


Популярные ошибки в Golang и как их избежать
Дмитрий Королев расскажет про распространённые ошибки при работе со слайсами, каналами и другими структурами в Go. Научимся предупреждать их и справлять на примерах.
2К открытий11К показов

Всем привет! Меня зовут Дмитрий Королёв, я бэкенд-разработчик в Авито.
Go известен своей лаконичностью и простотой синтаксиса, но даже в нём есть множество подводных камней, с которыми можно столкнуться в работе. В этой статье я сделаю разбор распространённых ошибок с примерами и расскажу, как их можно избежать.
Массивы и слайсы
Начнём с базовых концепций:
- Массив — последовательность элементов определённого типа и фиксированной длины. Это неизменяемая структура данных и его capacity всегда равна его длине.
- Слайс — своеобразная надстройка поверх массива с возможностью изменения длины.
Распространённые ошибки при работе со слайсами
Чтобы понять, как работают слайсы, нужно понимать их структуру. В коде ниже видны поля про длину и вместимость и указатель на массив, на основе которого построен слайс.
Про длину и capacity слайсов стоит помнить две вещи:
- Когда мы создаём новый слайс, его длина равна его capacity, если не указано другое.
- Как именно растет вместимость слайса начиная с версии go 1.20.
Поскольку в Go все аргументы передаются в функции по значению, то при передаче слайсов в качестве аргумента передаётся значение его структуры. Иными словами, копируется только ссылка на массив, на основе которого построен слайс. Сам массив со всеми содержащимися в нём данными не копируется. Если этого не знать, можно получить неожиданный результат.
Дальше рассмотрим примеры.
Перевыделения памяти под новый массив
Здесь в main объявлен слайс, состоящий из одного нуля. После чего этот слайс передаётся в функцию с говорящим названием changeSliceValues. Там с ним происходят некие действия, в текущем примере в нулевой индекс записывается единица. Если в main вывести слайс на экран до и после вызова функций, то ожидаемо увидим [0] и [1] соответственно.
Теперь немного изменим пример — в changeSliceValues после записи в нулевой индекс с помощью append добавим в конец слайса 2, после чего запишем в нулевой индекс 3. И несмотря на применённые нами изменения, принты в main все так же выведут [0] и [1]. Размер слайса не изменился, несмотря на то, что мы добавили append. Вторая запись тоже не применилась.
На самом деле всё станет понятно, если вспомнить озвученные ранее факты о слайсах и структуру слайса. В самом начале мы создали слайса с длинной, которая равна его capacity, то есть единице.
В момент вызова changeSliceValues в качестве аргумента передаётся значение структуры слайса. Он указывает на тот же самый нижележащий массив, что и слайс в main. По этой причине первая запись на нулевом индексе применяется на изначальном массиве, который был создан при инициализации слайса в main.
Однако дальше, когда мы делаем append, поскольку у слайса длина равна capacity, происходит перевыделение памяти под новый массив. Туда эвакуируются все значения из старого, и дальнейшая работа с этим слайсом уже на изначальный слайс в main не оказывает никакого эффекта.
Следующая запись в нулевой индекс происходит опять же на новый массив. На изначальный массив, который был создан при объявлении слайса в main, это никак не влияет.
Копирование слайсов
С этой же проблемой можно столкнуться, если попытаться скопировать слайс.
В примере в переменную newSlice с помощью слайсинга копируются данные из оригинального слайса, в том числе и указатель на массив с данными. При выполнении append данные перетираются в оригинальном массиве, потому что newSlice указывает на оригинальный массив из первого слайса.
В Go есть специальная встроенная функция copy, которая позволит безопасно копировать любые слайсы.
На картинке выше видно, что, использовав copy, мы перенесли элементы из исходного слайса в новый. Теперь можно безопасно делать append, не боясь перетереть изначальные данные.
Работа со строками и рунами
Допустим мы хотим парсить какой-то новостной портал и для каждой новости класть в кэш первые сто символов, чтобы показывать пользователю превью.
В бесконечном цикле мы получаем новые новости, после берём первые сто рун и отдаём в некую функцию storeArticlePreview, которая заботится о том, чтобы сохранить руны в кэш.
Однако, проблема в том, что когда сервис запустится, он будет съедать намного больше оперативной памяти, чем планировалось, потому что в нём есть утечка. Операция получения первых ста рун от новости создаёт срез длиной в сто элементов, но его capacity остаётся такой же, как у изначального слайса. В итоге весь массив с текстом новости остаётся лежать в памяти, даже если в итоге мы имеем доступ только к первым ста элементам.
Кстати, почему в этом примере мы скастили строку к массиву рун, прежде чем брать от неё первые 100 символов? Покажу на примере, чем отличаются руны от байтов.
Берём стандартную строку Hello World и делаем отдельную переменную с рунами. По задумке хотим запринтить первые пять символов, то есть слово Hello.
Если посмотреть на вывод, то не в нем не будет ничего необычного. Сначала принтятся сами руны, потом, когда мы конвертируем это в строку, выводится слово Hello. Когда берём первые пять элементов от строки, снова выводится Hello.
Кажется, что разницы между рунами и байтами нет. Но вот, что будет, если поздороваться на китайском языке.
По задумке должны были вывестись первые 2 иероглифа, но обычный слайсинг строки не работает — вместо иероглифов выводится некорректный символ.
Помним, что строки в Go состоят из UTF-8 символов, каждый из которых может быть представлен более чем одним байтом. Если взять слайс по строке, то работать мы будем с байтами, а не с её символами. Поэтому когда мы пытаемся взять первые два символа от строки, мы берём первые два байта.
Большинство операций со строками работает с их байтами, но есть и исключения.. Слайсинг строки отдаёт байты, метод len также покажет длину в байтах. Цикл for range в качестве индекса берёт индекс байта, с которого начинается символ, но в значении будет лежать не байт, а руна, которая начинается в этом индексе.
Часто можно просто кастить строчку к слайсу рун и работать уже с ним. Но не стоит забывать про оверхэд, который мы можем получить в этом случае. На каждую строчку будут существовать две переменные: одна из них хранит исходную строку, а вторая — массив рун. Если строк много и они длинные, это также может иметь значение. К счастью, в Go есть процессорные оптимизации, которые в определенных ситуациях позволяют его избежать.
Каналы
Каналы — это примитив синхронизации, который даёт возможность одной горутине отправлять данные в другую и обеспечивает безопасный доступ к общим данным.
При работе с каналами возникают два вопроса: кто должен их закрывать и нужно ли вообще это делать. Важно знать, что может случиться при работе с каналом в разных его состояниях.
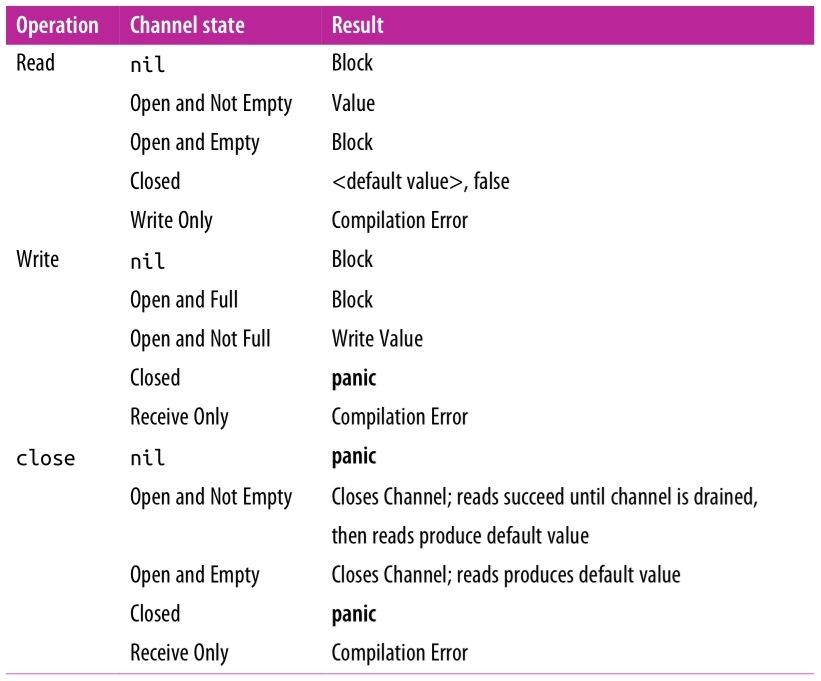
На этой таблице, описано, что мы получим при совершении разных операций. Например, с каналом в закрытом состоянии, чтение из него не вызовет проблем — мы просто получим дефолтное значение и false, что сигнализирует о том, что прочитать из канала не удалось. Однако, запись в закрытый канал и закрытие уже закрытого канала вызовет панику. Вывод: закрывать канал должна та горутина, что в него пишет.
Теперь попробуем ответить на вопрос: «зачем закрывать канал?». Для этого обратимся к документации: «отправитель может закрыть канал, чтобы указать, что значения больше не будут отправляться». Если отправитель закрывает канал, значит это может понадобится кому-то, кроме него — например, читателю канала. Рассмотрим пример, когда это может быть полезно:
Здесь есть говорящая функция writeToChan, в которой происходит запись в канал и в main цикл по этому каналу — в нём мы высчитываем значения. Если не закрыть канал, цикл никогда не закончится и случится deadlock. Если закрыть — for range успешно завершается и логика программы идёт дальше.
Закрывать канал стоит только в тех ситуациях, когда читатель никак не должен реагировать. Ничего страшного, если канал не закрыт. Сборщик мусора сможет от него избавиться даже в таком состоянии.
time.After
Раз уж обсудили каналы, поговорим о структурах, которые используют каналы. Одна из них — time.After. Это функция возвращает канал, который закроется после заданной задержки времени. Она обычно используется для создания таймеров или установки таймаутов на выполнение определенной логики в программах.
Вот пример, где мы обрабатываем какие-то события, которые поступают из некой очереди. Если за 15 минут мы не встретили ни одного события в канале, то кинем warning, что что-то случилось.
Если запустить код, он будет рабочим. Но если вдруг есть какой-то дашборд, в котором мы измеряем потребление памяти и событий большое число, то мы легко обнаружим, что есть утечка памяти. При среднем потоке в миллион сообщений в 15 минут утечка составит порядка 200 Мб. Один канал Go весит около 200 байт. Получается, что на каждое событие убегает новый канал.
Почему это происходит, если сборщик мусора сможет удалить и не закрытый канал, а канал, созданный time.after, выходит из зоны видимости после каждого нового события?
Обращаемся к документации: «таймер не будет собран сборщиками мусора до тех пор, пока он не отработает». То есть time.after, который мы ставили на 15 минут, на это время остаётся висеть мертвым грузом, даже если он уже не находится в области видимости.
Горутины
Горутина — это лёгкий поток выполнения в userspace, пока потоки операционной системы живут в kernel space. Горутины управляются средствами Go, а потоки — средствами операционной системы.
Горутины спроектированы так, чтобы быть более эффективными, чем традиционные потоки операционной системы. Но у них тоже есть несколько ловушек, в которые можно попасть при работе.
В примере ниже мы создаём слайс из цифр от 1 до 5 и горутины в цикле, и в каждой из них прибавляем своё число из слайса к переменной sum. Можно подумать, что в выводе будет число 15, то есть сумма чисел от 1 до 5 — однако это не так.
Здесь проблема состоит в замыканиях — функциях, которые захватывают переменные из внешней области видимости. В примере анонимная функция, которая создаётся в цикле, является замыканием, потому что она захватывает переменную value из внешней области видимости.
Особенность их работы в том, как используется захваченная переменная. Горутины не захватывают значения переменных на момент их создания — они захватывают ссылку на переменную. Поэтому, когда горутины начинают выполняться, цикл зачастую уже прошёл, и переменная value имеет последнее значение из слайса. По нему мы итерируемся, хотя гарантии того, что цикл завершится раньше, чем начнёт работу одна из горутин — нет. Это приводит к тому, что в переменной sum оказывается не значение 15.
Это настолько распространённая проблема, что мейнтейнеры Go решили изменить семантику переменных цикла for, чтобы предотвратить их непреднамеренное использование в замыканиях и горутинах на каждой итерации. В версии 1.21 появился соответствующий эксперимент, а с версии 1.22 эта проблема уже полностью перестала воспроизводиться. Но, поскольку версия 1.22 свеженькая, и ещё не все успели обновиться, берите себе на заметку эту особенность работы замыканий.
Пакеты sync и atomic
В примерах выше мы использовали sync WaitGroup, чтобы дождаться выполнения горутин и, кстати, сделали это неправильно. Признавайтесь, кто не заметил?) Стоит обратить внимание на то, где мы делаем wg.Add, и подумать, чем это черевато.
Давайте разбираться. Посмотрим на устройство wait group:
В структуре WaitGroup из интересного мы видим семафор и некий noCopy. Сначала поговорим про семафор, а точнее про то, что по сути WaitGroup — это простенькая обёртка над семафором с тремя методами:
- .Add(delta int) увеличивает значение семафора на переданное значение.
- .Done() уменьшает значение семафора на единицу.
- .Wait() блокирует выполнение до тех пор пока значение семафора не станет равно 0.
Так вот, проблема — в запущенных нами горутинах заключается в том, что нет гарантии, что они запустятся до того, как будет вызван .Wait. Это значит, .Wait может завершиться до выполнения .Add. Поскольку гарантии порядка запуска горутин нет, в итоге мы рискуем неверно решить, что все горутины завершили работу, хотя некоторые её ещё даже не начали.
Теперь вернёмся к структуре WaitGroup и присмотримся к полю noCopy, с таким же типом noCopy — что же это такое? По названию можно догадаться, что это что-то, что нельзя копировать, подобное поле есть в большинстве структур пакета sync. Давайте посмотрим, что же произойдёт, если всё же скопировать структуру с этим полем. Для примера будем использовать мьютекс, в нем также есть поле noCopy с типом noCopy.
В этой программе у нас есть структура Counter, которая хранит в себе мапу, а также мьютекс, который должен по задумке защищать мапу от параллельной записи. В мьютексе так же, как в waitGroup, присутствует noCopy.
На структуре Counter определены два метода: один увеличивает значение определенного ключа на единицу, другой — сразу на переданное значение. Есть мейн, в котором мы инициализируем структуру счётчика и запускаем две горутины для увеличения значения одного и того же ключа, делаем слип, чтобы дождаться выполнения горутин, и принтим значения, которые окажутся в мапе нашего счётчика. Но вот принт, к сожалению, мы так и не увидим, потому что упадём с паникой.
Проблема с кодом в том, что всякий раз, когда вызывается increment, в него копируется наш Counter c, поскольку increment определён на типа Counter, а не на *Counter. Другими словами, это value receiver, а не pointer receiver. Следовательно, increment не может изменять оригинальную переменную типа Counter, которую мы создали в main. Поэтому при каждом вызове increment происходило копирование счётчика со всем его содержимым, в том числе и мьютексом.
А теперь вспомним, что мьютекс — это просто обёртка над семафором, и, когда мы его копируем, мы копируем и семафор. При этом копия и оригинал могут жить своими отдельными жизнями, и ничто не помешает им конкурировать за операции с одним и тем же блоком памяти. Поэтому копирование мьютекса неправильно.
Так вот, за счет того самого noCopy есть возможность пометить любую структуру как невозможную к копированию (многие структуры из пакета sync так и отмечены). Тогда с помощью команды go vet можно будет обнаружить места, в которых отмеченная структура копируется, и найти потенциальную проблему в коде своего приложения.
Atomic
Теперь перейдем к ещё одному распространённому примитиву синхронизации — атомикам. Они предоставляют возможность безопасного доступа к общей памяти для операций чтения, записи и модификации переменных. Кроме того, в общем случае операции с атомиками быстрее, чем операции с мьютексом, за счёт использования специального набора процессорных инструкций. Однако, с этим преимуществом приходит и недостаток, про который периодически забывают: операции с атомиками атомарны по отдельности, но не атомарны все вместе.
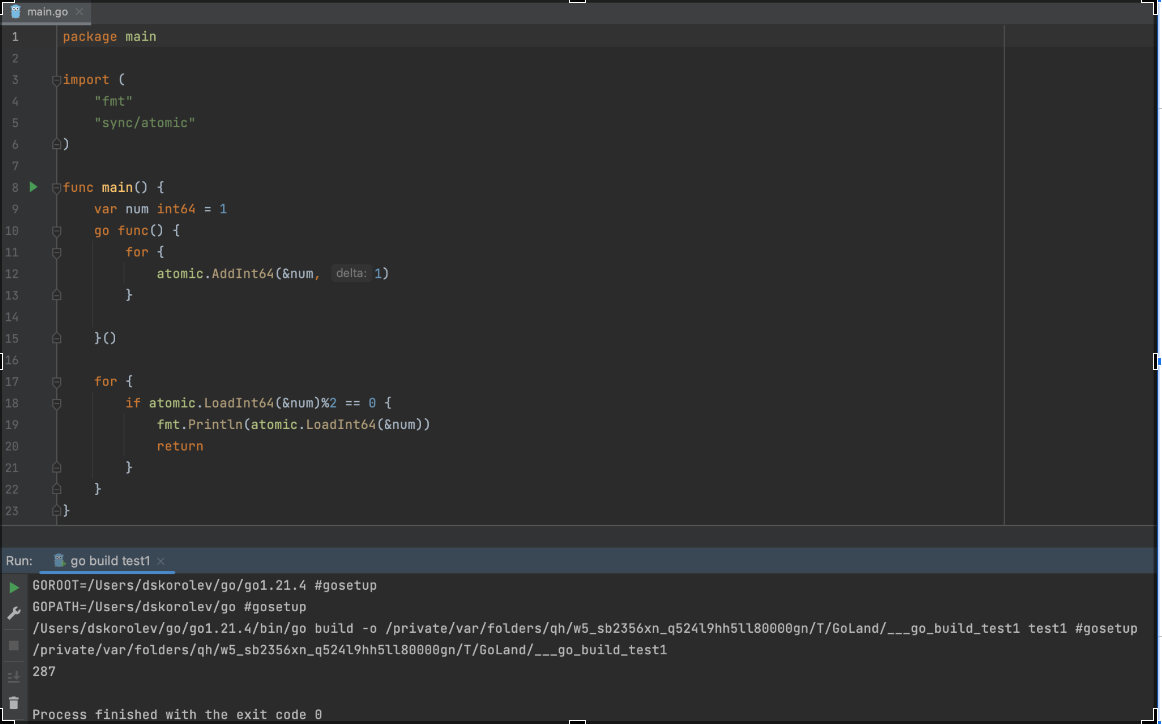
В этой программе запускается горутина, которая постоянно в бесконечном цикле увеличивает на единицу значение переменной num. В то же время, в main находится бесконечный цикл, который проверяет, чётное ли число, и если это условие выполняется — выводит его на экран. Однако мы видим, что при запуске вывелось число 287, а оно, как ни странно, нечётное. Это происходит из-за того, что после прохождения num проверки на чётность его значение никак не защищено от изменений, и горутина, инкрементирующая num, успевает изменить его значение до того, как число выводится на экран.
defer
defer позволяет отложить выполнение блока кода до окончания функции, в которой он был вызван. Обычно он используется для обеспечения освобождения ресурсов, например, закрытия файла или разблокировки мьютекса, независимо от того, как функция завершает работу — из-за обычного возврата, паники или ошибки.
Здесь мы видим структуру профиля и несколько возможных типов для него, а также метод GetBalance(), в котором, в зависимости от типа профиля, выбирается тот или иной метод подсчета баланса. Допустим, теперь мы хотим добавить лог с итоговым балансом, полученным при подсчёте:
И в результате добавленного нами лога мы всегда будем видеть запись «profile balance: 0». Почему так?
Давайте внимательнее посмотрим на то, что написано про defer в документации языка: «The arguments to the deferred function (which include the receiver if the function is a method) are evaluated when the defer executes, not when the call executes». Значение аргументов для функции в defer (в том числе и ресивер метода) вычисляются в момент исполнения defer, а не в момент исполнения функции. В нашем примере на момент исполнения defer в переменной balance у нас по дефолту лежит 0 — вот с этим значением наш принт и выполняется. А для того, чтобы достичь результата, который мы и хотели получить, то есть для того, чтобы в принте фигурировала итоговая сумма расчета, можно использовать концепцию, с которой мы уже встречались — замыкания.
Анонимная функция не имеет никаких аргументов, переменная balance расположена в теле этой функции. Соответственно, будет сохранена ссылка на эту переменную, и фактическое значение будет получено при выполнении анонимной функции по сохранённой ссылке.
Интерфейсы
Интерфейсы в Go обеспечивают гибкость кода, позволяя писать универсальные функции, которые могут работать с разными типами данных, реализующими один и тот же интерфейс. Однако и с ними не все гладко. Посмотрим на такой пример кода:
У нас есть интерфейс реквестера, который делает какой-то запрос и в респонсе отдает int — допустим, статус-код нашего запроса. Есть конкретный тип concrete requester, который реализует интерфейс реквестера. Ещё для интерфейса реквестера есть функция, которая позволяет его инициализировать в зависимости от переданного значения value.
Если оно больше нуля, то мы возвращаем instance concret requester’а. Если оно меньше или равно нулю — просто возвращаем не проинициализированную переменную. В main есть логика, которая сначала принтит реквестер, а затем делает ещё один принт в зависимости от того, nil он или нет.
Если запустить программу, то мы увидим забавный вывод:
Мы получили реквестер nil, но при этом он не nil.
Чтобы разобраться, нам нужно внимательнее присмотреться к интерфейсам – а точнее к тому, как они устроены под капотом.
Под капотом есть две структуры для интерфейсов: eface для пустого и iface, если определён набор методов, которым должен соответствовать тип. Сейчас нас интересуют общие для них поля — а именно тип данных, которые реализует интерфейс, и ссылка на область в памяти, где находится его значение. Для того, чтобы две переменные интерфейс-типа были равны, нужно чтобы у них были равны оба этих поля.
Теперь посмотрим
что именно лежит в этих полях для нашей переменной requester:
Ага! Вот отсюда ноги и растут. Несмотря на то, что фактическое значение у переменной — это nil, тип таковым не является, что и приводит к тому, что сравнение requester == nil — это false.
Это поведение связано с так называемым value boxing и заслуживает отдельной статьи, которая уже в общем-то и так любезно написана здесь.
Особенности вендоринга
Представим, что вы завели библиотеку на Go, в которой должны происходить какие-то сетевые запросы. Внутри этой библиотеки вы реализовали некий клиент, который умеет делать запросы, получать в респонсе какие-то данные и отдавать их в виде структур, описанных в папке models.
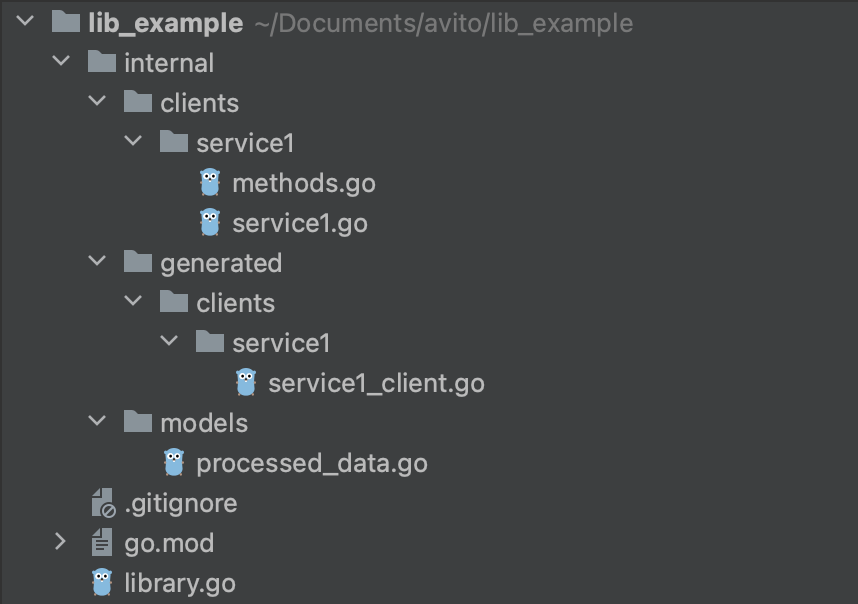
Теперь попробуем использовать эту библиотеку в каком-нибудь сервисе. Добавили её в go.mod, прописали в консоли go mod tidy, go mod vendor, решили заглянуть в vendor, а там, неожиданно лежит только часть файлов и папок вашей библиотеки.
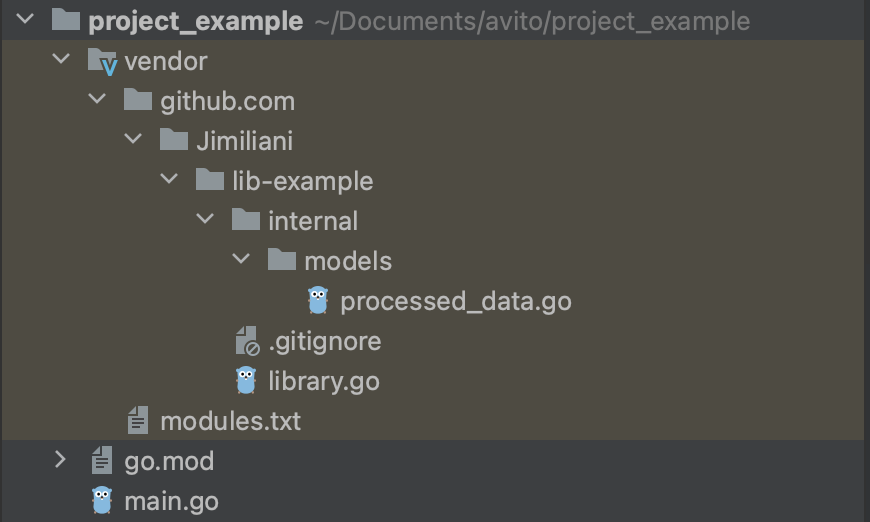
Для тех, кто не изучал, как работает вендоринг, это будет казаться чем-то странным. Что ж, за ответами отправляемся в документацию языка:
“The go mod vendor command constructs a directory named vendor in the main module”s root directory containing copies of all packages needed to build and test packages in the main module.”
И вновь всё встает на свои места: в вендоре оказываются только те пакеты, которые нужны для успешного билда и тестирования приложения. То есть, если мы инициализируем клиент из библиотеки где-то в сервисе, в котором мы эту библиотеку подключили, у нас подтянутся требуемые для этого пакеты.
Сама по себе эта ситуация может показаться просто неожиданной особенностью языка. На самом деле, это тонкий намек на то, что возможно заносить имплементацию логики похода во внешний сервис внутрь библиотеки — это не лучшая мысль. Ведь таким образом мы увеличиваем связность логики, а также уменьшаем возможности сервисов-потребителей в плане кастомизации взаимодействия библиотеки с внешними сервисами.
На этом все! Напишите в комментариях, есть ли ещё какие-то ошибки, о которых не рассказал в статье? Обсудим их в следующий раз!

2К открытий11К показов

В середине ноября релизнули совместное исследование Хабра и ЭКОПСИ, цель которого – составить рейтинг лучших IT-работодателей России. Мы в Avito внимательно этот рейтинг изучили, выводы сделали, и готовы вам о них рассказать.

Дмитрий Королёв, бэкенд-разработчик в Авито, разобрал на примерах, чем отличаются друг от друга форматы сериализации данных и как выбрать самый удобный.

Антон Губарев, инженер в Avito PaaS, рассказал, как реализовать межсервисную авторизацию на 2500 сервисов и ничего не сломать.

Павел Агалецкий, ведущий разработчик юнита Platform as a Service Авито, написал, как поднять кластер Kubernetes на локальном компьютере Mac с помощью подручных инструментов, а потом задеплоить в него простейшие приложения.