ — инструмент с понятной экономикой и многими плюсами:
- Конфиденциальность — ваши данные никуда не уходят. Обрабатываются внутри вашего устройства. Юридические документы, коммерческая тайна, личная переписка — все остается при вас.
- Независимость от интернета — работайте в поезде, самолете, в сельской местности. Нет разницы, есть связь или нет.
- Финансовая модель — вы платите один раз. В долгосрочной перспективе локальная модель выгоднее платной подписки на облачный сервис.
- Полный контроль — меняйте параметры, экспериментируйте, кастомизируйте. Вы хозяин положения.
Да, пока локальные модели немного медленнее облачных. Но для большинства задач разница незаметна.
Железо: что нужно для работы
Llama и Mistral оптимизированы для потребительского оборудования.
Минимальная конфигурация:
- процессор: Intel i5/Ryzen 5 или новее;
- оперативная память: 16 ГБ;
- свободное место: 20-40 ГБ;
- видеокарта: необязательно, но с GPU работает быстрее.
Рекомендуемая конфигурация:
- память: 32 ГБ ОЗУ;
- видеокарта: NVIDIA с 8+ ГБ VRAM (RTX 3060/4060);
- накопитель: SSD для быстрой загрузки.
Особый случай — Mac с Apple Silicon:
- чипы M1/M2/M3 отлично справляются благодаря унифицированной памяти;
- 16 ГБ на MacBook часто работают лучше 32 ГБ на Windows-машине;
- Neural Engine ускоряет вычисления.
Разница между минимальной и рекомендуемой конфигурацией ощутима. Модели загружаются быстрее, ответы генерируются почти мгновенно.
Выбираем модель: какая подходит именно вам
Llama и Mistral — не конкуренты, а разные инструменты для разных задач.
Llama 3 (Meta) — универсальное решение. Отлично понимает контекст, хорошо справляется с диалогом, кодом, анализом текстов. Модель доступна в размерах 8B (миллиардов параметров) и 70B. 8B-версия — оптимальный старт для большинства задач.

Mistral 7B — компактный и эффективный инструмент. Особенно силён в логических рассуждениях и математике. Создан французскими разработчиками с акцентом на эффективность.

Есть и более крупные версии — Llama 3 70B, Mixtral 8x7B. Они умнее, но требуют в 4-8 раз больше ресурсов.
Золотое правило: начинайте с моделей 7B-8B параметров. Их возможностей хватает для большинства повседневных задач, а требования к железу разумные.
Установка на Windows: подробный разбор
Windows-пользователям доступно больше графических инструментов. Не нужно быть программистом, чтобы запустить локальную модель.
LM Studio — iTunes для нейросетей
Интерфейс LM Studio напоминает привычные программы. Слева — поиск моделей, справа — чат для общения.
Пошаговая установка:
- Качаем установщик с официального сайта.
- Запускаем, принимаем лицензию — стандартная процедура.
- В поиске вводим «Llama 3 8B» или «Mistral 7B».
- Выбираем версию с пометкой «instruct» или «chat» — они лучше всего подходят для диалога.
- Жмём «Download» и ждём 10-30 минут (зависит от скорости интернета).
- После загрузки выбираем модель из списка и нажимаем «Load».
Первый ответ займет 10-30 секунд — модель загружается в память. Дальше будет быстрее.
LM Studio автоматически использует GPU, если он есть в системе. В настройках можно выбрать конкретные устройства для вычислений.
Ollama — инструмент для тех, кто не боится терминала
Ollama работает через командную строку, но очень проста в использовании.
Установка:
- Скачиваем установщик с ollama.com.
- Запускаем, все ставится автоматически.
- Открываем командную строку или PowerShell.
- Вводим ollama run llama3:8b для Llama или ollama run mistral:7b для Mistral.
Ollama сама скачает модель и запустит интерактивный режим.
Преимущества Ollama:
- лёгкое управление моделями: ollama list показывает установленные версии, ollama rm имя_модели удаляет ненужные;
- работа в фоне как сервис;
- простое подключение через API для разработчиков
Ollama — отличный выбор, если планируете интегрировать модель в свои скрипты или приложения.
GPT4All — максимальная приватность
GPT4All создан с упором на конфиденциальность. Модели оптимизированы для работы на CPU.
Установка стандартная: скачали, установили, выбрали модель из встроенного каталога. Интерфейс напоминает упрощенный ChatGPT.
Особенность GPT4All — акцент на оффлайн-работе. Минимальная зависимость от облачных сервисов даже на этапе установки.
Установка на Mac: проще не бывает
На Mac процесс еще проще благодаря оптимизации под Apple Silicon.
Ollama — король на Mac
Ollama идеально использует архитектуру M-чипов. Neural Engine ускоряет вычисления, унифицированная память позволяет работать с большими моделями.
Установка:
- Качаем.dmg файл с официального сайта
- Перетаскиваем в папку «Программы»
- Открываем Terminal
- Вводим ollama run mistral:7b
Модель скачается и запустится. На M1/M2 с 16 ГБ памяти Mistral летает.
Альтернатива — установка через Homebrew: brew install ollama
LM Studio — красота и функциональность
Версия LM Studio для Mac ничем не уступает Windows-собрату. Та же простота установки, тот же интуитивный интерфейс.
Особенность Mac-версии — лучшая интеграция с системой. Меньше нагрузка на батарею, эффективное использование памяти.
После установки просто выбираем модель из списка, жмем «Load» и общаемся.
Сравнение инструментов: что выбрать
Вот объективная картина по основным программам:
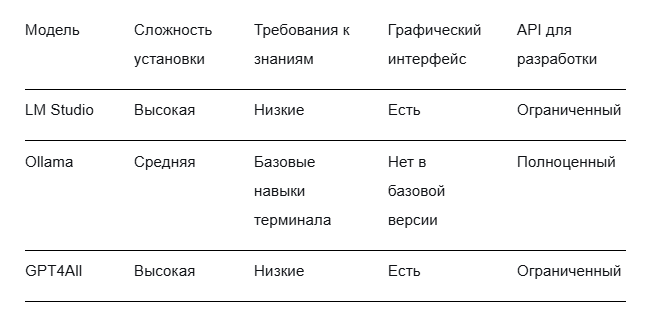
LM Studio — лучший выбор для новичков. Установил, скачал модель, начал общ аться.
Ollama — идеальна для разработчиков и тех, кто планирует использовать модели в скриптах.
GPT4All — максимальный акцент на приватности.
Первый запуск и настройка параметров
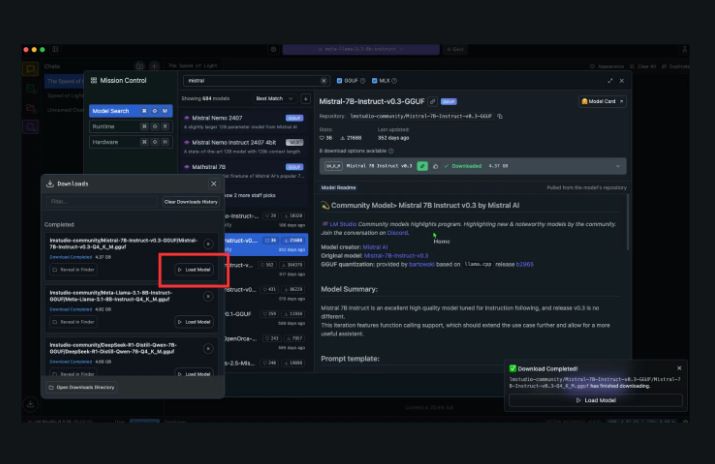
Модель запустилась. Теперь нужно настроить её для эффективной работы. Основные параметры управления генерацией текста:
- temperature (температура) — от 0.1 до 1.0, где низкие значения дают предсказуемые ответы, а высокие увеличивают креативность;
- top-p — вероятность охвата токенов от 0 до 1, где 0.9 обеспечивает баланс между качеством и разнообразием;
- max tokens — ограничение длины ответа в токенах, где 2048-4096 подходит для большинства задач;
- system prompt — системная инструкция, определяющая поведение модели;
- frequency penalty — снижает частоту повторяющихся фраз при значении от 0.1 до 1.0.
Конкретные настройки для разных задач:
Для программирования и технических вопросов:
- temperature: 0.1-0.3;
- top-p: 0.9;
- max tokens: 2048;
- system prompt: «Ты — опытный программист, дающий точные технические ответы».
Для творческих задач и мозгового штурма:
- temperature: 0.7-0.9;
- top-p: 0.95;
- max tokens: 4096;
- system prompt: «Ты — креативный помощник, генерирующий разнообразные идеи».
Для анализа документов и суммаризации:
- temperature: 0.3-0.5;
- top-p: 0.85;
- max tokens: 3072;
- frequency penalty: 0.5.
Где находятся настройки:
- в LM Studio: вкладка «Model Settings» в основном интерфейсе;
- в Ollama: через модификаторы команды ollama run, например --temperature 0.3;
- в GPT4All: раздел «Generation Settings» в меню настроек.
Начните со стандартных значений, затем адаптируйте под конкретные задачи. Сохраняйте удачные конфигурации для повторного использования.
Работа с документами: даем модели доступ к вашим файлам
Самая мощная фича локальных моделей — работа с вашими документами. Технология называется RAG (Retrieval-Augmented Generation).
Как это работает:
- Программа индексирует ваши файлы (PDF, DOCX, TXT).
- Когда вы задаете вопрос, система ищет релевантные фрагменты.
- Эти фрагменты передаются модели вместе с вашим вопросом.
- Модель отвечает на основе ваших данных.
В LM Studio есть встроенная функция «Chat with Your Documents». Просто указываете папку с файлами, программа их индексирует, и вы можете задавать вопросы по вашим документам.
Пример:
Ваш вопрос: «Какая ответственность предусмотрена за нарушение пункта 5.1 нашего договора?»
Что видит модель: «Основываясь на этом тексте: [фрагмент вашего договора], ответь на вопрос: Какая ответственность предусмотрена за нарушение пункта 5.1 нашего договора?»
Модель не галлюцинирует, а ссылается на конкретные фрагменты ваших документов.
Дообучение: делаем модель специалистом
Хотите, чтобы модель говорила определенным стилем или знала специфичную информацию? Поможет дообучение.
LoRA (Low-Rank Adaptation) — эффективный метод, который не переобучает всю модель, а добавляет небольшую «надстройку». Требует технических знаний и мощной видеокарты.
Простой способ — использование RAG, описанного выше. Модель не запоминает новые знания, но имеет к ним доступ.
Сложный способ — полноценное дообучение на своих данных. Требует подготовки датасета в формате «вопрос-ответ» и вычислительных ресурсов.
Для большинства пользователей достаточно RAG. Дообучение нужно для очень специфичных задач.
Типичные проблемы и их решения
При первом запуске локальных моделей часто возникают сложности. Разберем их причины и конкретные шаги для решения.
Проблема: нехватка памяти
Симптомы: Модель не загружается; приложение или система зависают; появляются сообщения об ошибках памяти.
Почему это происходит: Модели 7B-8B параметров требуют значительного объема оперативной памяти (ОЗУ) для работы. Фоновые приложения, особенно браузеры с множеством вкладок, могут исчерпывать доступные ресурсы.
Что делать:
- Закройте ресурсоемкие приложения, в первую очередь браузеры.
- Проверьте диспетчер задач (Windows) или Activity Monitor (Mac) на наличие процессов, потребляющих память.
- Выберите модель с квантованием — в названии ищите маркеры q4_k_m, q5_k_m, q8_0.
- Чем меньше число после q, тем меньше модель, но может незначительно снизиться качество ответов.
- Для начала используйте q5-версии — это оптимальный баланс между размером и производительностью.
Проблема: медленная генерация ответов
Симптомы: Модель думает несколько минут над коротким ответом; интерфейс подолгу не реагирует.
Почему это происходит: Система использует только центральный процессор (CPU), который значительно медленнее графического (GPU) или специализированных ядер (например, Neural Engine на Mac) для таких задач.
Что делать:
- В LM Studio: Откройте Settings → Model → GPU Offload и передвиньте ползунок вправо.
- В Ollama: Система обычно автоматически использует доступные ресурсы. Проверить загрузку можно командой ollama ps.
- На Mac с чипом M: Убедитесь, что используется Neural Engine — это происходит по умолчанию в большинстве приложений.
- Использование GPU вместо CPU ускоряет генерацию в 2-5 раз.
Проблема: модель не загружается или вылетает
Симптомы: Приложение зависает при загрузке модели, появляется сообщение об ошибке загрузки файла.
Почему это происходит: Файл модели мог скачаться не полностью или повредиться. Архив модели весит 4-8 ГБ, и любое прерывание сети нарушает его целостность. Иногда конкретная версия модели может конфликтовать с оборудованием.
Что делать:
- Удалите модель из списка в приложении (LM Studio) или через команду ollama rm <имя_модели>.
- Скачайте и установите модель заново.
- Убедитесь, что на системном диске достаточно свободного места для распаковки и работы с моделью.
- Попробуйте другую, более стабильную версию той же модели, например, официальную сборку от создателей, а не пользовательскую.
Проблема: странные или бессмысленные ответы
Симптомы: Модель генерирует бессвязный текст, не следует инструкциям или отвечает на языке, отличном от запроса.
Почему это происходит: Возможно, вы используете базовую (base) версию модели, а не инструктивную (instruct). Базовые модели не оптимизированы для диалога. Слишком высокий параметр Temperature делает ответы случайными и непредсказуемыми.
Что делать:
- Всегда выбирайте instruct- версии моделей (например, Llama 3 8B Instruct). Они специально дообучены для понимания и выполнения инструкций.
- Проверьте настройки генерации. Установите Temperature (температуру) в диапазоне 0.1–0.3 для точных задач (код, факты) и 0.7–0.9 для творческих.
- Четко формулируйте системный промпт (например: «Ты — полезный ассистент. Отвечай точно и по делу»).
Проблема: ошибки совместимости на Windows
Симптомы: LM Studio или Ollama не видят GPU; при попытке использовать GPU возникают ошибки.
Почему это происходит: Устаревшие драйверы видеокарты NVIDIA; отсутствие поддержки необходимых технологий (CUDA) на старом оборудовании; блокировка антивирусом.
Что делать:
- Обновите драйверы видеокарты NVIDIA до последней версии с официального сайта.
- Для устаревших GPU, которые не поддерживают современные версии CUDA, используйте CPU-версии моделей или ищите сборки с устаревшей поддержкой CUDA.
- Добавьте папки с приложениями (LM Studio, Ollama) в исключения вашего антивируса.
Где искать помощь
Большинство проблем уже встречались у других пользователей.
- Сообщества на Reddit. Сабреддиты r/LocalLLaMA и r/Ollama — это живые форумы, где можно найти обсуждения практически любой проблемы и ее решения.
- Форум Hugging Face. На странице конкретной модели часто есть обсуждение, где пользователи делятся опытом запуска.
- GitHub Issues. Исходные репозитории инструментов (Ollama, LM Studio, llama.cpp) — здесь разработчики дают технические консультации по ошибкам.
- Habr. На платформе есть тематические посты с разбором ошибок и тонкостей настройки локального ИИ.
При поиске помощи всегда указывайте точное название модели, инструмент, который вы используете, и полный текст ошибки.
Практическое применение: что можно делать прямо сейчас
Локальные модели — рабочий инструмент.
- Обработка документов — суммаризация договоров, анализ отчетов, извлечение ключевых пунктов. Конфиденциально и бесплатно.
- Помощь в программировании — объяснение кода, генерация простых функций, поиск багов. Llama особенно сильна в кодировании.
- Образование — бесконечное терпеливое объяснение сложных тем. От дифференциальных уравнений до квантовой физики.
- Творчество — генерация идей и текстов, мозговые штурмы.
- Персональный ассистент — планирование, анализ, организация информации.
Пользователи применяют локальные модели для всего — от анализа юридических документов до стихосложения.
Безопасность и ограничения
Локальные модели безопаснее облачных — ваши данные никуда не уходят. Но есть нюансы.
- Конфиденциальность — полная. Модель работает на вашем устройстве. Данные не отправляются на серверы.
- Качество ответов — локальные модели иногда уступают топовым облачным в сложных задачах. Но для большинства повседневных нужд разница незаметна.
- Технические ограничения — самые большие модели требуют серьезного железа. 70B-версии сложно запустить на ноутбуке.
Llama 3 включает встроенные механизмы безопасности — Llama Guard и Code Shield, которые фильтруют небезопасный контент и код.
Развиваем навыки работы с локальным ИИ
Первый запуск — только начало:
- Экспериментируйте с разными моделями — каждая имеет свои сильные стороны. Попробуйте специализированные версии для программирования, математики, творчества.
- Изучайте продвинутые инструменты — llama.cpp для максимальной производительности, текстовые генераторы с дополнительными функциями.
- Осваивайте тонкую настройку — учитесь правильно формулировать промпты, настраивать параметры генерации.
Сообщество вокруг локального ИИ активно развивается. На форумах и в специализированных чатах можно найти единомышленников и решения сложных проблем.
Итоги: как использовать локальные ИИ
Вы установили инструмент и запустили модель. Теперь нужно интегрировать ее в рабочий процесс.
Начните с простых задач:
- проверка и комментирование кода;
- суммаризация длинных текстов;
- перевод технической документации;
- генерация шаблонного контента.
Освойте базовые приемы работы:
- четко формулируйте запросы;
- задавайте контекст в начале диалога;
- разбивайте сложные задачи на простые;
- используйте системные промпты для определения стиля ответов.
Для программистов: локальные модели заменяют поиск в интернете для стандартных задач. Генерация boilerplate-кода, объяснение функций, поиск ошибок в синтаксисе.
Для работы с текстами: модели справляются с анализом документов, выделением ключевых пунктов, перефразированием.
Тестируйте разные модели под конкретные задачи. Mistral часто лучше справляется с логическими цепочками, Llama — с кодом и развернутыми объяснениями.
Периодически обновляйте инструменты и модели. Разработчики выпускают оптимизированные версии, улучшающие производительность.
Сохраняйте реалистичные ожидания. Модели на 7-8 миллиардов параметров не заменят облачные решения в сложных сценариях, но покрывают большинство повседневных нужд.
При возникновении проблем обращайтесь к сообществу. Форумы по локальному ИИ содержат решения для типичных ситуаций — от нехватки памяти до специфических ошибок загрузки.
Документируйте успешные промпты и настройки. Это сэкономит время при решении повторяющихся задач.
Локальный ИИ работает как любой другой инструмент в вашем арсенале. Его эффективность зависит от понимания возможностей и ограничений.

2К открытий5К показов

Как наняли сотрудников редакции с помощью мемов, много про разработку с примерами и про аналитическую систему.

Аналитик Минг-Чи Куо утверждает, что MacBook с гибким экраном появится уже в 2027 году

Наряд для встречи 2026-го уже ждёт тебя в виртуальной примерочной!

Подробное сравнение Serverless и Kubernetes: архитектура, масштабирование, стоимость, безопасность. Какой подход выбрать для MVP, high-load и гибридных приложений?