


Повышение качества данных с использованием Zero Bug Policy
Олег Харатов, Technical Unit Lead в Авито, рассказывает, как навести порядок в огромном хранилище и не сойти с ума.
353 открытий3К показов

Привет! Я Олег Харатов, занимаю должность Technical Unit Lead в Авито. Я руковожу двумя командами: первая отвечает за Data Quality и Data Governance, а во второй мы создаем BI и IDE инструменты.
Сегодня я расскажу, как мы смогли общими усилиями минимизировать риски возникновения багов в хранении данных. Мы поговорим о том, почему в целом важно следить за качеством данных, как быстро найти и исправить ошибки в хранилище на 1 Pb и почему это поможет сохранить бизнесу деньги.
Как и где хранятся данные в Авито и почему их так много
Начнем с контекста: вот так выглядит стек технологий, которые мы используем для построения DWH.
В нем есть хранилища ClickHouse и Vertica. Сейчас мы данные из Vertica переносим в Trino — почему, рассказывали в этом видео.
Для хранилищ мы создаем разные сервисы, которые помогают искать данные и управлять ими. Сервисы мы пишем на golang и Python, данные вытягиваем из kafka, для front-end используем react. Как вы поняли, мы в DWH команде любим программировать.
Про стек в целом я рассказываю просто для того, чтобы было понятно, как именно устроены наши процессы. Если у вас все организовано по другому — ничего страшного, потому что сейчас это роли не играет. Проблемы с данными могут возникнуть в Vertica, в GreenPlum, в BigQuery и даже в Excel. Наша задача — разобраться в причинах и найти универсальное решение для любого хранилища.
Порядок в данных важен для любого бизнеса, который принимает решение на их основе. Например, компания может понять, что пора расширять географию поставок или оценить потребности клиентов. Если в хранилище данных царит хаос, бизнес упустит выгоду или будет долго принимать решение, а следовательно, потеряет деньги.
Когда мы поняли, что нужно создать продуманную систему исправления багов
Сначала мы внедряли какие-то новые решения, чтобы улучшить работу с данными, но со временем поняли, что их недостаточно. Для начала разберемся, как было организовано хранение данных в Авито.
После очисток и дедупликаций только в Vertica у нас хранится 1 Pb данных. Сначала данные загружаются в детальный слой. Для него мы используем Anchor Modeling — это шестая нормальная форма. На картинке ниже покажу, в чем ее суть.
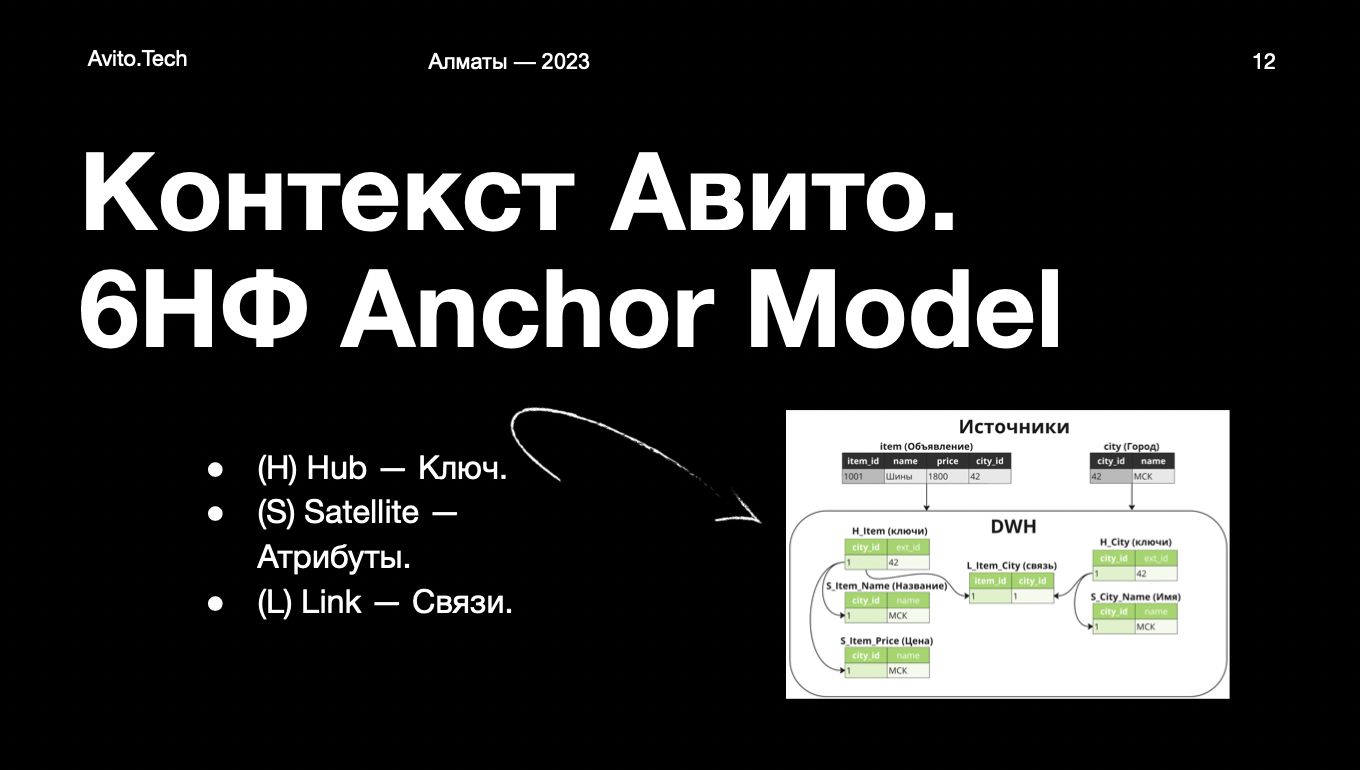
В тот момент, когда они загружаются в наше хранилище, мы получаем шесть табличек, потому что каждый атрибут в Anchor Modeling должен укладываться в свою отдельную таблицу детальнее можно прочитать в этой статье. По этой причине в детальном слое таблиц у нас очень много — несколько десятков тысяч. Наши аналитики строят витрины данных, а на них — другие витрины данных и так далее. Делают они это для того, чтобы было удобно работать с таким количеством информации.
Есть DDS-слой и существуют витрины данных, которые зависят и от себя же, и от DDS-слоя. Таких витрин у нас больше 2,5 тысяч и над тем, чтобы все данные в них посчитались, работает 17-20 воркеров.
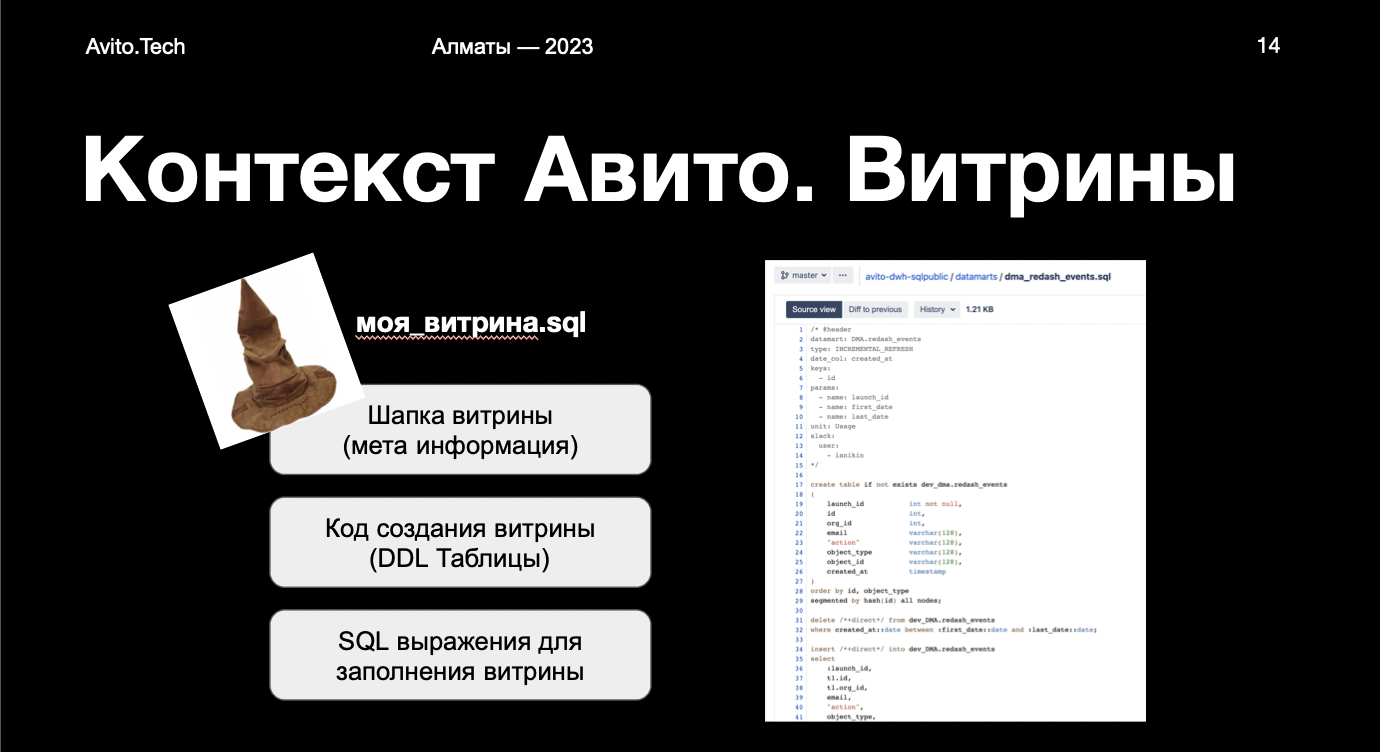
Каждая витрина — это SQL-файл, в котором есть три блока:
- Шапка. В ней хранится мета-информация — название, владелец, что является первичным ключом, как считать и так далее.
- DDL-таблица. Название DDL-витрины, куда мы будем create table.
- SQL-выражение для заполнения витрин. SQL-запросы от одного до бесконечности, которые загрузили в DDL-таблицу.
До какого-то момента все витрины в Авито вручную создавали data-инженеры. Процесс было удобно контролировать, но в то же время он был «бутылочным горлышком» в поставках: специалистов не так много, а бизнес растет. Поскольку вместе с этим растет количество аналитиков и запросов, мы пошли в сторону self-service. Тогда мы обложили витрины метриками, чтобы при публикации запускались тесты. Все функционировало отлично, но количество витрин резко увеличилось. Подробнее про витрины данных в Авито рассказывал Илья Салманов.
Сейчас в Авито работает около 300 аналитиков, которые занимаются витринами. В какой-то момент они читают их содержимое и могут возникать вопросы, например как исправить ошибки, почему сохранились не те данные и так далее. В этом случае аналитики приходят к нам, как к владельцам хранилища, и просят разобраться. Чем больше времени прошло с момента сохранения неверных данных, тем сложнее найти источник проблемы.

Чтобы быстрее реагировать на такие ситуации и в целом свести их к минимуму, мы ввели чекеры двух видов, которые автоматически запускаются при расчете любой витрины. Базовые проверяют наличие пустых строк и дублей по первичным ключам. Если есть проблемы, alert уходит нужному получателю. Бизнесовые чекеры помогают аналитикам быстро создавать проверку на бизнес-условия. Например, если бы у Авито были склады, то это позволило бы нам избежать условной ситуации, когда мы продали больше товаров, чем есть в наличии.
Чекеры помогли нам оперативно получать информацию об ошибках, но в какой-то момент стало сложно отслеживать и быстро фиксить их из-за большого объема. Количество витрин с каждым месяцем росло, при этом, мы тогда еще не определили зоны ответственности и не знали, кто и за что должен отвечать. Например, у нас был формальный оунер витрины, но не было понимания, что это действительно он должен исправлять баг.
Но на этом этапе мы поняли, что пора организовать процесс по другому и стали искать свои «слабые места».
Почему важно помнить, что не все ошибки в данных одинаковые и систематизировать их
В результате проб и ошибок мы выделили для себя несколько важных моментов, которые помогли улучшить весь рабочий процесс:
1. Все ошибки разные. Важно понимать, какие из них более срочные, чтобы решать их быстрее. Например, если совсем нет данных — это очень плохо. Если стрельнул чекер и просигналил, что две строки из миллиарда задублированы — это не всегда страшно.
Еще нужно помнить, что когда витрина загружается в хранилище, она проходит тесты. На следующий день состав данных может поменяться и джоины, которые были эффективны вчера, уже не эффективны. Владельцу нужно исправить это, чтобы поставка данных не задерживалась.
2. У всех витрин разный уровень важности. Вот, какие мы выделили:
Критичные. Витрины, на которых строится аналитика всей компании. Например, от них зависит половина хранилища или это отчеты с огромным количеством просмотров.
Важные. Например, это витрины, которые охватывают целую вертикаль. В Авито вертикалью считаются разделы — «Авто», «Недвижимость» и так далее. Просмотров у дашбордов, построенных на этих витринах, поменьше.
Стандартные. На эти витрины смотрит только несколько команд и собираются метрики.
Неважные. Например, я создал витрину и начал копить данные, чтобы использовать их в этом материале. Кроме меня ими никто пользоваться не будет, поэтому если вылезет баг, никто не обратит на него внимание.
С теорией мы разобрались — разметили витрины и баги в них по важности. Осталось самое главное — превратить все это в отлаженный рабочий процесс.
Как мы внедрили Zero Bug Policy и почему аналитики сначала с нами не согласились
Суть Zero Bug Policy заключается как раз сортировке багов, о которой я говорил выше. На какие-то из багов надо реагировать моментально, а на какие-то можно вообще забить.
Мы сделали матрицу, где указали ошибки, расставили приоритеты, например Р0 — самая критичная, Р4 — фигня. Тогда предполагалось, что исправлять баги будут ответственные за витрины аналитики.

В итоге через долгие переговоры пришли к более лайтовому решению и внесли важные дополнения в матрицу.
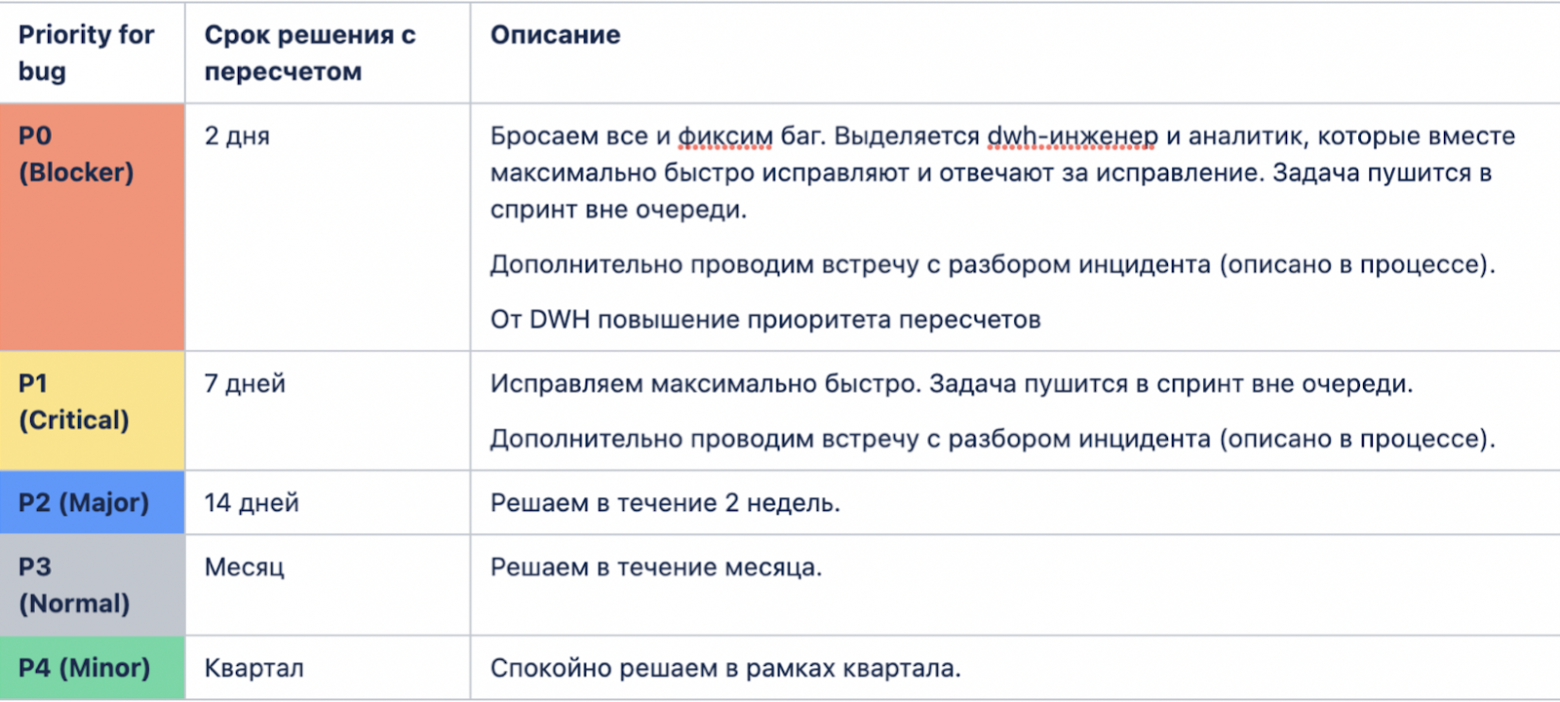
В первую очередь договорились, что если ошибка уровня Р0, то в помощь аналитикам выделяется data quality-инженер. Так мы пришли к взаимопониманию — ни одна из команд не окажется брошенной наедине с большим количеством багов. Кстати, на практике получилось так, что мы бегаем за аналитиками, которые показали большой уровень ответсвенности, и предлагаем свою помощь. Ребята, если вы это читаете, вы можете обращаться к нам!
Когда мы определились, что и как делать, перешли на стадию запуска и столкнулись с новыми сложностями.
Как мы нашли ответственных за витрины и актуализировали их
Вот так выглядит наш интерфейс по поиску витрин и их изучению.
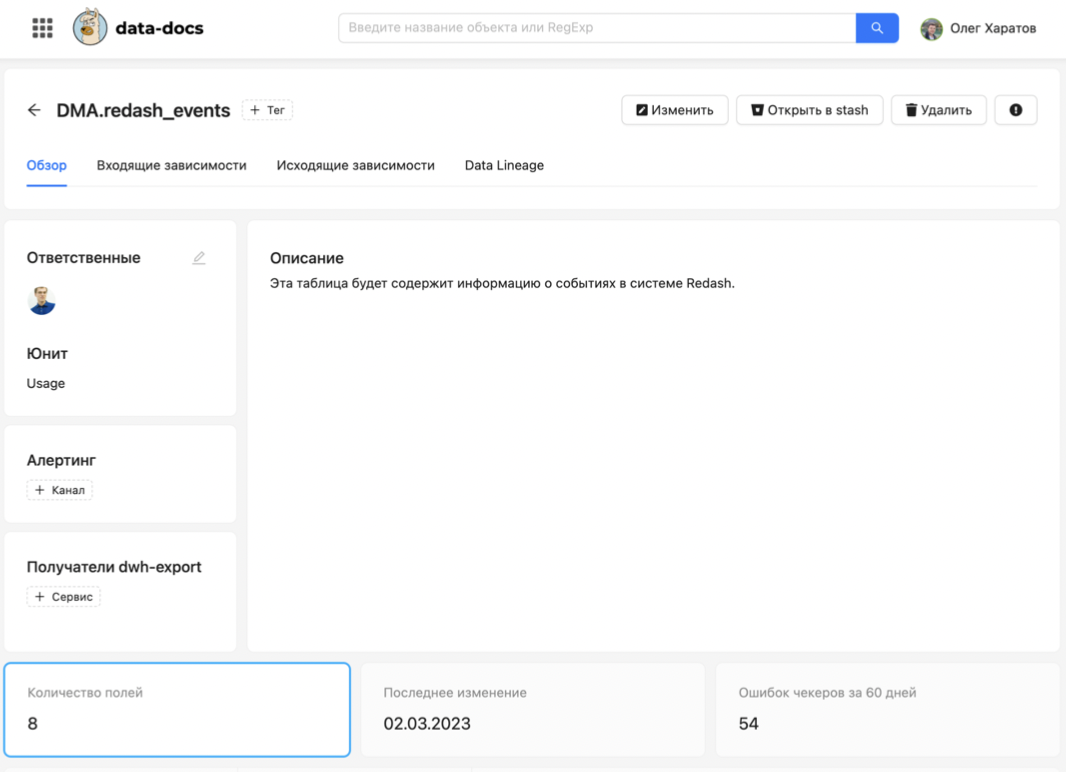
В нем можно посмотреть, кто отвечает за каждую витрину. В этот момент выяснилось, что большинство ответственных за витрины сотрудников уволились, перевелись в другие отделы.
На следующем этапе начались еще и технические сложности. Оказалось, что даже если нашелся компетентный человек, который может взять на себя роль ответственного, просто вписать его имя в систему нельзя.
Для внесения изменений в витрине нужно сделать pull request в Git, после этого запускаются тесты, а минут через 20 начинают вылезать ошибки. В итоге пришлось воткнуть в систему опцию быстрой замены ответственного. А еще сделали полезный вывод — списки сотрудников, отвечающих за витрины, надо периодически проверять. Например, если человек уволился, то логично его витрину сразу перевесить на нового ответственного.
Еще мы поняли, что нужно вовремя актуализировать важность витрины, потому что от этого зависит скорость реагирования на баги. Бизнес может довольно быстро масштабироваться и потребности в аналитике, а значит и в определенных витринах, меняются. Этот процесс тоже нужно сделать автоматическим, потому что вручную контролировать такое количество данных сложно, и доверие к системе может пропасть, если что-то пойдет не так.
Почему важно трекать процесс исправления багов
Если у вас есть бесконечное количество посуды, то ее можно не мыть, а просто ставить в раковину после использования и в какой-то момент у вас станет очень грязно. В целом, можно сказать, что мы обнаружили у себя в системе «грязную посуду». Это были некритичные баги, которые глобально не влияли на работу всей платформы, но тем не менее, их нужно было устранить.

Из-за накопленного бэклога воодушевление у команды упало почти до нуля, а ведь нас всего три человека. Нужно было не только разобраться с багами, но и выстроить работу так, чтобы эта ситуация не повторялась в будущем.
Когда из огромной кучи мусора вытаскиваешь истинные проблемы, то не замечаешь, как ты наносишь пользу. Очень важно этот момент отслеживать и трекать. Команда будет мотивироваться, если увидит, как список проблем уменьшается. Кстати, стейкхолдерам, которые выделяют на это деньги, такие отчеты тоже нужно показывать.
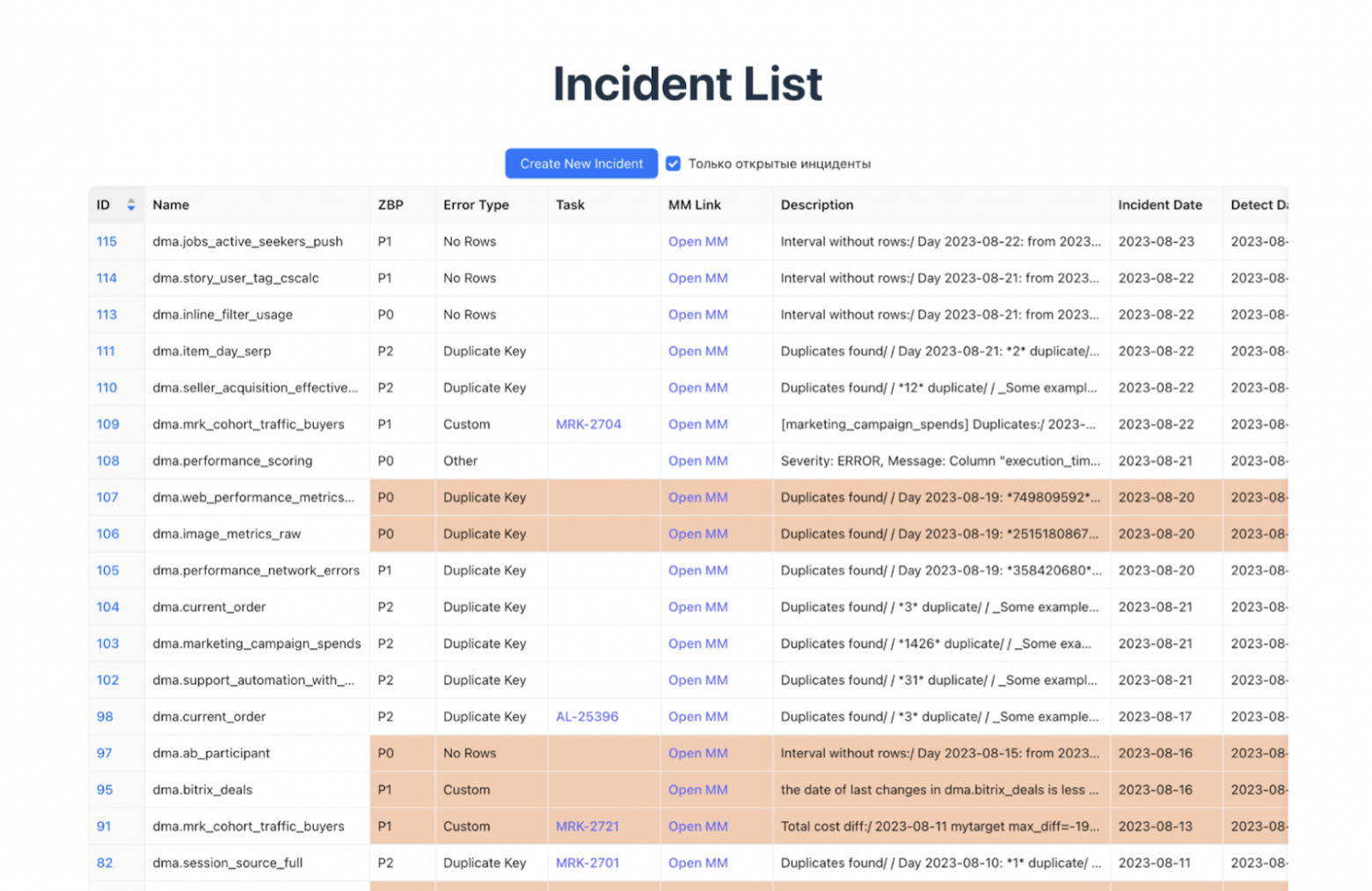
У построения треков есть несколько нюансов. Вести список багов можно в Google или Яндекс-таблицах или, например в Jira. У меня есть ощущение, что Jira слишком тяжеловесная, чтобы быстро создавать в ней новые таски. Таблицы в свою очередь могут теряться или множиться с невероятной скоростью, что тоже неудобно.
Поэтому мы пошли третьим путем: создали свою простую систему и интегрировали ее с нашим Mattermost — служебным мессенджером. На этой основе мы начали строить свою аналитику: следили, как быстро мы разгребаем баги, где есть пробелы по SLA и так далее.
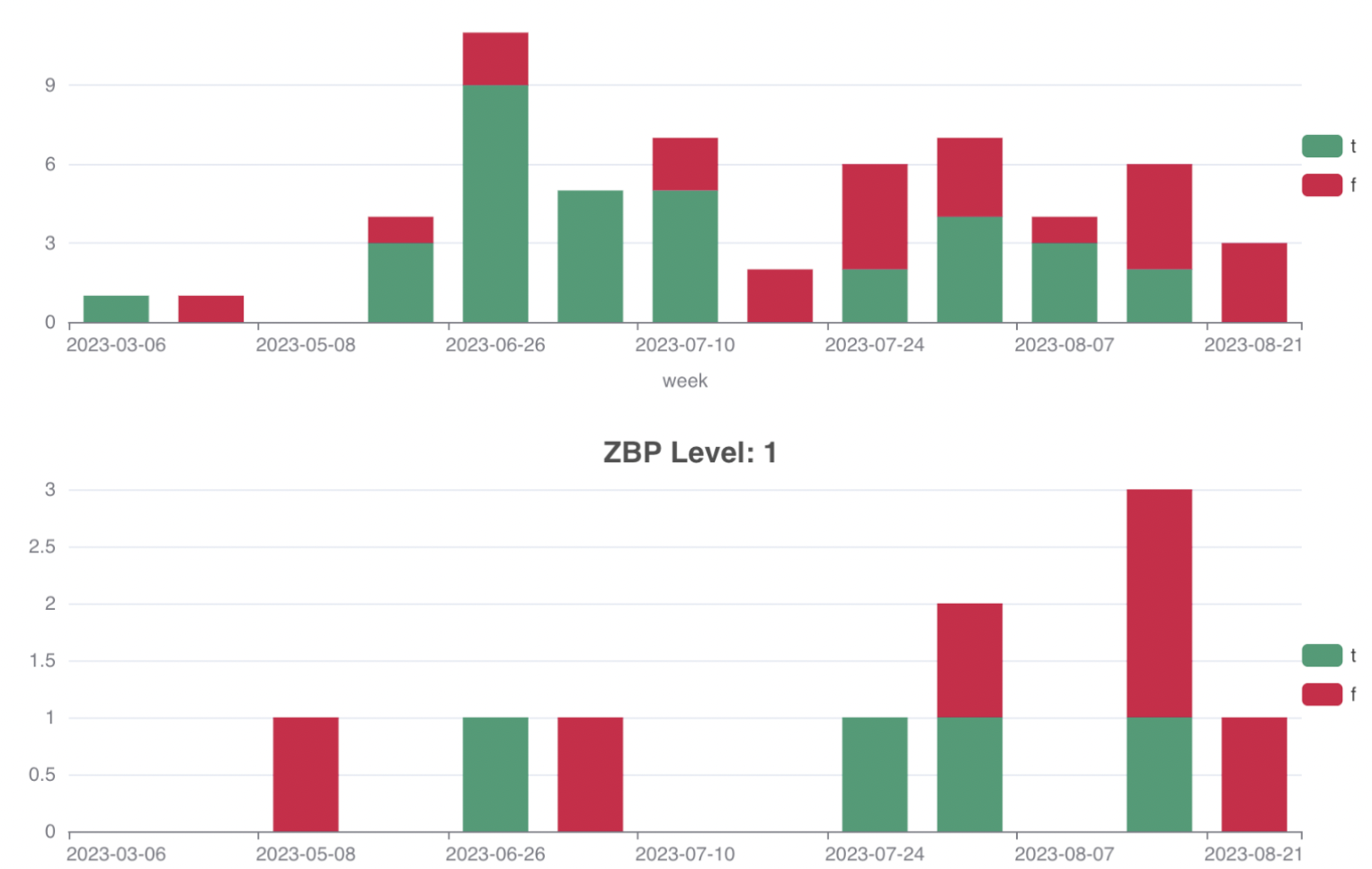
Там же мы смотрели метрику, чтобы понять, где есть повторы багов. Плохо, если один и тот же критичный баг прилетает несколько дней подряд. Со временем заметили, что стало лучше, в первую очередь потому, что мы сразу же бежали к коллегам-аналитикам и быстро все чинили.
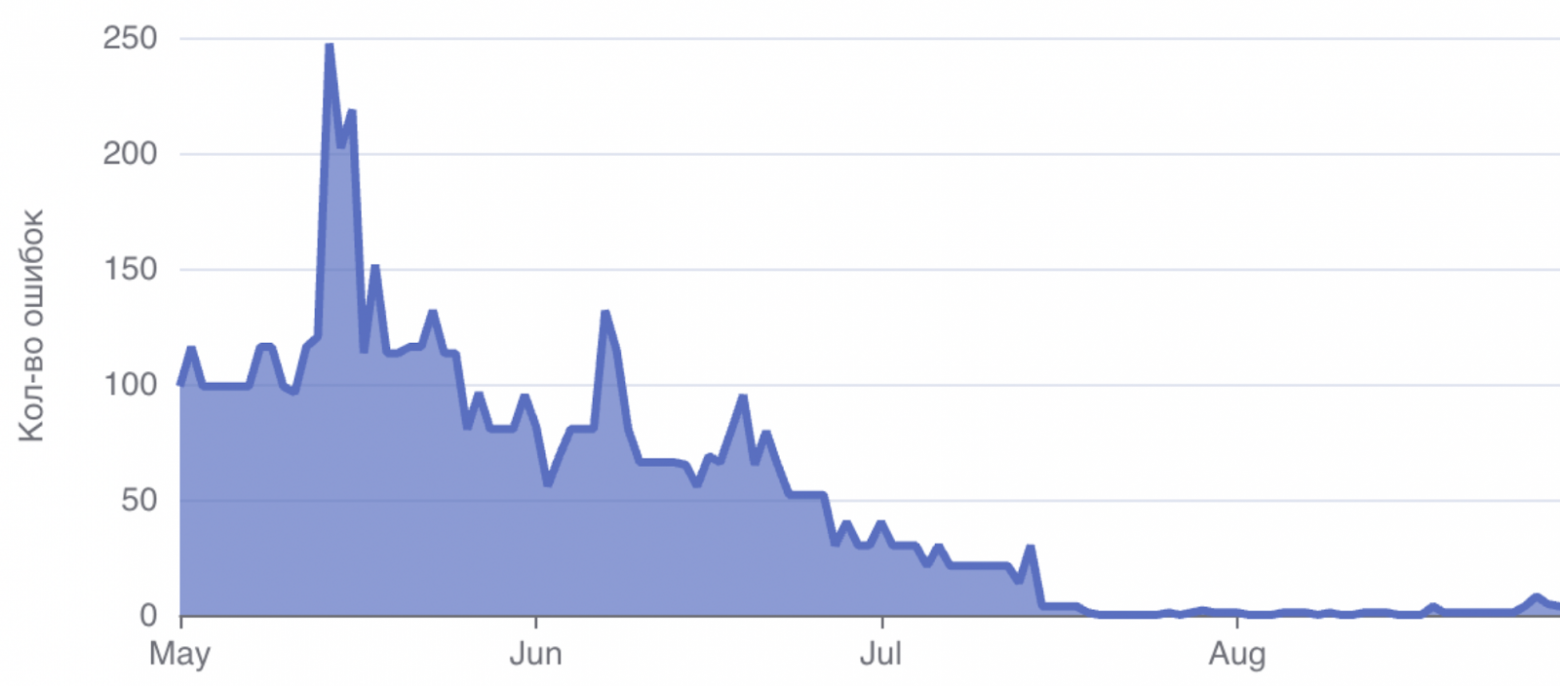
Постепенно мы разобрались со всеми накопившимися багами, актуализировали витрины и теперь работаем только с новыми задачами. На это потребовалось пол года и три инженера.
Как выглядит рабочий процесс сейчас. Спойлер: все работает автоматически
Каждое утро в наш мессенджер приходит список проблемных витрин, где указан уровень бага, ответственные и так далее.
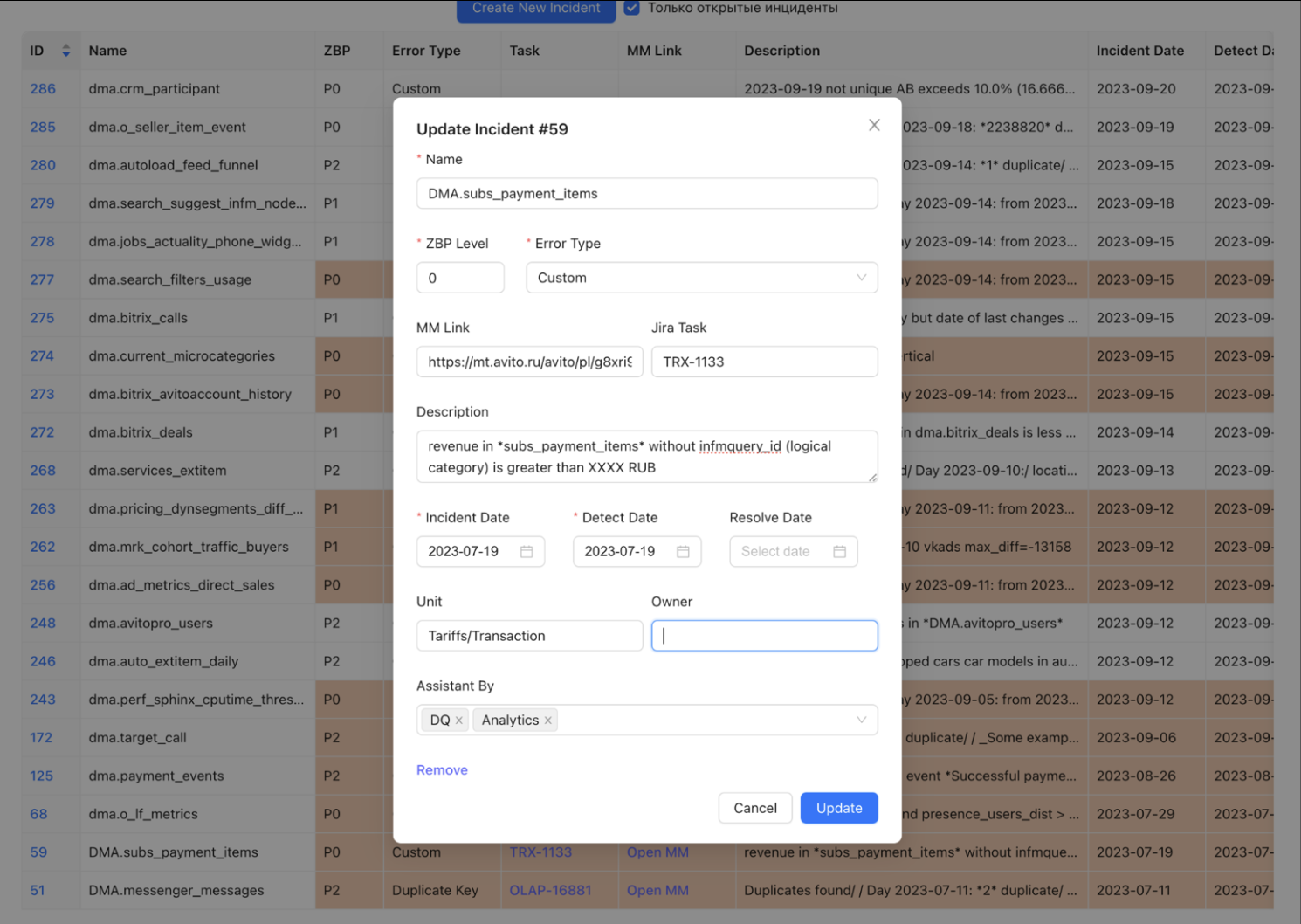
Раньше мы вручную создавали в системе запись, теперь это происходит автоматически.
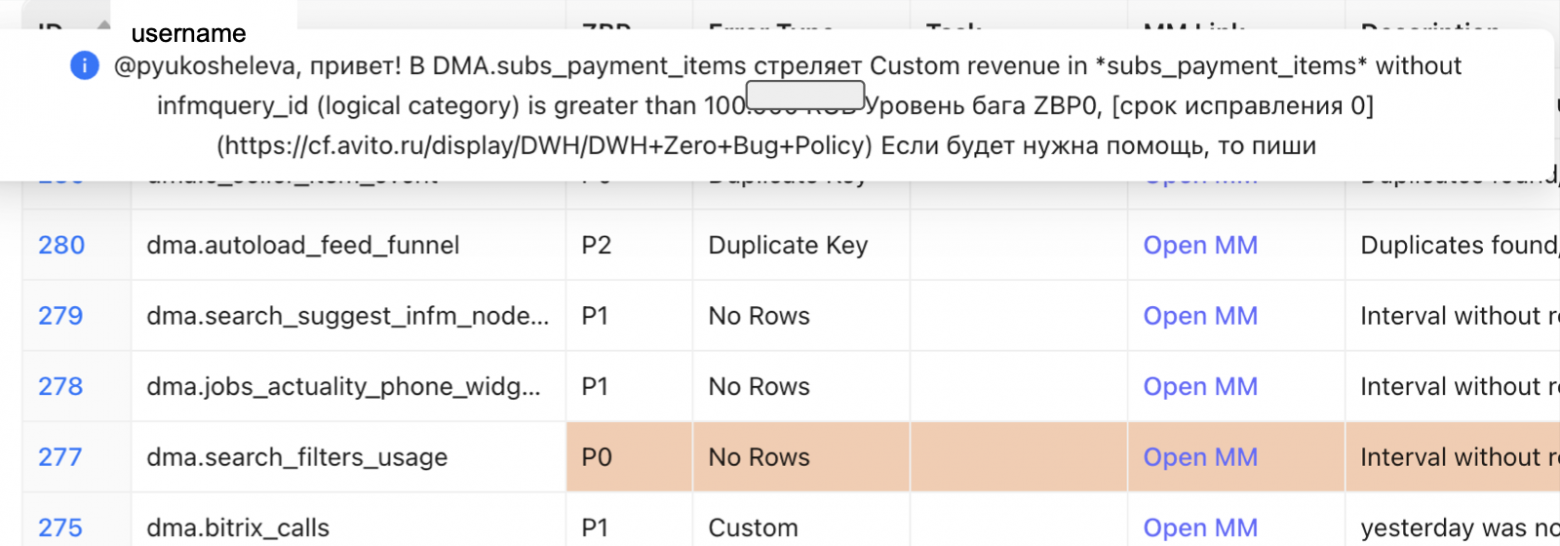
Пользователю в публичный чат уходит уведомление, что есть ошибка. Дальше обсуждаем, кто и как это будет чинить. Затем, собственно, исправляем ошибку.
Допустим, на исправление ушло два дня. После этого нужно пересчитать данные «в прошлое», потому что мы с плохим кодом жили эти два дня и лили неправильные данные в хранилище. Сейчас процесс довольно простой: заходим в нашу систему по управлению данными, открываем калькулятор, выбираем витрину и дату, за которую делаем пересчет. Указываем, надо ли по зависимостям делать пересчет вниз или нет и все.
Несколько важных выводов, которые мы сделали в процессе работы
- Прежде, чем бороться с багами в данных, оцените текущие масштабы. Если у вас десять витрин и прилетает один баг в неделю, то все, о чем я говорил выше, вам пока не нужно. Но если бизнес растет, начните с внедрения метрик. Так вы будете знать, например какой ущерб наносится, как быстро вы реагируете на это. Это те моменты, которые в будущем придется прокачивать, и чем раньше вы соберете информацию, тем проще будет разбираться потом.
- Расставьте приоритеты по багам и витринам. Возможно у вас будет своя система, не такая, как в Авито. Но в любом случае есть смысл из сотни витрин выбрать те, что используются каждый день, и те, которые лежат до востребования.
- Согласуйте свои ожидания от запуска. Убедитесь, что ответственные сотрудники знают, что и как им нужно делать, а еще лучше, пропишите это в KPI.
- Измеряйте полученные результаты. Создайте метрики и корректируйте их по мере необходимости, чтобы рабочий процесс не буксовал и команда видела свои результаты в понятных графиках или списках.
Предыдущая статья: Архивная репликация в PostgreSQL: пошаговая инструкция

353 открытий3К показов

Антон Губарев, инженер в Avito PaaS, рассказал, как реализовать межсервисную авторизацию на 2500 сервисов и ничего не сломать.

Авито проводит стажировку для аналитиков: присоединиться к ней могут студенты старших курсов и выпускники. Это возможность сделать первые шаги в карьере, получить опыт работы в крупной IT-компании и поработать с лучшими профессионалами на рынке. Рассказываем, какие этапы отбора надо пройти, чтобы попасть на программу, — а бонусом делимся советами от бывших стажёров и экспертов, которые общаются с потенциальными кандидатами.

Изучите доклады конференции AvitoTech All Day Long, сделайте буст знаний, и профессиональный взлёт не заставит ждать!

Всем привет! Я Ваня Ахлестин, занимаюсь поддержкой и развитием аналитической платформы кластера Search&Recommendations на базе Spark и Hadoop в Авито. Сегодня расскажу, как начать использовать ваш код из Python или PySpark и не тратить много времени дорогих разработчиков.