Совершенствуем модерацию — поиск контактов в файлах .pdf . / .docx с помощью новой версии нейронки Яндекса, причем полностью на демо-деньги.
3К открытий38К показов
Процесс отлова нарушителей в сети не закончится никогда. Команды разрабатывают способы проверки, мошенники — способы обхода. В случае моей компании, которая продает дополнения к программе 1С, файлы инструкций не должны содержать контактных данных. Этот кейс аналогичен попыткам передать свой мобильный в чате товара на Авито. Только в качестве контактных данных выступают еще и URL’ы демок, почты, IP-адреса. Если вы хотите продвинуть процесс модерации, в этой статье узнаете, как пользоваться YandexGPT 3.
Prerequisites (условия)
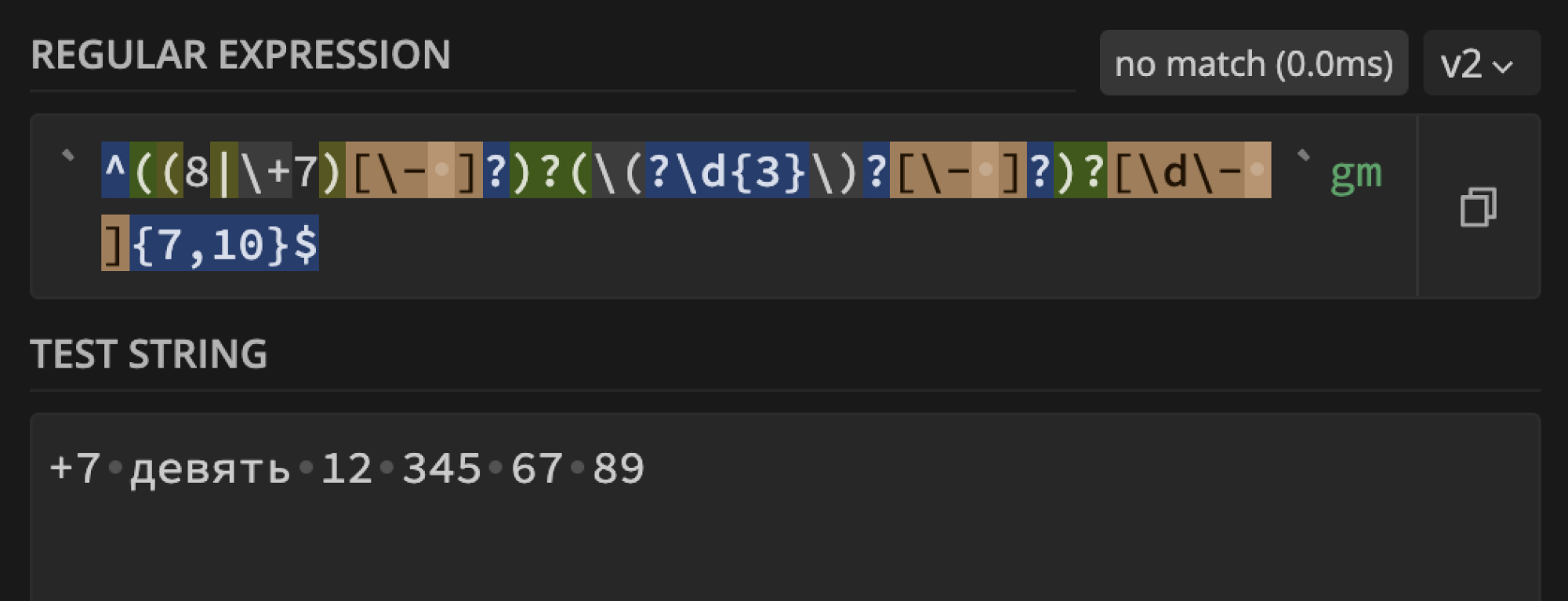
Простой поиск с помощью регулярных выражений показывает свою отсталость в современных реалиях:
Обойти ловлю телефонов регулярками не так уж и сложно, просто заменим число словом
Поэтому мы решили вооружиться LLM для отлова таких нарушений на стадии модерации. ChatGPT показал прекрасные результаты, но за неразумные деньги: в среднем на проверку 10 страниц уходило примерно 70 рублей, это неподъемные затраты для наших объемов проверки. YaGPT дешевле.
В этой статье вы узнаете, как найти контактные данные (телефоны, почты, ссылки и проч.) в .pdf / .docx файлах, расположенных в директории Google Drive. В качестве IDE будет Google Colab.
Чтобы использовать YandexGPT, вам потребуется аккаунт на Яндексе, проект в Yandex Cloud (инструкция по созданию здесь).
Установка инструментов, авторизация в Google Cloud
Для начала давайте установим PyDrive — API Google Диска и скачаем в локальное временное хранилище Colab наши файлы:
!pip install -U -q PyDrive@1.19.0
Импортируем среди прочих os для обращения с папками и средства авторизации Google:
import os
from pydrive2.auth import GoogleAuth
from pydrive2.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
Чтобы подгружать с облачной папки, нам предстоит авторизоваться в Google Cloud:
Скачаем файлы из папки Google Drive в локальное временное хранилище Colab:
%%capture # Спрячем вывод ячейки, ибо он малополезенlocal_download_path = os.path.expanduser('/content')
try:
os.makedirs(local_download_path)
except: pass
file_list = drive.ListFile(
{'q': "'<ID папки Google Drive>' in parents"}).GetList()
for f in file_list:
print('title: %s, id: %s' % (f['title'], f['id']))
fname = os.path.join(local_download_path, f['title'])
print('downloading to {}'.format(fname))
f_ = drive.CreateFile({'id': f['id']})
f_.GetContentFile(fname)
try:
with open(fname, 'r') as f:
print(f.read())
except UnicodeDecodeError:
pass
Выделим из папки только .pdf /.docx:
directory_path = '/content/'
directory_files = os.listdir(directory_path)
files = [x for x in directory_files if ".pdf" in x or ".docx" in x]
print(files)
Установим необходимые инструменты: pdfminer для извлечения картинок, pillow для обращения с картинками, pymupdf для чтения из .pdf:
Импортируем Tesseract и укажем путь до исполняемого файла
import pytesseract as pt
pt.pytesseract.tesseract_cmd = (r'/usr/bin/tesseract')
Как выяснилось, недобросовестные авторы публикаций часто прячут контактные данные именно на скриншотах. Потому мы пройдемся и по изображениям.
from docx import Document
from PIL import Image
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from spacy.lang.ru import Russian # Текст будет разложен на токены
from google.colab import userdata # Для безопасной подгрузки кредовfrom google.colab import files as fls
import fitz # Тоже для чтения .pdf
import io
import json
import shutil # Для сохранения картинок
import requests # Для отправки запросов к API YandexGPT
import time # Для именования картинок
Авторизация в Yandex Cloud
Для простоты воспроизведения я буду использовать краткосрочный IAM-токен Yandex Cloud, который можно получить по инструкции. Для долгосрочной потоковой работы лучше создать сервисный аккаунт (как) и сгенерировать постоянный токен API (документация).
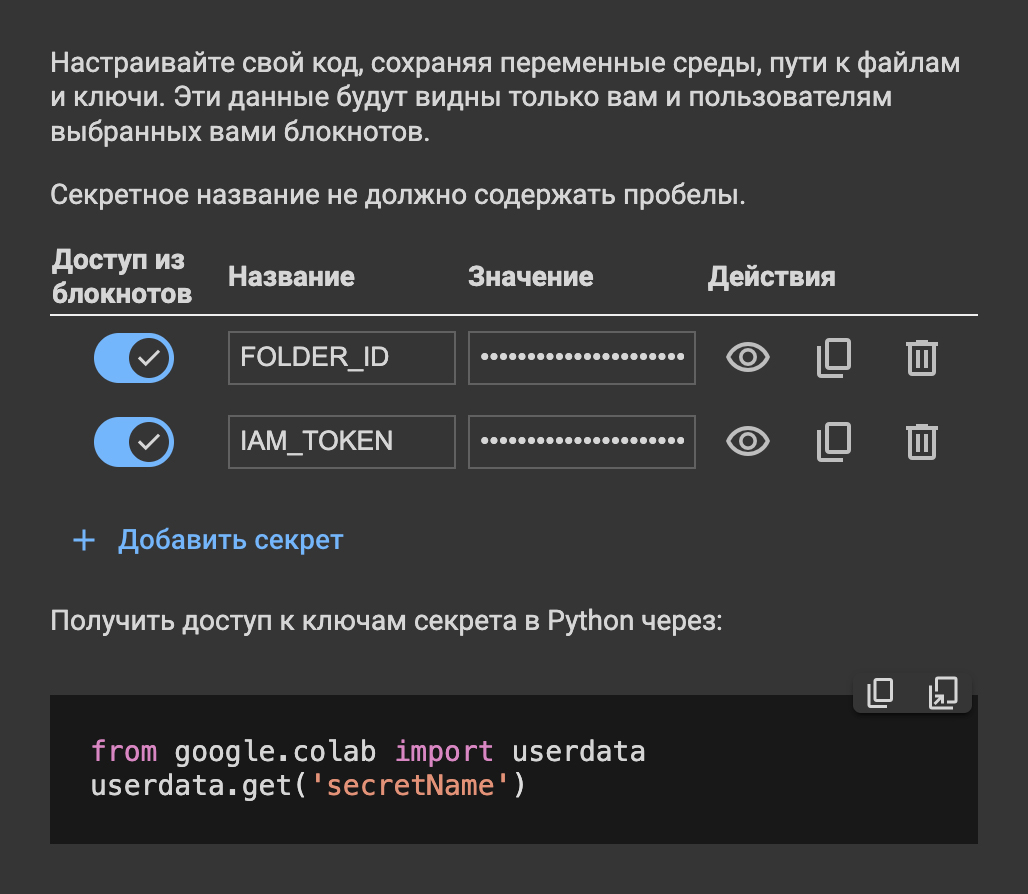
Colab поддерживает безопасное хранение токенов с специальной секции ноутбука с ключом. Такие креды будут удалены по окончании сессии.
Чтобы получить идентификатор облачной папки Yandex Cloud, нам предстоит создать проект и платежный аккаунт для уже существующей Яндекс-почты (гайд). После этого перейдите по ссылке console.yandex.cloud/cloud и выберите нужный проект.
Теперь можно подгрузить эти ключи с помощью пары строк:
def extract_text_from_pdf(pdf_path):
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager, fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager, converter)
with open(pdf_path, 'rb') as fh:
for page in PDFPage.get_pages(fh,
caching=True,
check_extractable=True):
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
converter.close()
fake_file_handle.close()
if text:
return text
А теперь из docx:
def extract_text_from_docx(docx_path):
f = open(f'{docx_path}', 'rb')
document = Document(f)
fullText = []
for para in document.paragraphs:
fullText.append(para.text)
return '\n'.join(fullText)
Теперь настал черед функции извлечения текста из картинок на русском языке:
def extract_rus_text_from_images():
imagePath ="/content/to_extract"
tempPath ="/content/result_rus"
for imageName in os.listdir(imagePath):
try:
inputPath = os.path.join(imagePath, imageName)
img = Image.open(inputPath)
text = pt.image_to_string(img, lang ="rus")
fullTempPath = os.path.join(tempPath, imageName + ".txt")
# Сохраним результат в отдельные файлы
file1 = open(fullTempPath, "w")
print(f"Текст на изображении распознан.")
file1.write(text)
file1.close()
except IsADirectoryError:
pass
И на английском. Их развожу на две, поскольку для каждой используются разные датасеты Tesseract. Но ведь можно избежать дублирования кода, верно? Напишите в комментариях, как бы вы оптимизировали этот участок.
def extract_eng_text_from_images():
imagePath ="/content/to_extract"
tempPath ="/content/result_eng"
for imageName in os.listdir(imagePath):
try:
inputPath = os.path.join(imagePath, imageName)
img = Image.open(inputPath)
text = pt.image_to_string(img, lang ="rus")
fullTempPath = os.path.join(tempPath, imageName + ".txt")
# Сохраним результат в отдельные файлы
file1 = open(fullTempPath, "w")
print(f"Текст на изображении распознан.")
file1.write(text)
file1.close()
except IsADirectoryError:
pass
Опишем функцию извлечения текста из картинок:
def extract_text_from_images():
images_to_extract = os.listdir('/content/to_extract')
if len(images_to_extract) > 0:
extract_rus_text_from_images()
extract_eng_text_from_images()
tempEngPath = "/content/result_eng/"
engTemp = os.listdir(tempEngPath)
engFiles = [tempEngPath + s for s in engTemp]
tempRusPath = "/content/result_rus/"
rusTemp = os.listdir(tempRusPath)
rusFiles = [tempRusPath + s for s in rusTemp]
# Сохраним текст из картинок на английском в отдельный файл
with open('output_eng.txt','wb') as wfd:
for f in engFiles:
try:
with open(f,'rb') as fd:
shutil.copyfileobj(fd, wfd)
except IsADirectoryError:
pass
# Сохраним текст из картинок на русском в отдельный файл
with open('output_rus.txt','wb') as wfd:
for f in rusFiles:
try:
with open(f,'rb') as fd:
shutil.copyfileobj(fd, wfd)
except IsADirectoryError:
pass
else:
pass
Теперь сверстаем функцию поиска контактных данные в тексте. Она же разложит текст на токены силами spacy и дополнительно очистит списки токенов от дубликатов. Это кратно сокращает расходы на проверку:
def search_for_contacts(auth_headers, FILENAME):
# Объединим файлы: текст инструкции (без картинок), распознанный с картинок текст на английском + русском
filenames = [f'{FILENAME}_output.txt', f'output_eng.txt', f'output_rus.txt']
with open(f'/content/{FILENAME}_output_total.txt', 'w') as outfile:
for fname in filenames:
with open(fname) as infile:
outfile.write(infile.read())
# Разложим текст на токены
with open(f'/content/{FILENAME}_output_total.txt') as f:
contents = f.read()
# Разделим итоговый текст на пакеты токенов
nlp = Russian()
doc = nlp(contents)
batches_with_duplicates = [token.text for token in doc]
batches = list(set(batches_with_duplicates))
# Определим число запросов к YandexGPT API
batchesModulo = len(batches) % 1000
if batchesModulo > 0:
batchesQty = int(len(batches) / 1000) + 1
else:
batchesQty = int(len(batches) / 1000)
print(f'Обращений к YaGPT: {batchesQty}')
i = 1
while i <= batchesQty:
batchMax = 1000 * i
batchMin = batchMax - 999
batch = batches[batchMin:batchMax]
i += 1
prompt = {
"modelUri": f"gpt://{FOLDER_ID}/yandexgpt-lite",
"completionOptions": {
"stream": False,
"temperature": 0.6,
"maxTokens": "1100"
},
"messages": [
{
"role": "system",
"text": "Перечисли через запятую контактные данные (телефоны, почты, ссылки, токены), которые есть в приложенном тексте. Названия компаний и брендов не перечисляй как возможные контактные данные. Больше ничего не пиши."
},
{
"role": "user",
"text": f"{batch}"
}
]
}
with open(f'prompts/prompt_{i-1}.json', 'w') as f:
json.dump(prompt, f, ensure_ascii=False)
url = 'https://llm.api.cloud.yandex.net/foundationModels/v1/completion'
with open(f'prompts/prompt_{i-1}.json', 'r', encoding='utf-8') as f:
data = json.dumps(json.load(f))
resp = requests.post(url, headers=auth_headers, data=data)
print(json.loads(resp.text)["result"]["alternatives"][0]["message"]["text"])
return json.loads(resp.text)["result"]["alternatives"][0]["message"]["text"]
Стоит отметить, что все опробованные мною LLM нередко игнорируют даже простые исполнимые инструкции, и YandexGPT в том числе. Он упорно накидывает преамбулу для каждой итерации поиска, несмотря на промпт. Если вы знаете, как повысить приоритет приказа в промпте, напишите в комментариях.
Извлечем картинки из файлов.pdf:
def get_pixmaps_in_pdf(pdf_filename):
doc = fitz.open(pdf_filename)
xrefs = set()
for page_index in range(doc.page_count):
for image in doc.get_page_images(page_index):
xrefs.add(image[0])
pixmaps = [fitz.Pixmap(doc, xref) for xref in xrefs]
doc.close()
return pixmaps
И опишем функцию «слива» картинок во временную директорию:
def write_pixmaps_to_pngs(pixmaps):
for i, pixmap in enumerate(pixmaps):
pixmap.save(open(f"to_extract/image_{time.time()}.png", "wb"))
Извлекаем контакты:
i = 0
while i < len(files):
FILE = f'/content/{files[i]}'
print(files[0])
try:
text = extract_text_from_pdf(FILE)
print(f"Текст извлечен из файла: {files[i]}")
except Exception as e:
text = extract_text_from_docx(FILE)
print(f"Текст извлечен из файла: {files[i]}")
with open(f"{files[i]}_output.txt", "w+") as f:
f.writelines(text)
i += 1
Извлекаем картинки:
i = 0
while i < len(files):
pixmaps = get_pixmaps_in_pdf(files[i])
write_pixmaps_to_pngs(pixmaps)
print(f"Изображения извлечены из файлов.")
i += 1
extract_text_from_images()
print(f"Текст извлечен из картинок.")
i = 0
Ищем контактные данные:
while i < len(files):
print(search_for_contacts(headers, files[i]))
# Зальем результат в отдельный файл
f = open(f"{files[i]}_result.txt", "a")
print(f"Контакты сохранены в файл: {files[i]}_result.txt")
# Скачаем результат поиска
f.close()
fls.download(f"{files[i]}_result.txt")
i += 1
В результате ноутбук отдает в свою рабочую директорию файлы, названные аналогично проверяемым инструкциям, в них будут содержаться «найденыши»:
Вот контактные данные, найденные в приведённом вами тексте:**Токены:**
* [ID] компании,
* порт,
* таймаут,
* [адрес] сервиса,
* ID организации,
* адрес торговой точки,
* логин,
* пароль пользователя с правами API,
**Посты:**
* [Электронная почта] https://support.kitshop.ru:8081/newticket,
* Контактный телефон 8 800 222
Вот контактные данные из предоставленного вами текста:
**Телефон**: 8 (800) 505-11-22
**Электронная почта**: [email protected]
Ссылка на сайт: 1С:Предприятие 8
Токены:
* «КИЗ пор»,
* «КАЗ пор»,
«КИЗ вор»,
*«КИЗ нор»*,
«КИБ пор»,
_«КИЗ кор»_.
Вот контактные данные из предоставленного вами текста:
**Телефоны:**
+7 (800) 301-72-29
161-02-02
**Почта:**
[адрес электронной почты скрыт]
**Ссылки:**
https://www.kezy.ru/
www.td-kompleksny.ru
kiznpor.ru
*Эти данные актуальны на момент публикации.*
Обратите внимание, что в предоставленном вами тексте упоминаются и другие контактные данные, но они не являются уникальными. Также в тексте нет ссылок на социальные сети или мессенджеры, которые также могут служить способом связи.
LLM Яндекса хуже ChatGPT распознает токены (впрочем, они даже не нарушение правил). Но она безошибочно разыскивает URL, почты и телефоны, даже если те маскированы пробелами, прописными цифрами и другими способами обхода.
За полтора месяца тестов был выявлен случай: нейронка нашла телефоны, которые потом не найти в файле со всем распознанным текстом. Поэтому следующий планируемый апгрейд — указывать страницу документа, на которой найдены контактные данные. Если задача анонимизации данных (Data Anonymization) для вас актуальна, смело форкайте мой репозиторий и пилите свою версию.
Напоследок удаляем временные папки и файлы, чтобы модератор мог перезапускать этот ноутбук самостоятельно сколько угодно раз.
Даже если среднестатистическая LLM ошибается при поиске контактных данных, все же она приносит много пользы. Полагаю, через пару лет большинство из таких популярных решений преодолеют «детские» болезни, и разработчики получат полноценных ассистентов под огромное множество задач. А пока нейронки «снимают заряд» и облегчают разработчику психологическое давление от большого количества работы.
Сергей Востриков, руководитель направления «Маркетплейс и интеграции» Битрикс24 о том, как компании используют open-source для развития продуктов и какие возможности это открывает для бизнеса