


Сравниваем форматы сериализации на Go: скорость и удобство
Дмитрий Королёв, бэкенд-разработчик в Авито, разобрал на примерах, чем отличаются друг от друга форматы сериализации данных и как выбрать самый удобный.
383 открытий5К показов

Привет! Меня зовут Дмитрий Королёв, я бэкенд-разработчик в Авито.
В большинстве современных приложений используется сериализация данных: для передачи данных между клиентом и сервером, для хранения сложных структур в базах данных, при передаче информации между микросервисами или отправке сообщений в очереди.
Правильный выбор формата сериализации может существенно повлиять на производительность приложения, размер передаваемых данных и читаемость кода.
В этой статье я покажу бенчмарки нескольких самых популярных форматов сериализации в языке Golang и расскажу про преимущества и недостатки каждого из них. Это поможет вам выбрать подходящий формат для вашего проекта с учетом его потребностей. Например, меньший размер сериализованных, если вы хотите сэкономить место при хранении данных или сетевые ресурсы при их передаче, время сериализации/десериализации, если для вашего приложения критична скорость и т. д.
Какие бывают форматы сериализации
Можно разделить существующие форматы сериализации на две большие группы — бинарные и текстовые. У каждой из них есть свои характеристики, по которым можно оценить, насколько формат подходит для ваших целей. Для начала расскажу про ключевые моменты, на которые нужно обратить внимание при выборе.
Бинарные форматы
Avro, Protobuf, CBOR и Msgpack относятся к бинарным форматам сериализации данных. Ключевые различия между ними:
- Схема данных:Avro поддерживает схемы данных, которые описывают структуру сериализованных данных. Это позволяет легко изменять схему данных и делает его подходящим для развивающихся схем данных.Protobuf также использует схемы данных и автоматически генерирует код на основе схемы. Это позволяет легко создавать и обновлять структуру данных.CBOR и Msgpack не предоставляют встроенной поддержки схем данных, поэтому данные сериализуются без дополнительной информации о структуре.
- Avro поддерживает схемы данных, которые описывают структуру сериализованных данных. Это позволяет легко изменять схему данных и делает его подходящим для развивающихся схем данных.
- Protobuf также использует схемы данных и автоматически генерирует код на основе схемы. Это позволяет легко создавать и обновлять структуру данных.
- CBOR и Msgpack не предоставляют встроенной поддержки схем данных, поэтому данные сериализуются без дополнительной информации о структуре.
- Человекочитаемость:Бинарные форматы не предназначены для чтения человеком, однако Avro и Protobuf можно сериализовать в json. Это может быть полезно в целях дебага, но мало пригодно для production среды.
- Бинарные форматы не предназначены для чтения человеком, однако Avro и Protobuf можно сериализовать в json. Это может быть полезно в целях дебага, но мало пригодно для production среды.
- Компактность и производительность:CBOR и Msgpack более компактны и имеют лучшую производительность при сериализации и десериализации данных, поскольку сериализованные сообщения не содержат метаданных.Avro и Protobuf также обеспечивают хорошую компактность и производительность, но процесс сериализации и десериализации может быть более сложным из-за схемы данных. Например, в случае с avro во время сериализации проводится анализ схемы, чтобы впоследствии определить каким образом обрабатывать то или иное поле.
- CBOR и Msgpack более компактны и имеют лучшую производительность при сериализации и десериализации данных, поскольку сериализованные сообщения не содержат метаданных.
- Avro и Protobuf также обеспечивают хорошую компактность и производительность, но процесс сериализации и десериализации может быть более сложным из-за схемы данных. Например, в случае с avro во время сериализации проводится анализ схемы, чтобы впоследствии определить каким образом обрабатывать то или иное поле.
- Эволюционность:Avro и Protobuf обеспечивают поддержку обратной совместимости при изменении схем данных. Это облегчает эволюцию данных в распределенных системах.CBOR и Msgpack не предоставляют встроенной поддержки для эволюции данных и требуют дополнительных усилий при изменении структуры данных. Например, потребуется изменить поведение обрабатывающей логики при удалении полей из структуры сообщения, сериализованного в одном из этих форматов.
- Avro и Protobuf обеспечивают поддержку обратной совместимости при изменении схем данных. Это облегчает эволюцию данных в распределенных системах.
- CBOR и Msgpack не предоставляют встроенной поддержки для эволюции данных и требуют дополнительных усилий при изменении структуры данных. Например, потребуется изменить поведение обрабатывающей логики при удалении полей из структуры сообщения, сериализованного в одном из этих форматов.
Текстовые форматы
JSON (JavaScript Object Notation) и XML (Extensible Markup Language) — два разных текстовых формата для сериализации и обмена данными. Вот ключевые различия между ними:
- Синтаксис:JSON использует более легкий и компактный синтаксис для представления данных — в виде пар «ключ:значение». Структура данных обычно более краткая и простая.XML использует размеченный синтаксис с использованием открывающих и закрывающих тегов, что делает его более развернутым и многословным.
- JSON использует более легкий и компактный синтаксис для представления данных — в виде пар «ключ:значение». Структура данных обычно более краткая и простая.
- XML использует размеченный синтаксис с использованием открывающих и закрывающих тегов, что делает его более развернутым и многословным.
- Удобочитаемость:JSON-документы человек может легко читать и понимать благодаря простому синтаксису.XML также человекочитаем, но его сложнее интерпретировать из-за многочисленных тегов и атрибутов.
- JSON-документы человек может легко читать и понимать благодаря простому синтаксису.
- XML также человекочитаем, но его сложнее интерпретировать из-за многочисленных тегов и атрибутов.
- Размер данных:JSON-документы обычно имеют меньший размер по сравнению с XML благодаря компактному синтаксису.XML-документы обычно более объемные и занимают больше места.
- JSON-документы обычно имеют меньший размер по сравнению с XML благодаря компактному синтаксису.
- XML-документы обычно более объемные и занимают больше места.
- Поддержка данных:JSON поддерживает ограниченное количество данных-типов, включая строки, числа, булевы значения, массивы и объекты.XML позволяет создавать собственные структуры данных с использованием DTD или XSD и может представлять более сложные структуры.
- JSON поддерживает ограниченное количество данных-типов, включая строки, числа, булевы значения, массивы и объекты.
- XML позволяет создавать собственные структуры данных с использованием DTD или XSD и может представлять более сложные структуры.
- Валидация:JSON обычно не имеет встроенной системы валидации, поэтому она может потребовать дополнительных инструментов.XML поддерживает валидацию данных с использованием DTD или XSD.
- JSON обычно не имеет встроенной системы валидации, поэтому она может потребовать дополнительных инструментов.
- XML поддерживает валидацию данных с использованием DTD или XSD.
Бенчмарки: сравниваем форматы сериализации между собой
Для этой статьи мы выбрали самые известные форматы: Avro, Protobuf, Msgpack, XML, CBOR и несколько известных библиотек для работы с JSON
Тестирование проводилось на ПК с такими характеристиками: Apple M1 Pro 3.2 GHz 10 cores (8 performance and 2 efficiency), 32 GB LPDDR5, APPLE SSD AP0512R.
Всего проводились замеры данных трех разных объемов:
- 1 строка
- 100 строк
- 100 000 строк
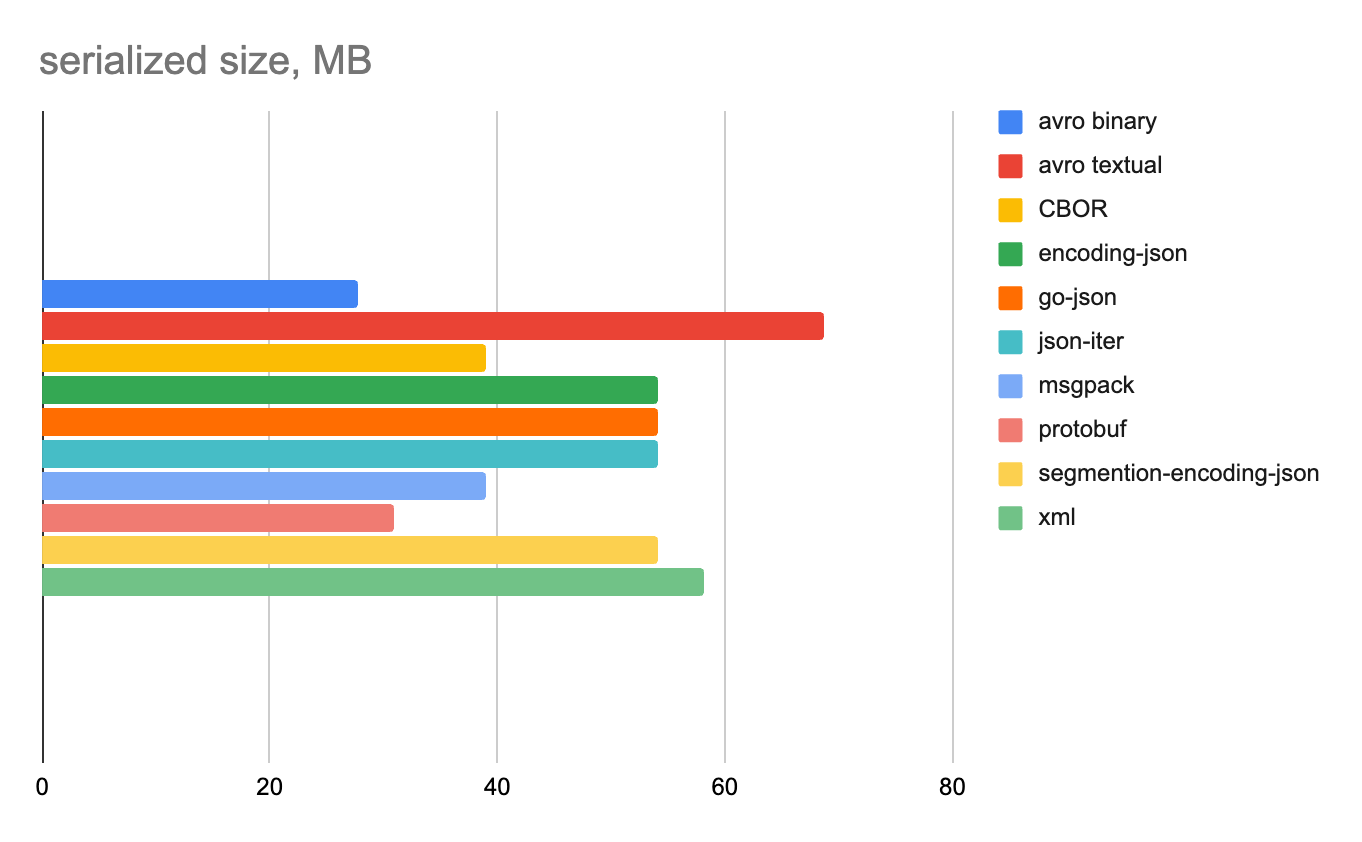
Использовались только целочисленные, только строковые и смешанные (строки+числа) данные. Все поля nullable с разной степенью заполненности. Размер сериализованных данных измерялся только для 100 000 строк, поскольку на 1 или 100 строках результат мог бы получиться недостаточно репрезентативным.
Ниже на отдельных диаграммах показаны время сериализации и десериализации и объем полученных данных для каждого формата.
Исходники можно увидеть здесь.
1 строка
Целые числа
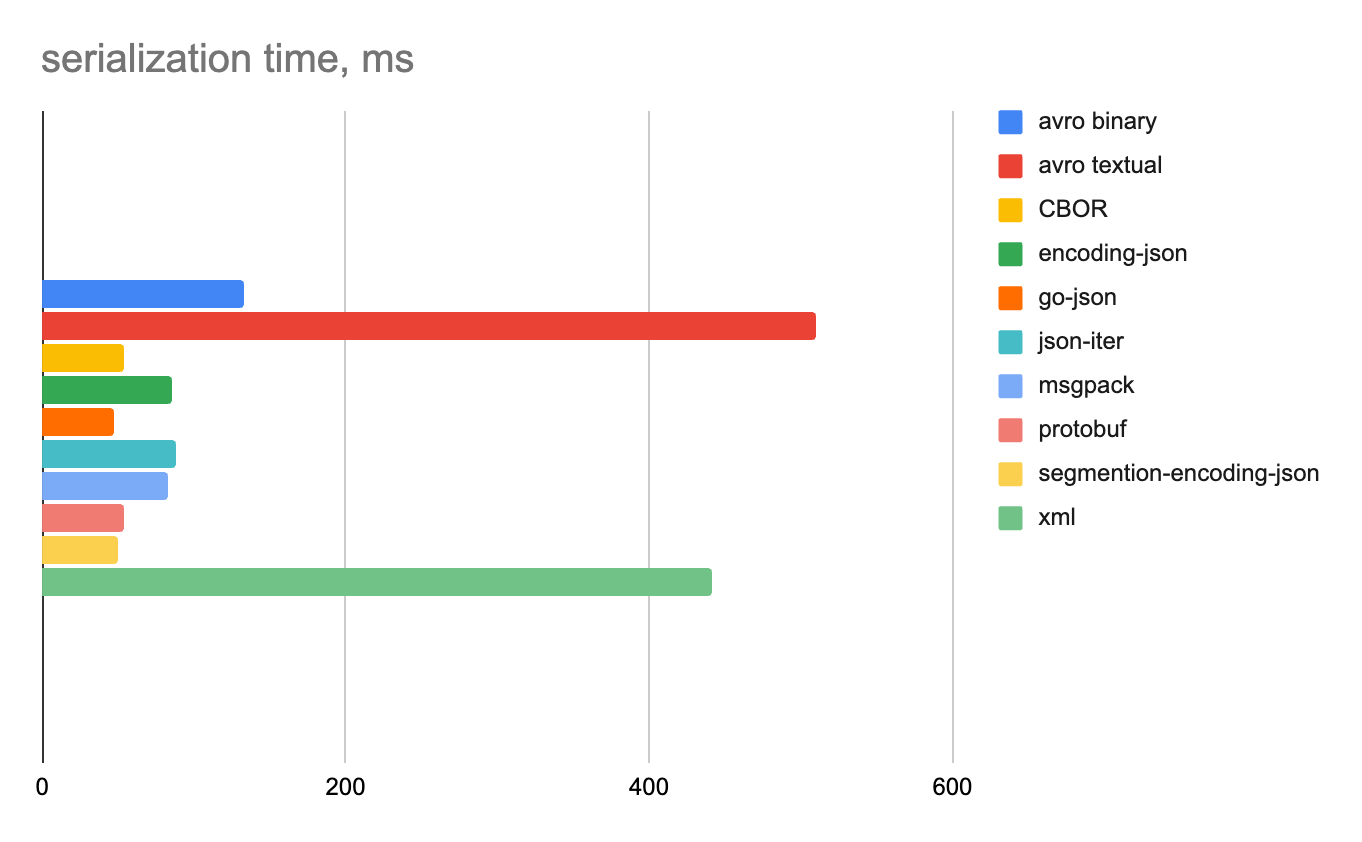
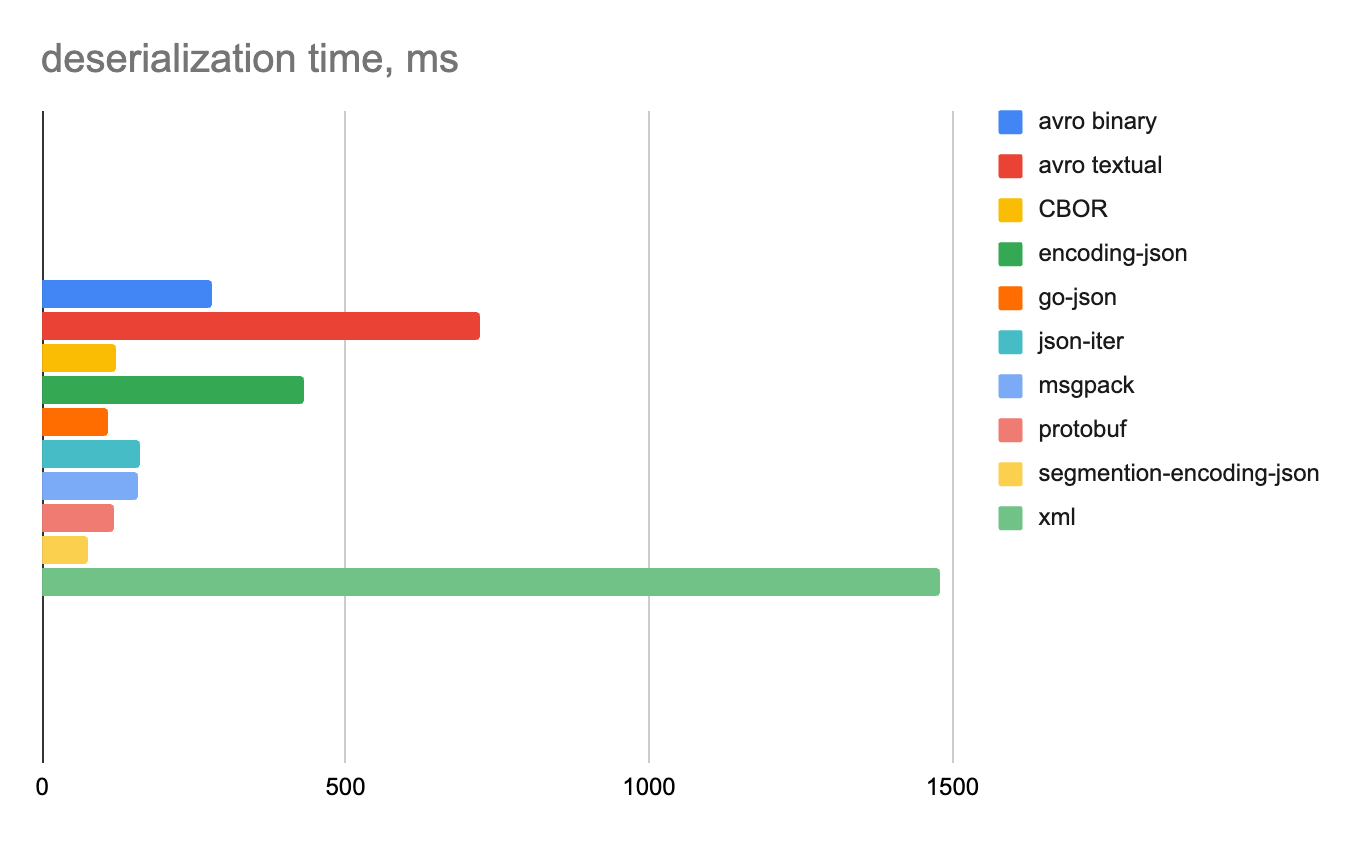
Строковые данные
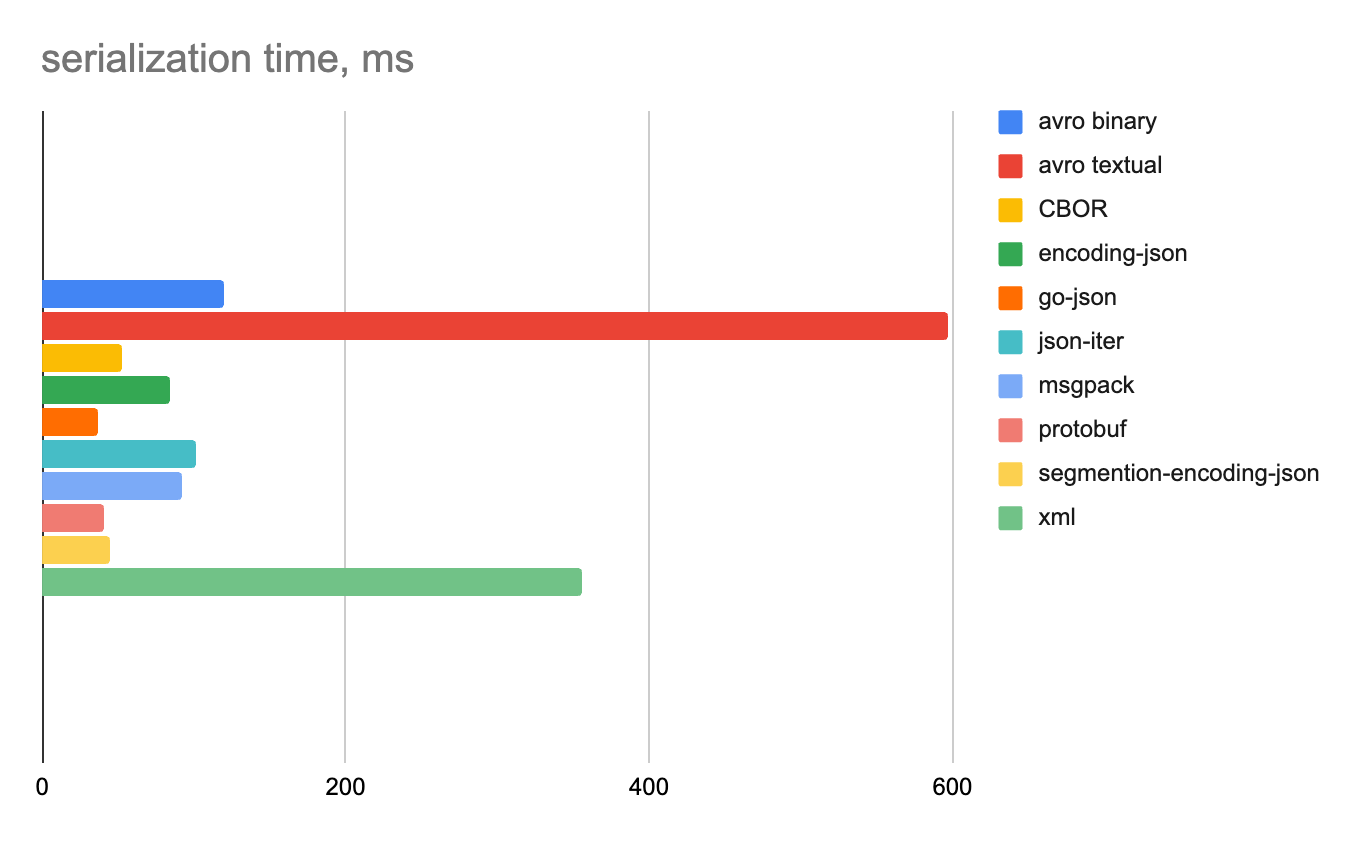
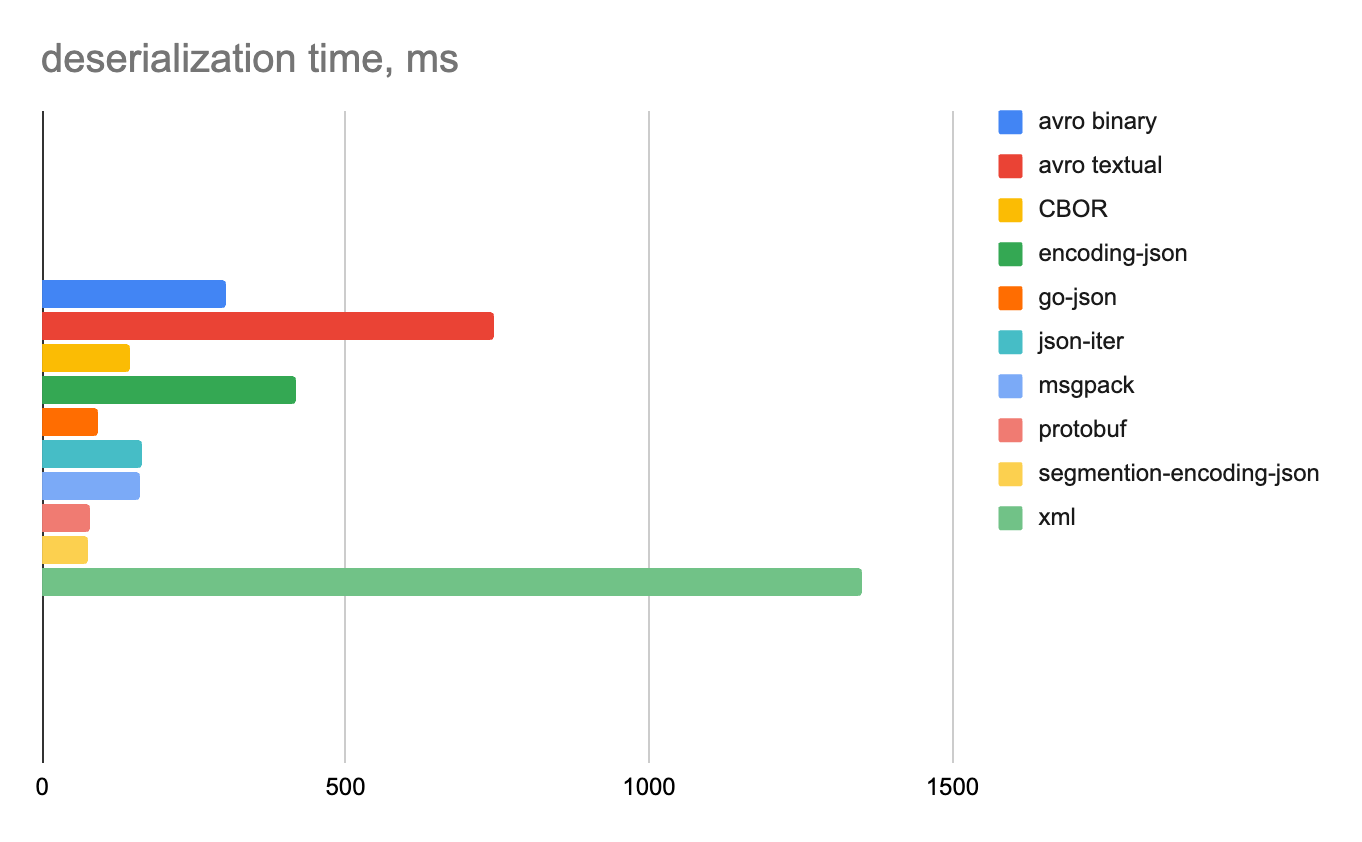
Смешанные данные
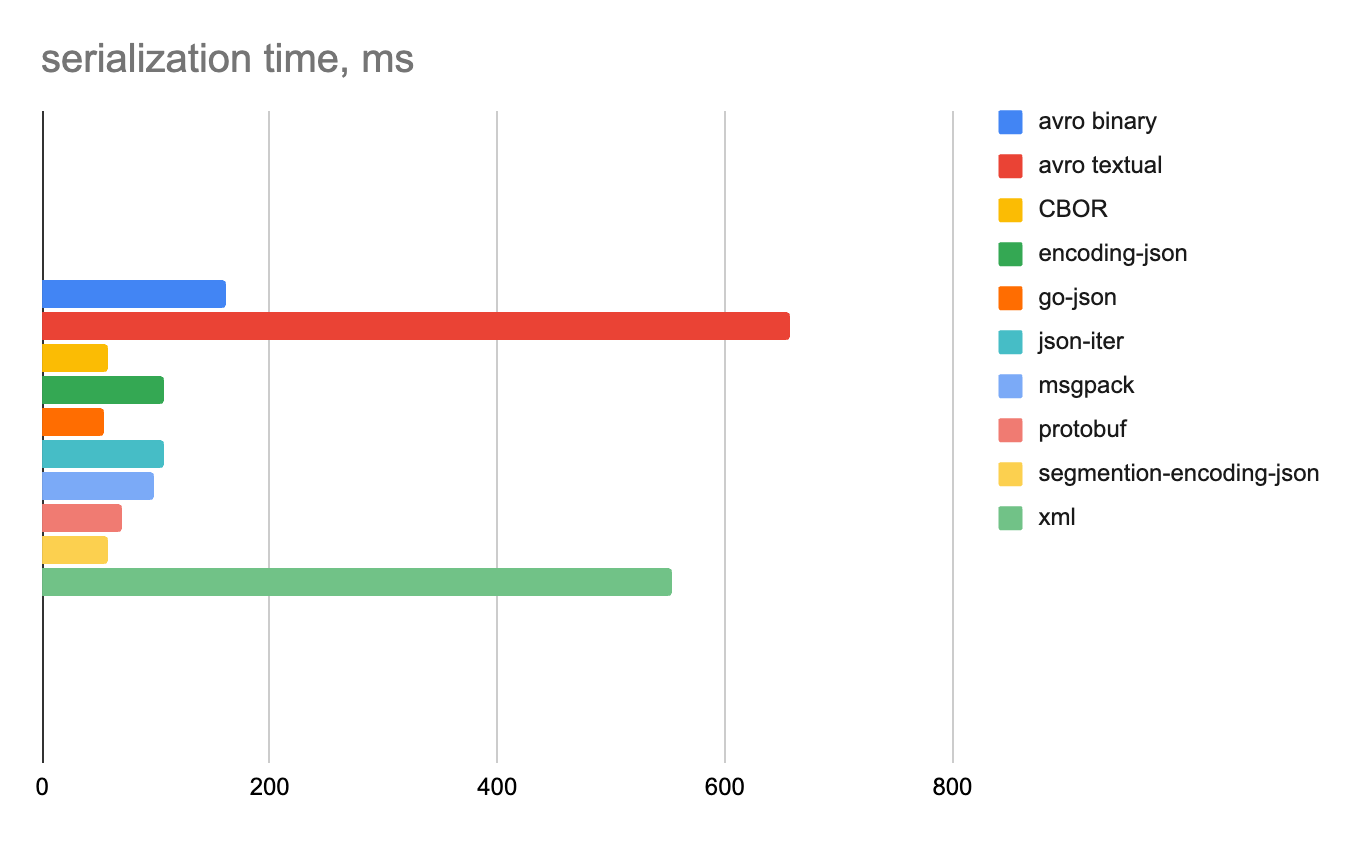
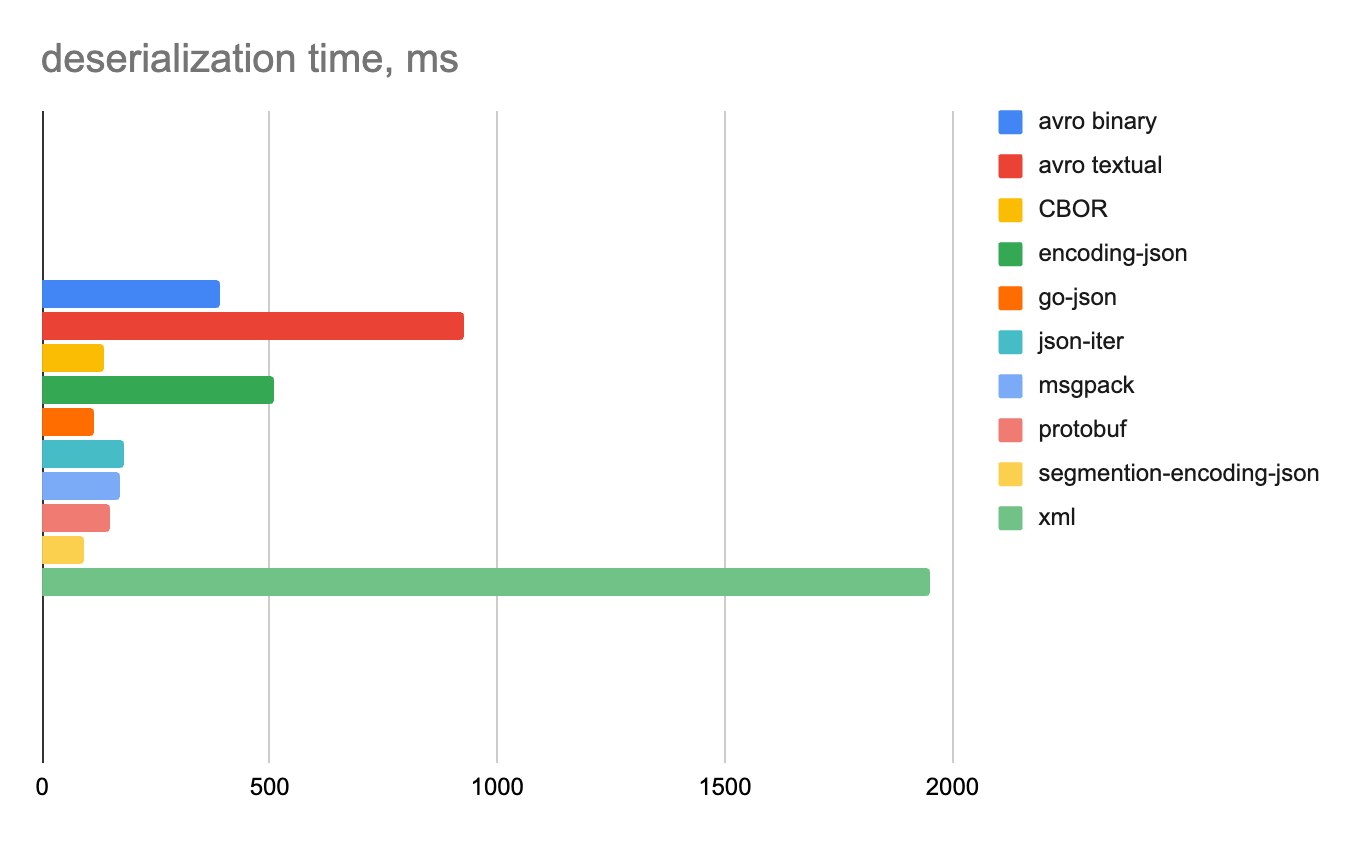
100 строк
Целые числа
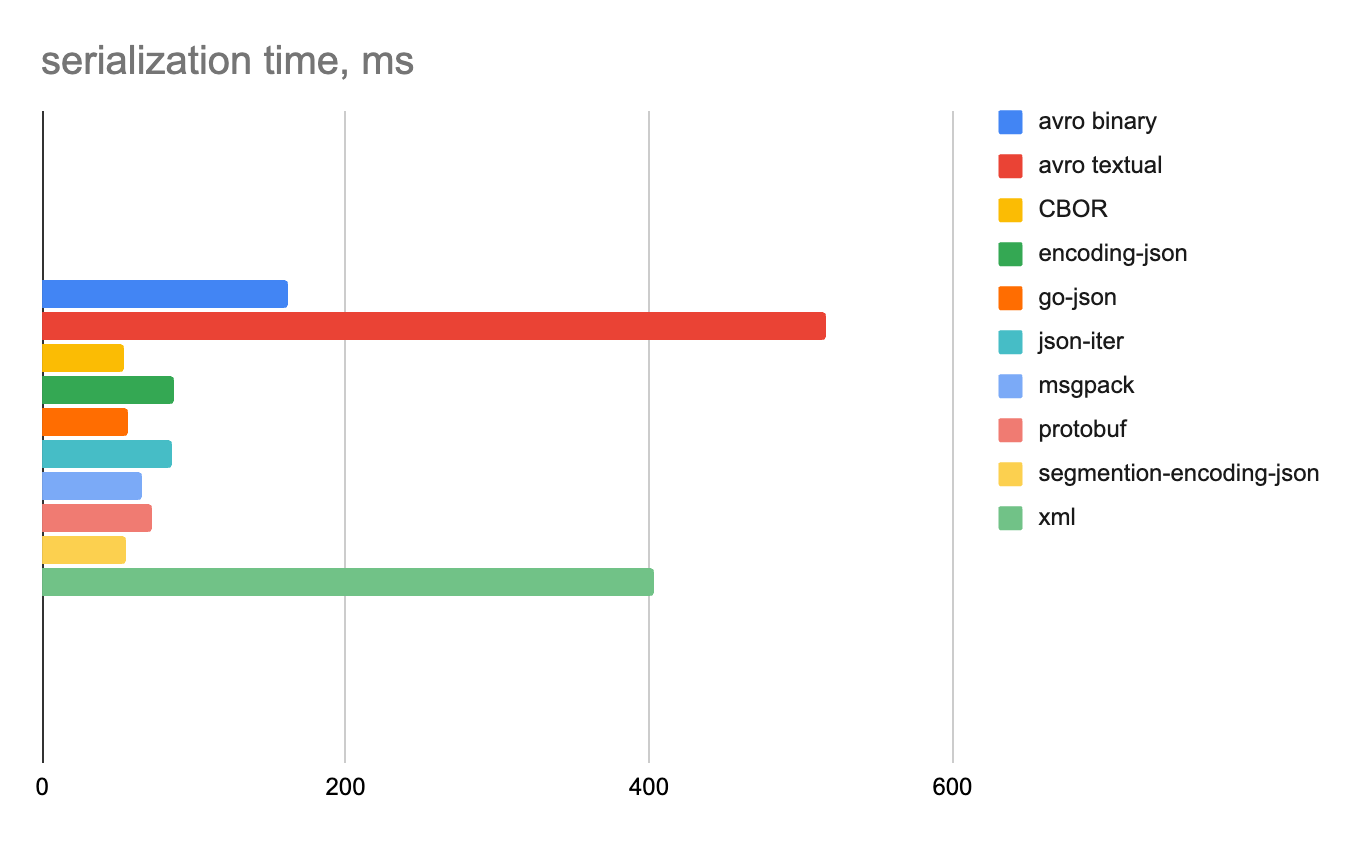
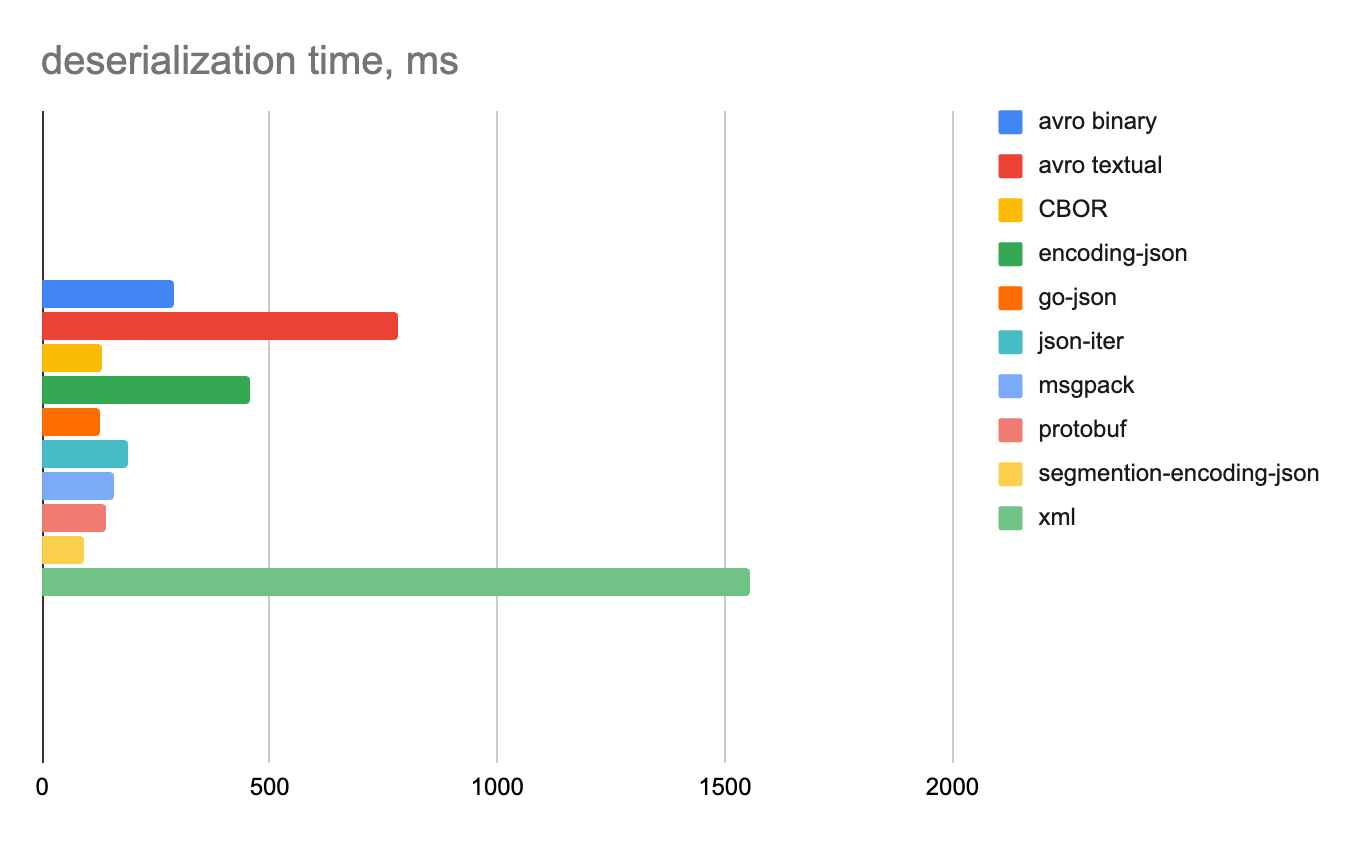
Строковые данные
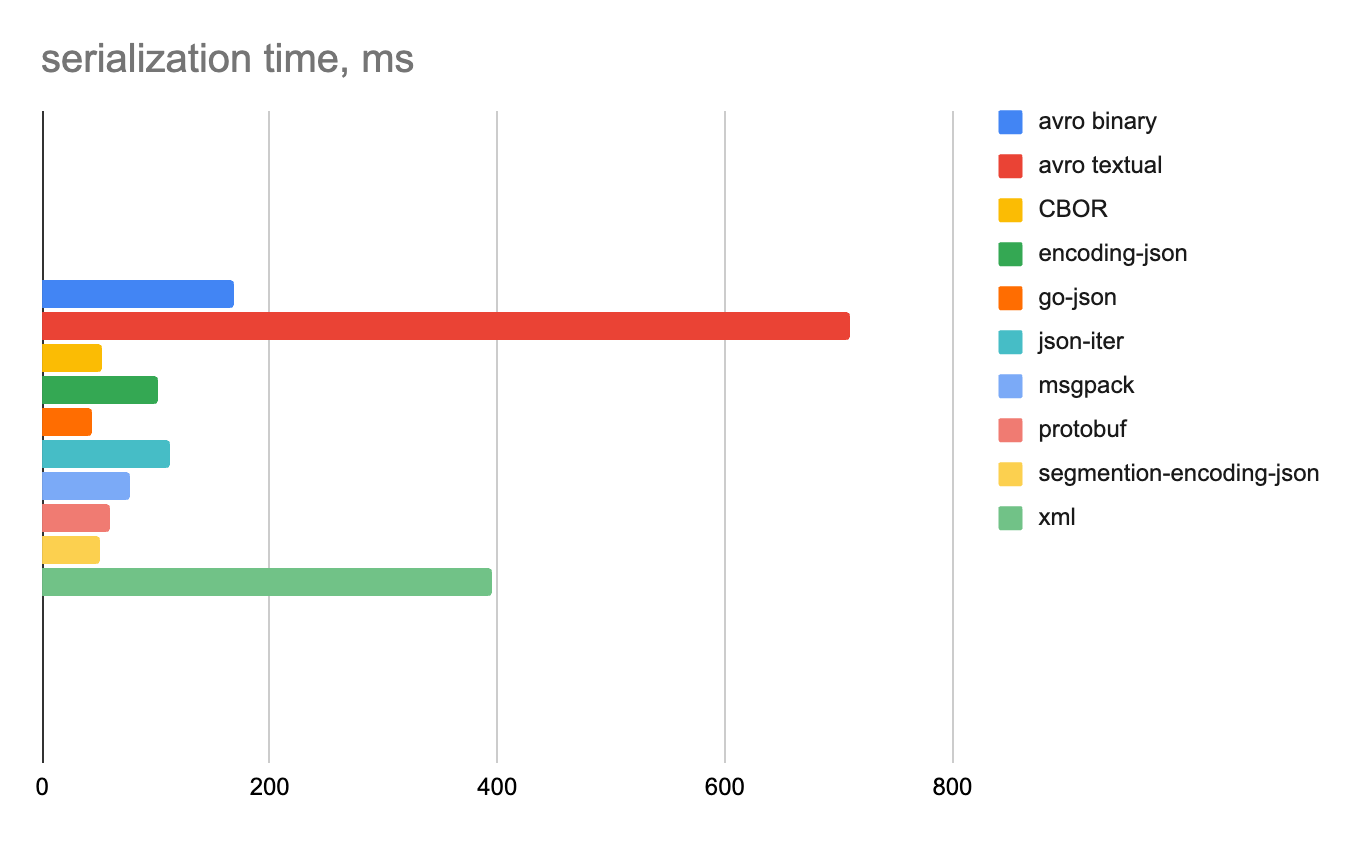
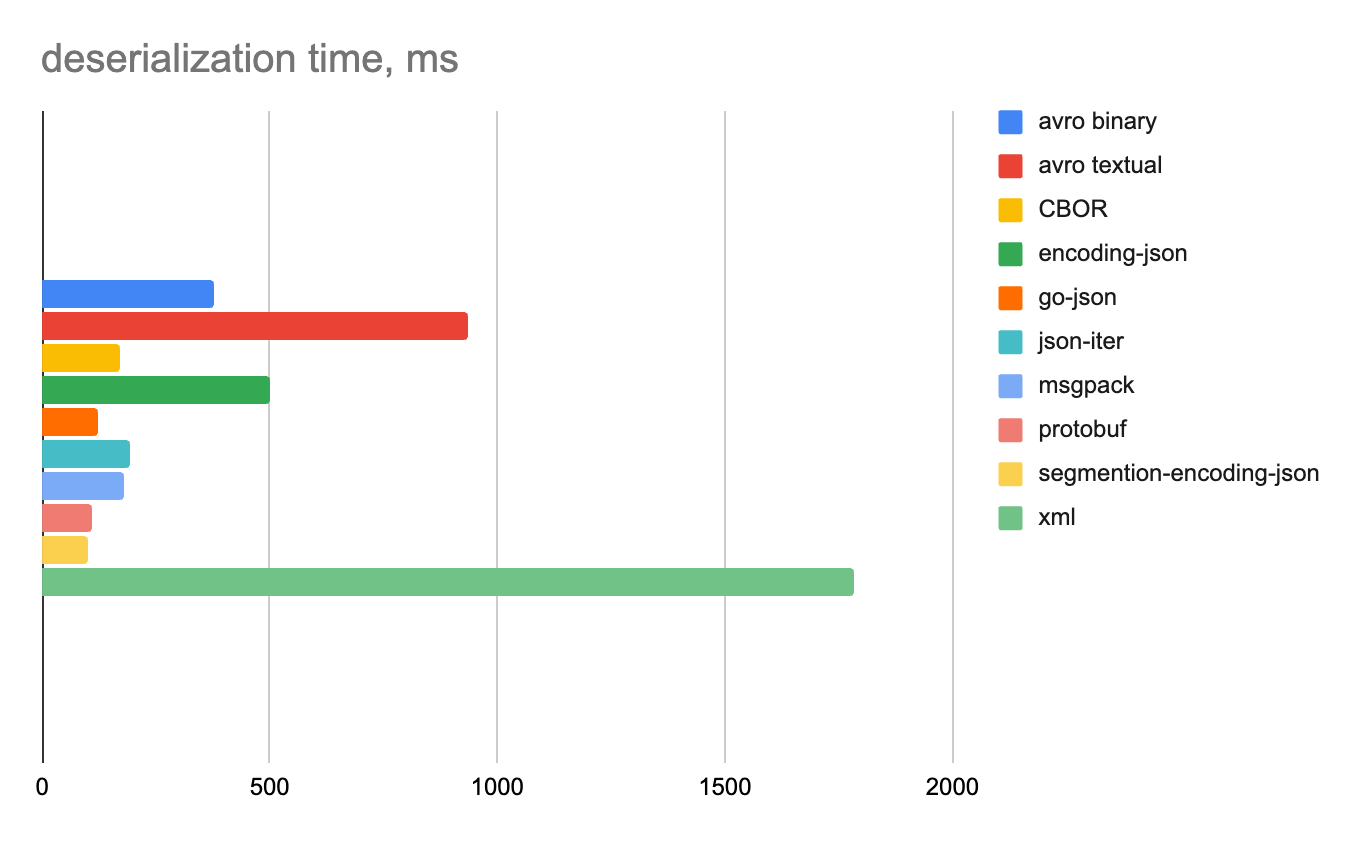
Смешанные данные
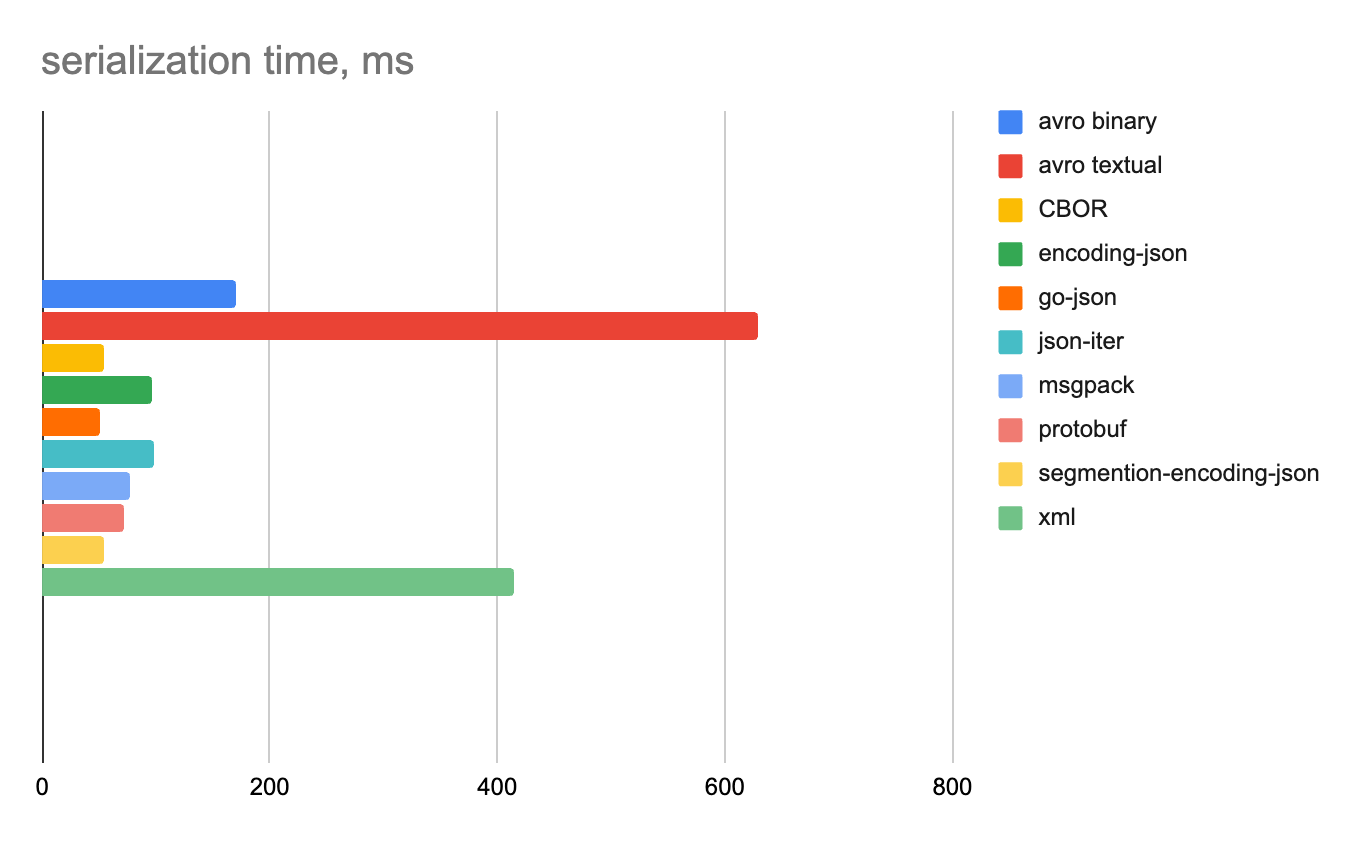
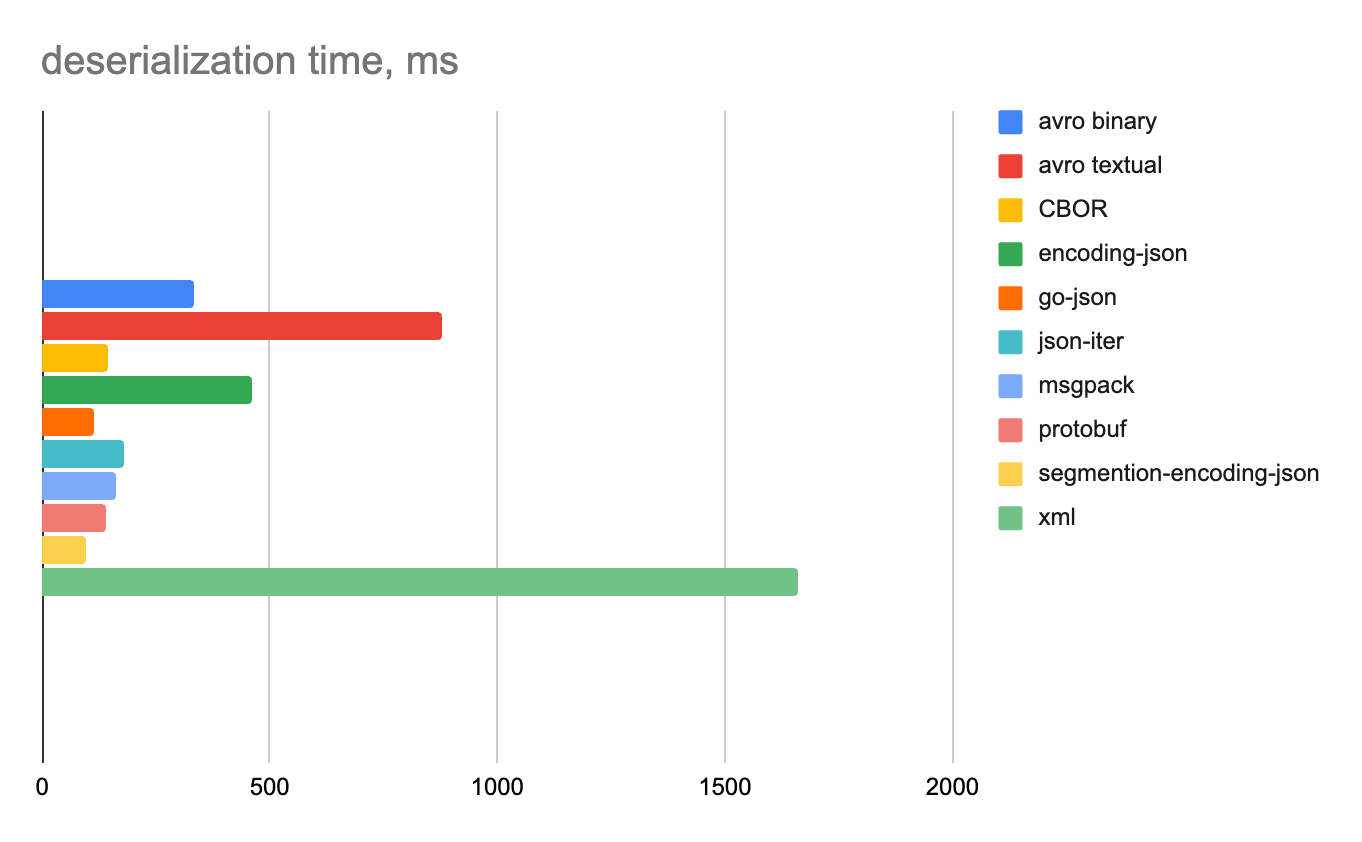
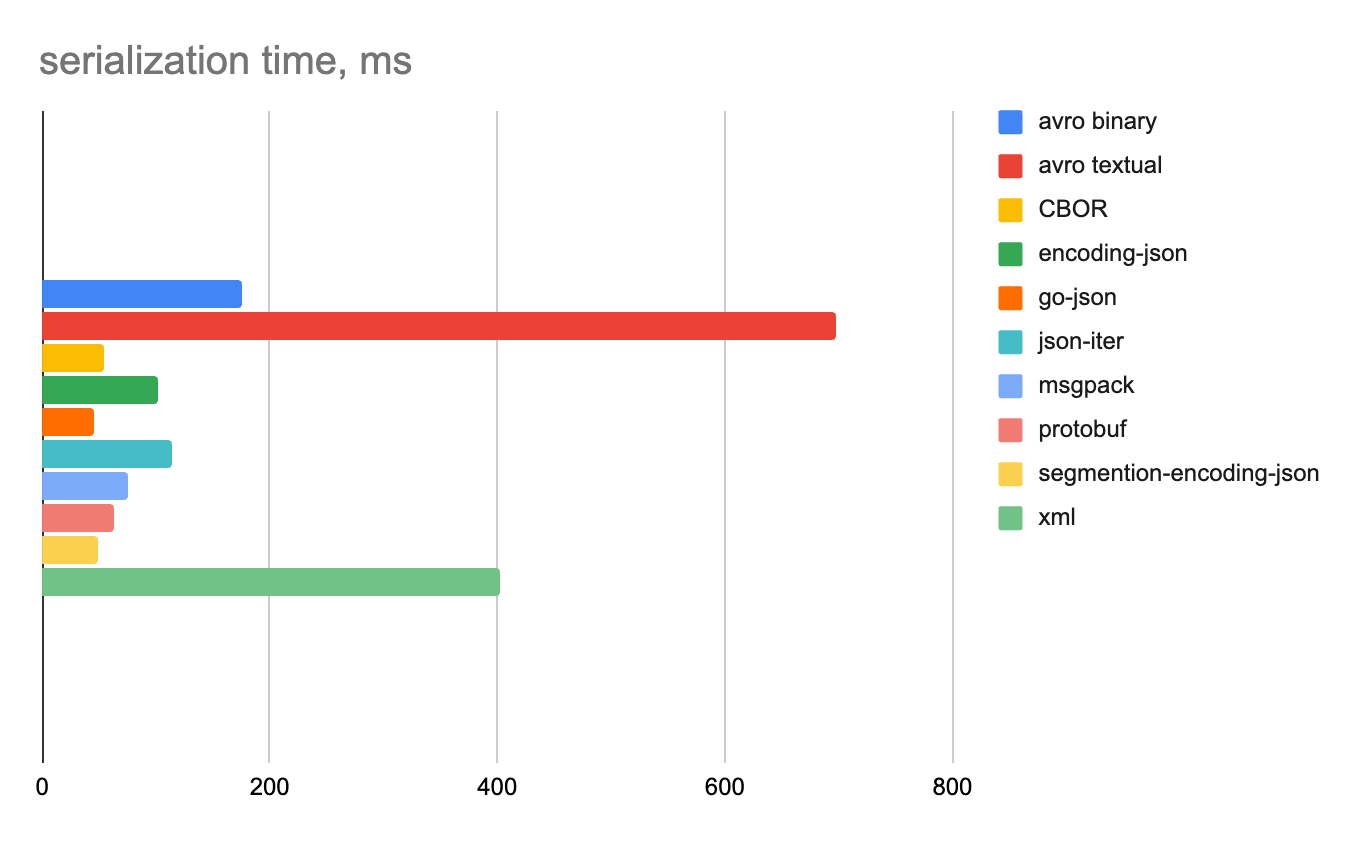
100 000 строк
Целые числа
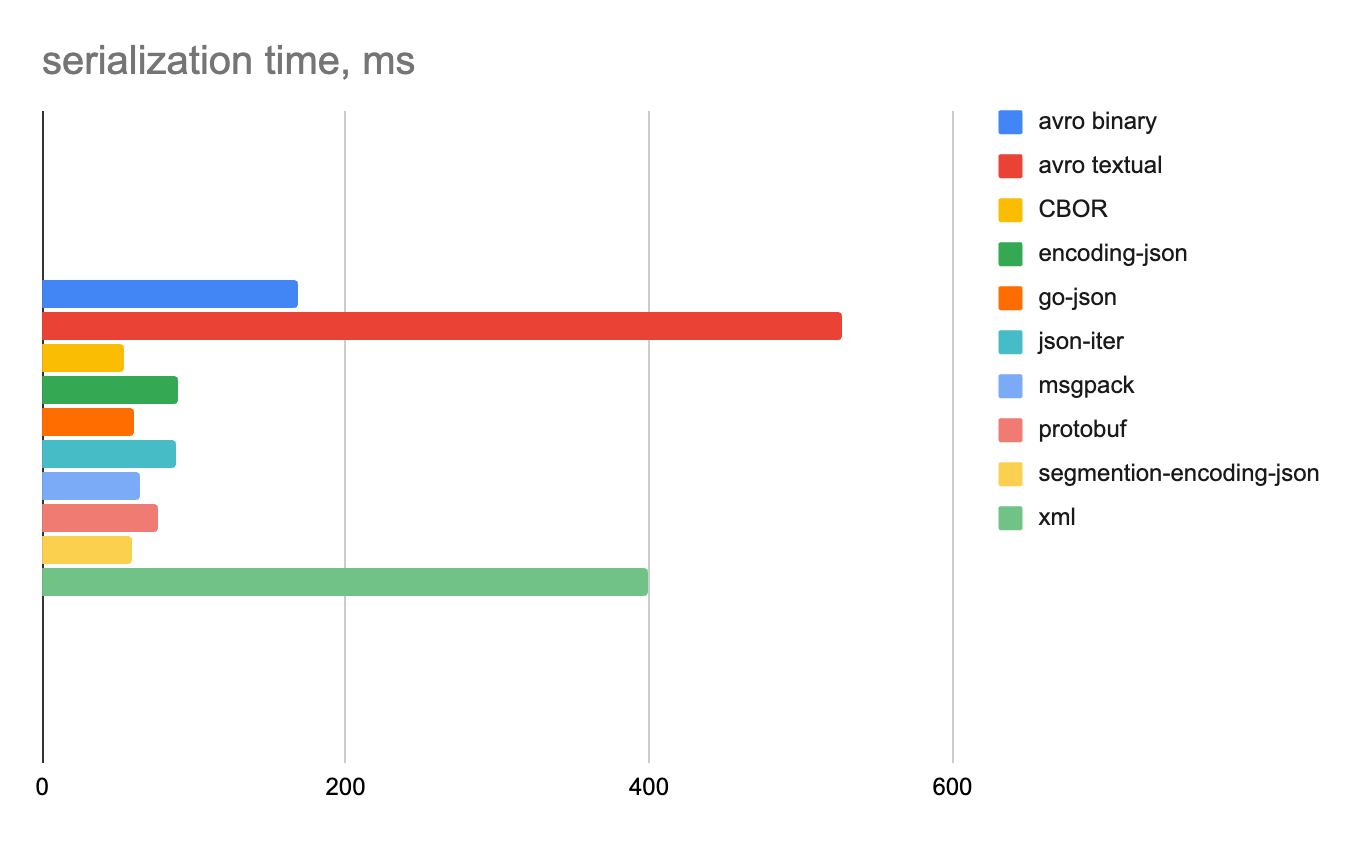
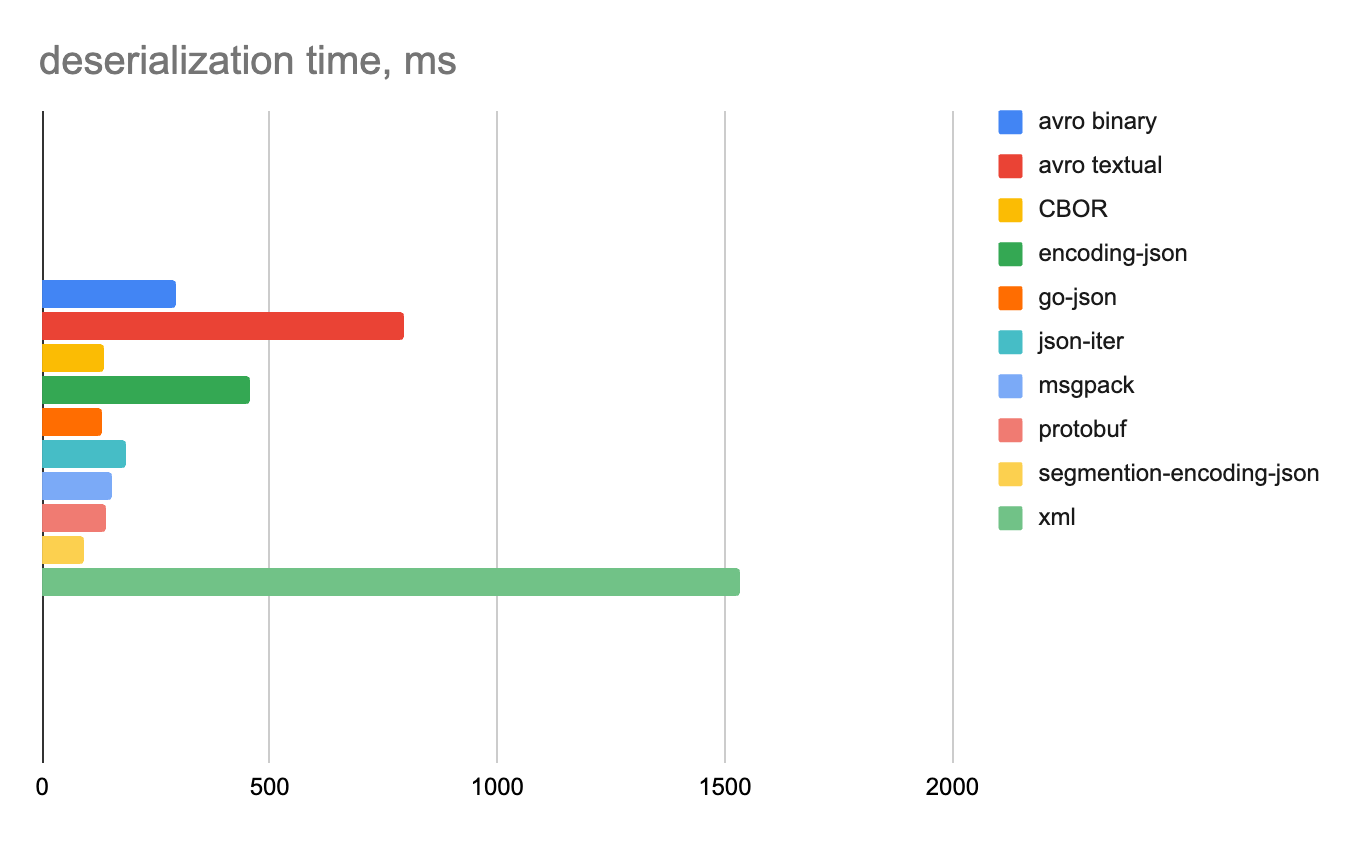
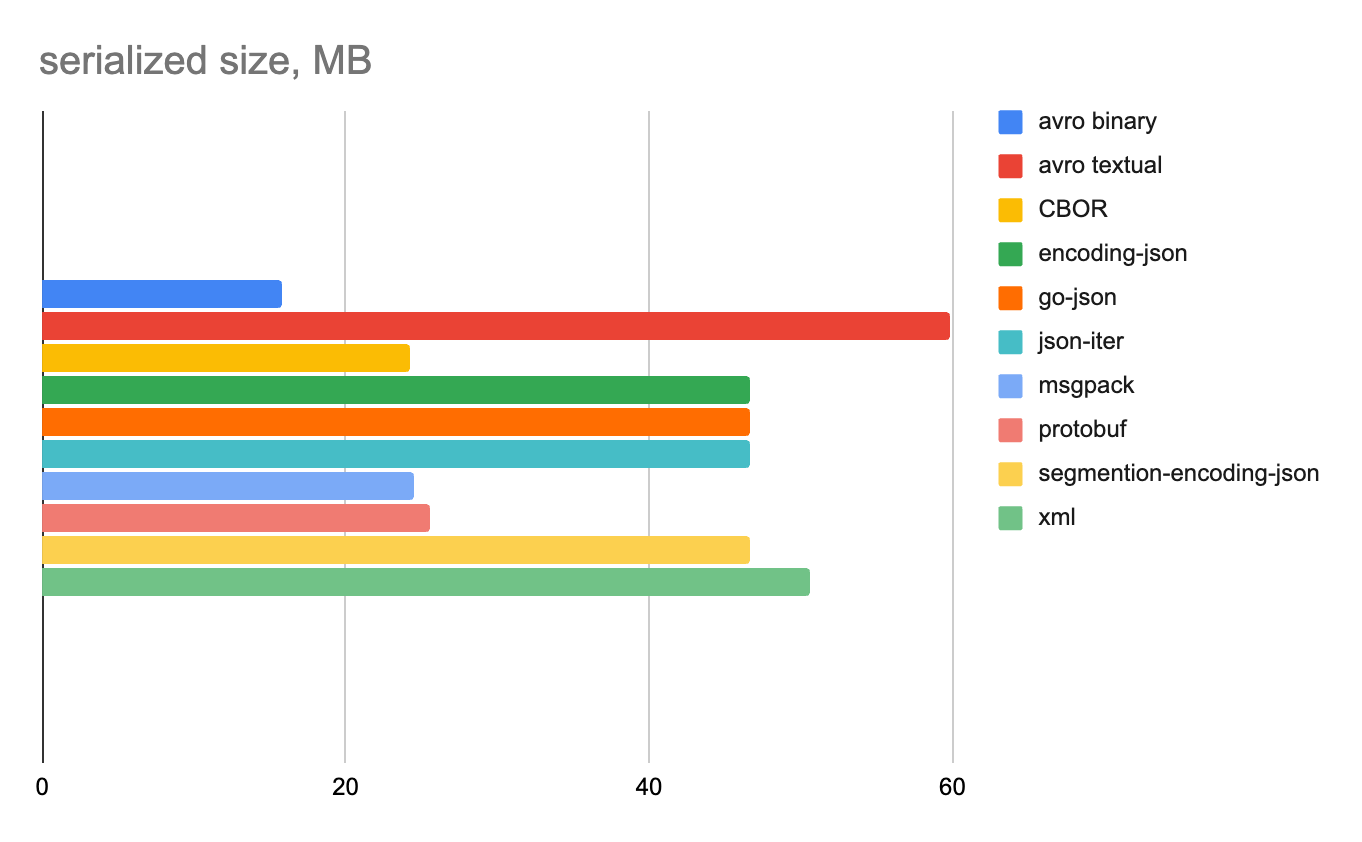
Строковые данные
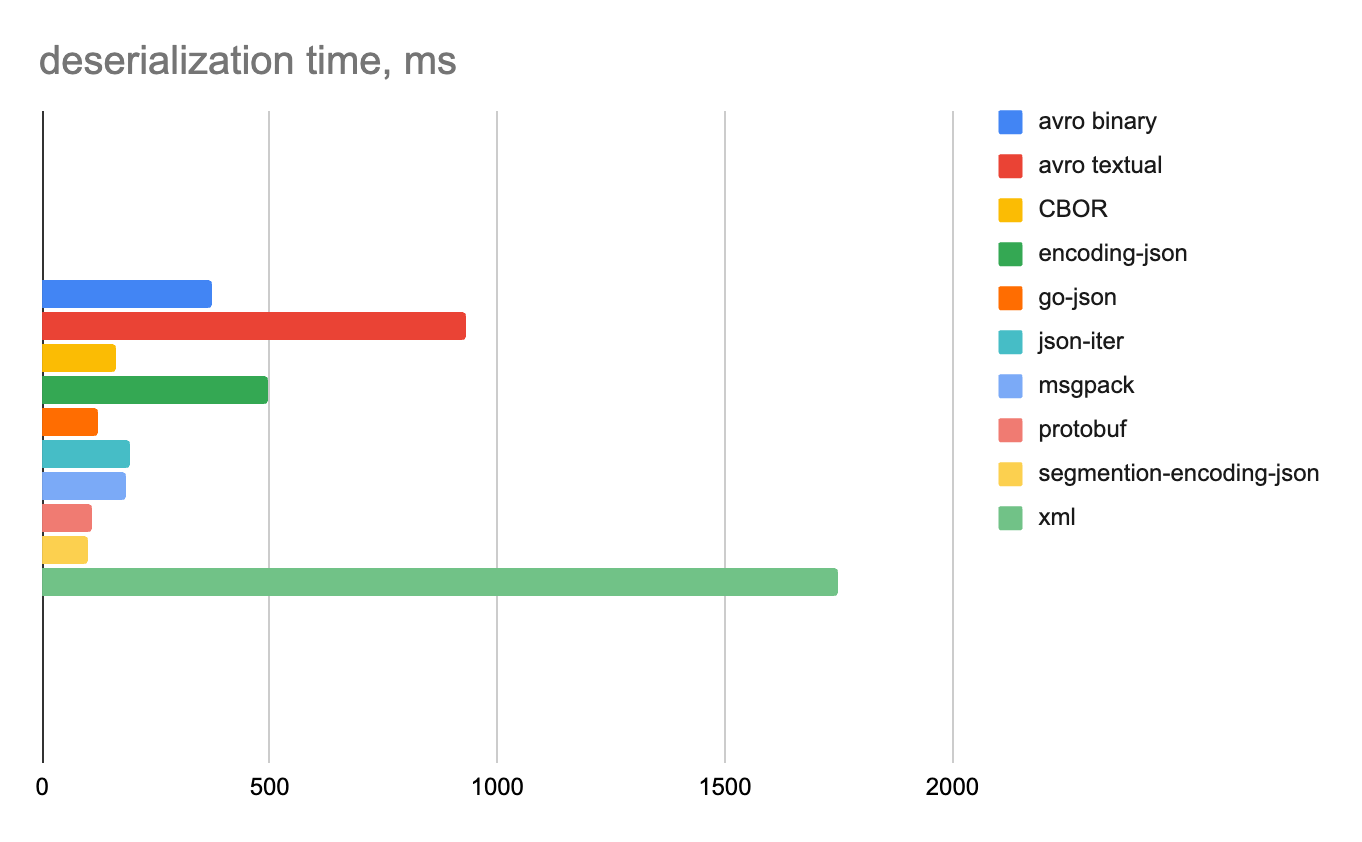
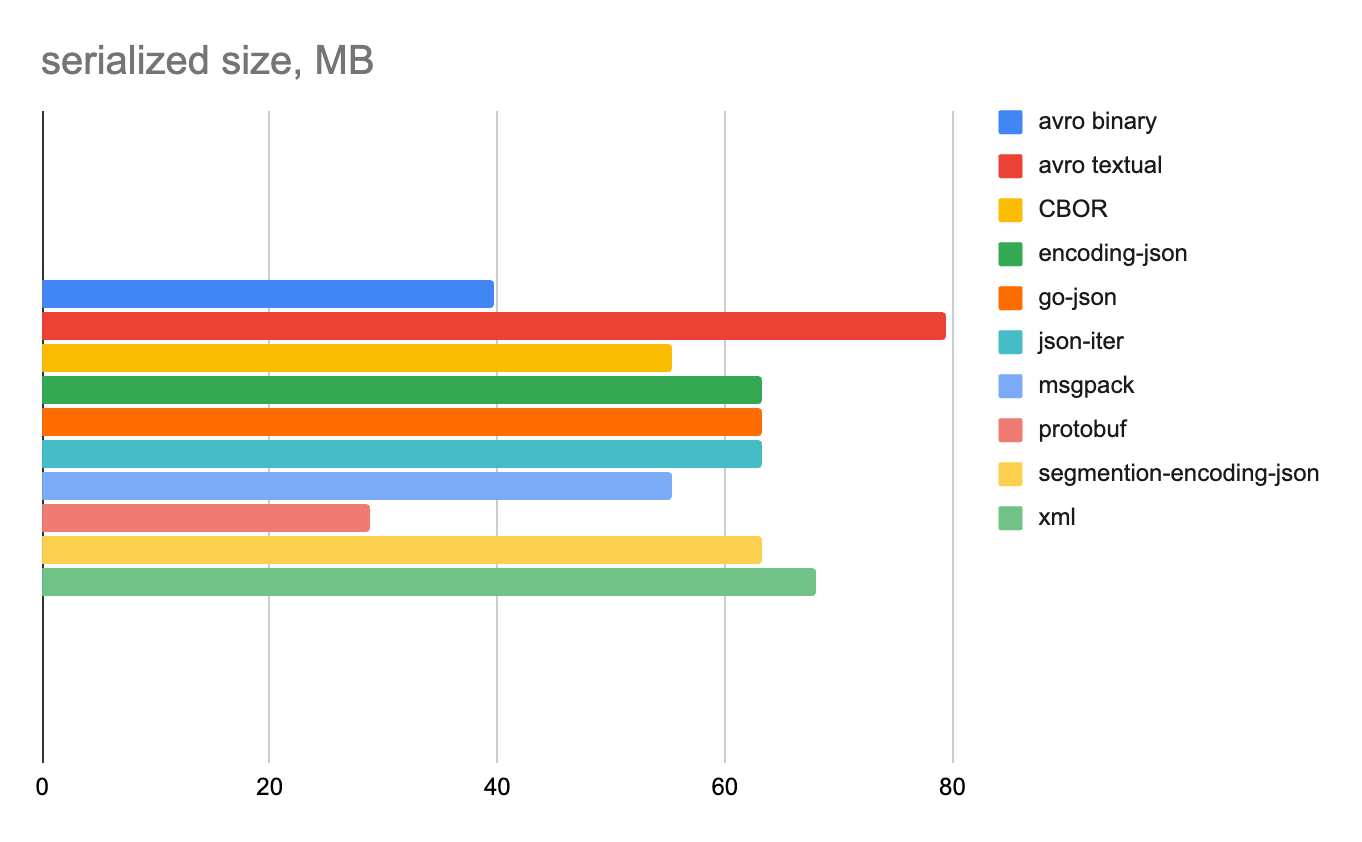
Смешанные данные
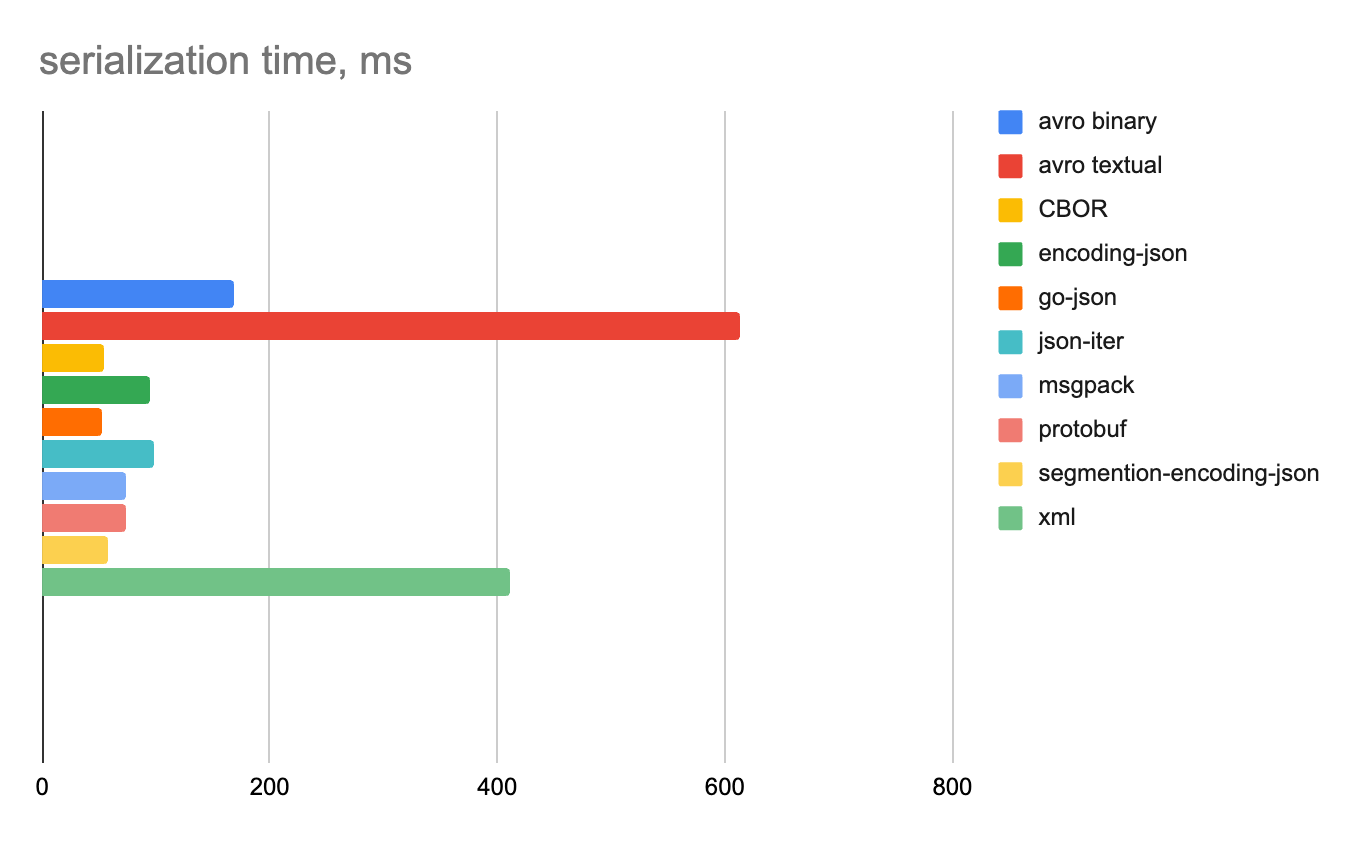
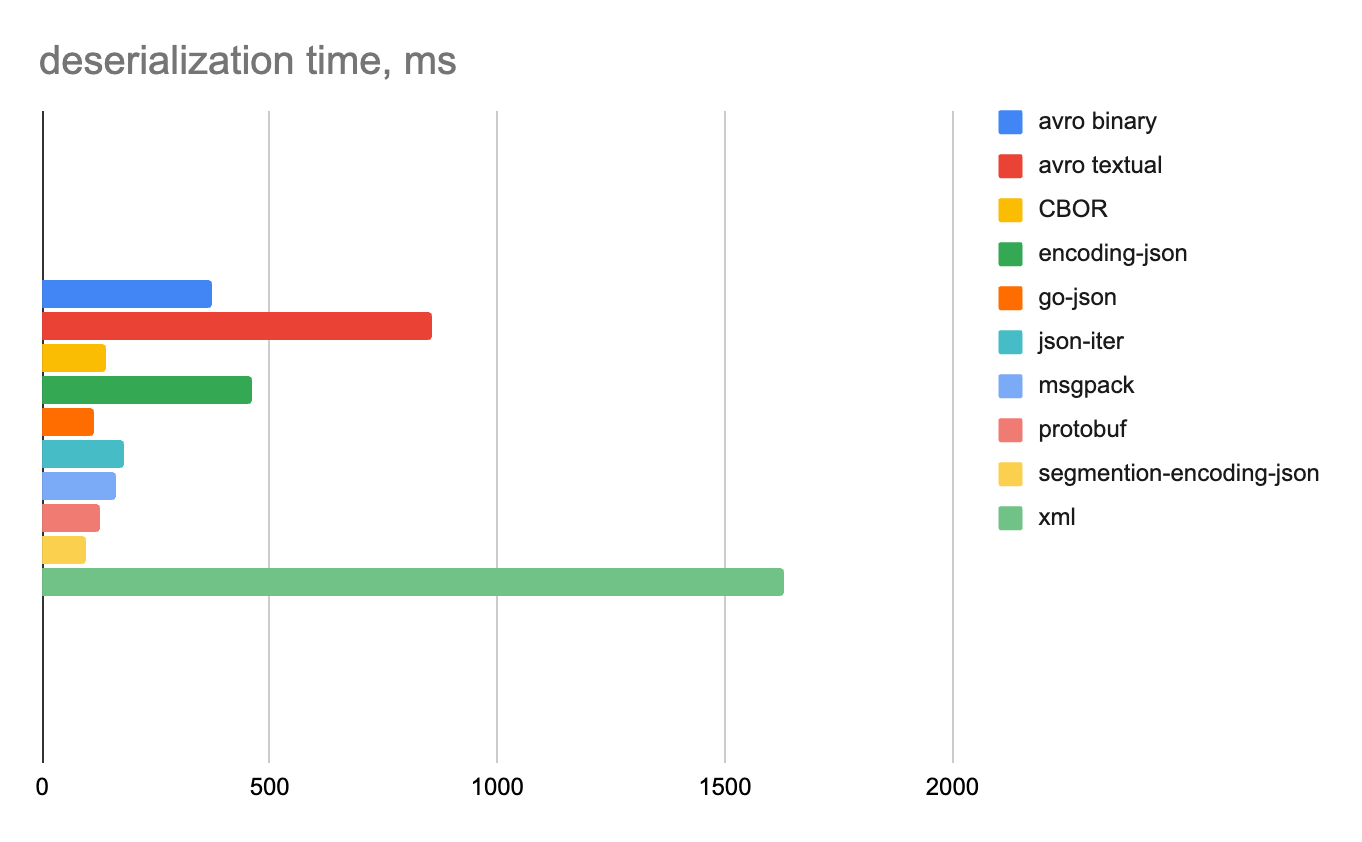
Плюсы и минусы каждого формата
Помните, что результаты могут отличаться на вашем устройстве от тех, что я привел в статье. Если говорить о преимуществах и недостатках каждого формата, вот, что я бы выделил:
Json
+ в golang довольно шустро работает по сравнению с бинарными форматами сериализации, особенно это заметно на больших объемах текстовых данных;
+ человекочитаемый формат данных;
- поддержка эволюции схемы данных ложится на разработчика, поскольку для этого формата сериализации схема отсутствует;
- система типов не поддерживает из коробки decimal, datetime, enum и прочие полезные типы, имеющиеся в других форматах сериализации (например, enum в protobuf);
- размер сериализованных данных значительно больше, чем в любом бинарном формате;
XML
+ человекочитаемый формат;
+ XSD (xml schema) позволяет парсеру не только проверить правильность синтаксиса документа, но также и его структуру, типы данных и модель содержания;
- поддержка эволюции схемы данных ложится на разработчика, поскольку для этого формата сериализации схема отсутствует;
- xml использует явные открывающие и закрывающие теги, а так же атрибуты, что добавляет дополнительные символы, в связи с этим сообщения получаются довольно многословными (исторические причины, по которым xml выглядит именно так, кратко описаны здесь);
- из-за дополнительных тегов и атрибутов также увеличивается время, требуемое на сериализацию и десериализацию, и значительно вырастает размер сериализованных данных;
Cbor
+ быстрая (де)сериализация и маленький объем сериализованных данных в сравнении с текстовыми форматами сериализации;
- поддержка эволюции схемы данных ложится на разработчика, поскольку для этого формата сериализации схема отсутствует;
- не человекочитаемый формат;
Msgpack
+ быстрая (де)сериализация и маленький объем сериализованных данных в сравнении с текстовыми форматами сериализации;
- поддержка эволюции схемы данных ложится на разработчика, поскольку для этого формата сериализации схема отсутствует;
- не человекочитаемый формат;
Avro
+ есть поддержка как бинарного, так и в текстового форматов, что может быть полезно, например при работе в тестовой среде;
+ схема данных описывается в json-формате, за счет полей в схеме достигается backward и forward compatibility;
- avro во время сериализации проводит анализ схемы, чтобы впоследствии определить каким образом обрабатывать то или иное поле, это оказывает негативный эффект на время сериализации;
Protobuf
+ быстрая (де)сериализация и маленький объем сериализованных данных в сравнении с текстовыми форматами сериализации;
+ схема данных описывается в .proto файлах, на основе которых генерируются объекты в необходимом вам языке. С помощью описанных в схеме полей достигается backward и forward compatibility (с oneof есть нюансы);
- не человекочитаемый формат;
Выбор формата сериализации зависит от конкретных требований проекта. Например, если важна человекочитаемость данных и легкая отладка, то JSON может быть предпочтителен благодаря своей простоте и широкой поддержке во многих языках программирования.
С другой стороны, если производительность играет решающую роль и необходимо передавать большие объемы данных, то бинарные форматы, такие как Protobuf или MessagePack, могут быть более эффективными. Но важно помнить, что каждый случай — частный и выбор формата сериализации зависит от конкретных потребностей проекта, учитывая требования к производительности, размеру данных, удобству отладки и поддержке в используемых технологиях.
Предыдущая статья: Повышение качества данных с использованием Zero Bug Policy

383 открытий5К показов

Всем привет! Я Ваня Ахлестин, занимаюсь поддержкой и развитием аналитической платформы кластера Search&Recommendations на базе Spark и Hadoop в Авито. Сегодня расскажу, как начать использовать ваш код из Python или PySpark и не тратить много времени дорогих разработчиков.

Авито проводит стажировку для аналитиков: присоединиться к ней могут студенты старших курсов и выпускники. Это возможность сделать первые шаги в карьере, получить опыт работы в крупной IT-компании и поработать с лучшими профессионалами на рынке. Рассказываем, какие этапы отбора надо пройти, чтобы попасть на программу, — а бонусом делимся советами от бывших стажёров и экспертов, которые общаются с потенциальными кандидатами.

Олег Харатов, Technical Unit Lead в Авито, рассказывает, как навести порядок в огромном хранилище и не сойти с ума.

В середине ноября релизнули совместное исследование Хабра и ЭКОПСИ, цель которого – составить рейтинг лучших IT-работодателей России. Мы в Avito внимательно этот рейтинг изучили, выводы сделали, и готовы вам о них рассказать.