


Выбираем оптимальную архитектуру мониторинга: от легковесного сервиса до высоконагруженных кластеров


Разбираемся в различных инструментах для мониторинга, от Prometheus до масштабируемых Thanos и VictoriaMetrics, учимся правильно хранить исторические данные, совмещая несколько инструментов и агрегируя данные для оптимизации ресурсов
4К открытий25К показов

Меня зовут Александр, я работаю DevOps инженером уже 5+ лет. За свою карьеру я много раз настраивал мониторинг на разных проектах в разных компаниях с нуля и перестраивал уже работающие системы.
В этой статье я хочу поделиться знаниями в области мониторинга как маленьких проектов, так и больших кластеров. Также я расскажу о различных подходах к мониторингу и хранению исторических данных на примере таких инструментов, как Grafana, Prometheus, Thanos и VictoriaMetrics.
Уверен, что большинство разработчиков знакомы как минимум с первыми двумя проектами. Но, по моему опыту, далеко не все команды могут построить систему мониторинга, подходящую именно под их архитектуру и цели.
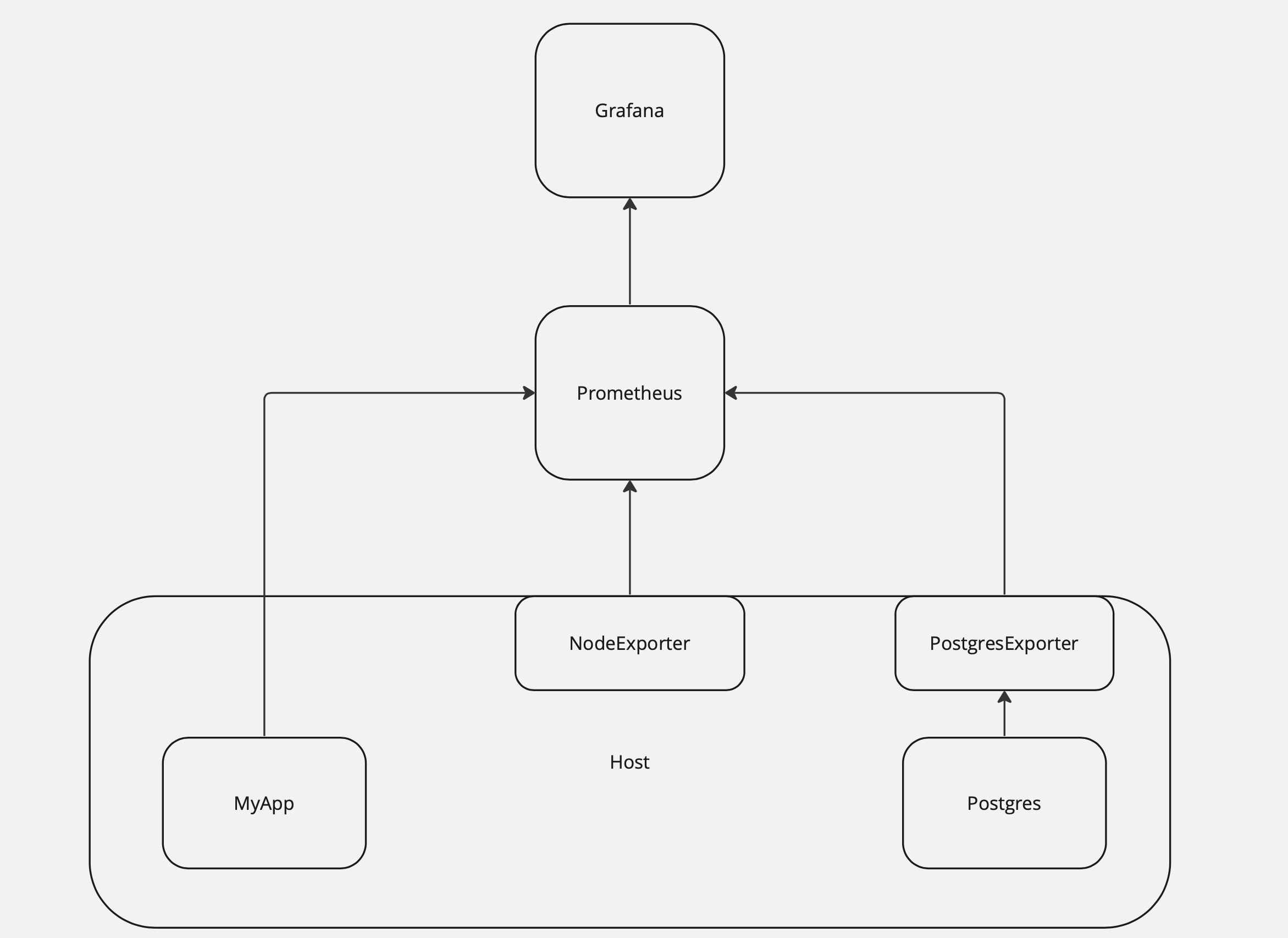
Основными инструментами для мониторинга были и до сих пор остаются Prometheus и Grafana. Думаю, что все знают, как они работают, но на всякий случай разберём в двух словах основные понятия и принципы.
Prometheus-Grafana. Основы
Prometheus — Open Source проект, свободно распространяемый под лицензией Apache License 2.0. Это одна из самых популярных на сегодняшний день Time Series Databases (TSDB). TSDB — это база данных, спроектированная специально для хранения метрик. Для запросов к Prometheus используется язык PromQL(Prometheus Query Language).
Grafana используют для визуализации и анализа данных из TSDB. Его применяют такие гиганты, как Paypall, Ebay, Siemens. Инструмент позволяет строить графики и дэшборды, настраивать алерты, легко интегрируется с другими базами данных (InfluxDB, Postgres) и имеет мощный API для кастомной интеграции.
Alertmanager — инструмент, позволяющий настроить алерты. В некоторых случаях функций Grafana бывает недостаточно для настройки алертов, и в этой ситуации стоит взглянуть в сторону гораздо более гибкого Alertmanager.
Exporter — агент, собирающий метрики и вывешивающий их на определённом порту. На сайте Prometheus можно найти полный список экспортеров, официальных и нет.
Метрики собираются с помощью exporter с мониторящегося узла/базы данных и выставляются им на определенный порт или же отдаются самим приложением. По умолчанию Prometheus сам скрейпит эндпойнты, это называется pull модель сбора метрик.
Для сценариев, где требуется работать с push моделью, у Prometheus есть механизм PushGateway, который принимает отданные метрики и хранит их там до тех пор, пока Prometheus их не заберет.
После того, как данные попали в Prometheus, остаётся подключить datasource в Grafana и настроить дэшборды. У Grafana есть огромная база уже готовых дэшбордов, импортируемых нажатием одной кнопки, поэтому, прежде чем создавать кастомный дэшборд, проверьте, нет ли необходимого дэшборда в списке на сайте Grafana.
Ниже представлена краткая схема взаимодействия этих компонент.
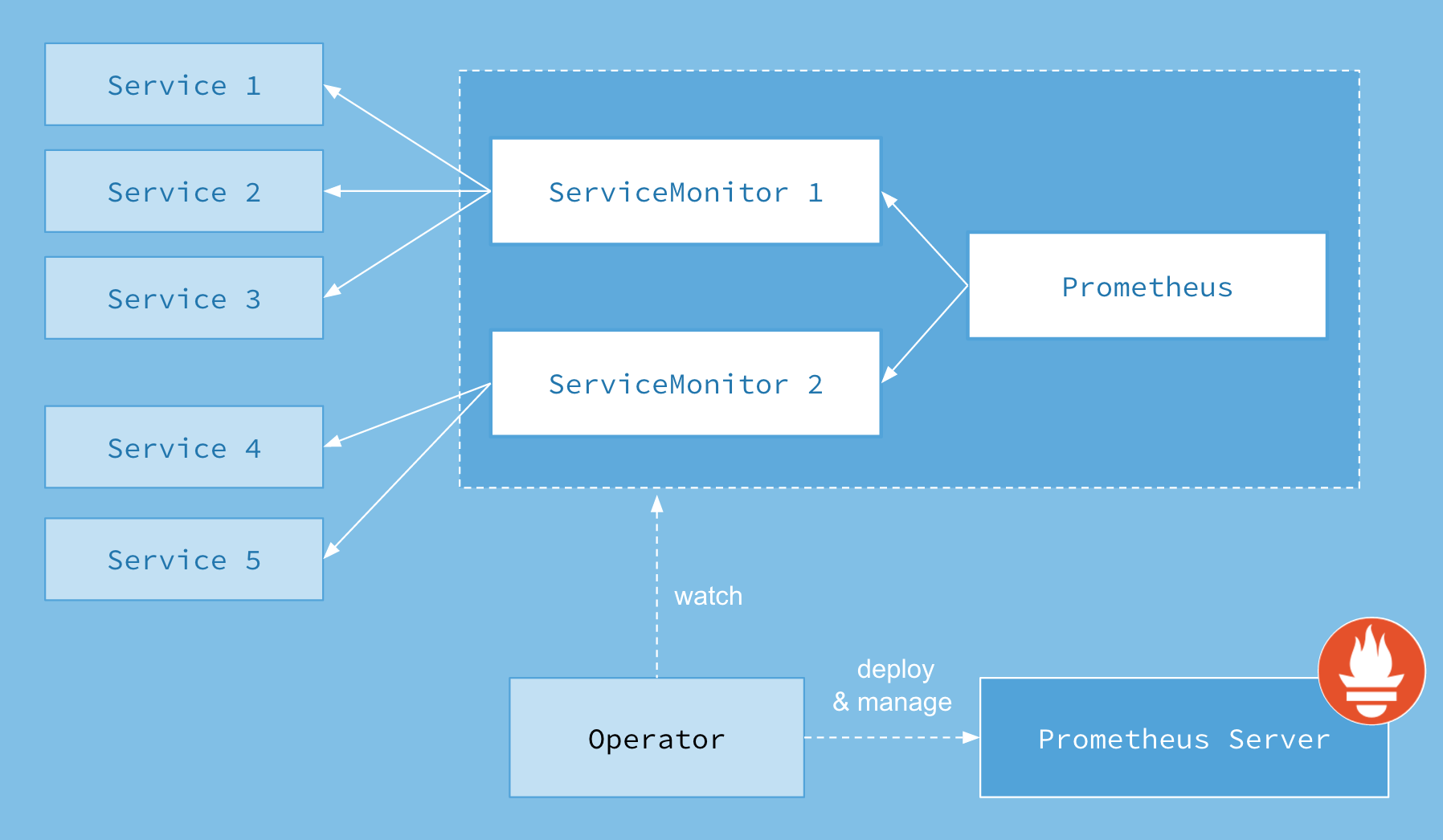
Мониторинг Kubernetes кластера. Prometheus Operator
Архитектура, описанная выше, неплохо работает на петпроектах. В реальности же мы скорее всего будем поднимать мониторинг для целого Kubernetes кластера. Для мониторинга кубового кластера отлично подойдет Prometheus Operator, который реализован как обычный Kubernetes Operator, разворачивается с помощью Helm и создан для максимально Kubernetes-нативного процесса конфигурации Prometheus. С его помощью можно поднять полноценный мониторинг кластера за час.
Prometheus Operator состоит из следующих компонент, реализованных в виде CRD (Custom Resource Definition):
- Prometheus – определяет желаемый deployment Prometheus.
- Service Monitor – определяет, как следует отслеживать группы сервисов Kubernetes. Он автоматически генерирует конфигурацию Prometheus scrape на основе текущего состояния объектов.
- Alertmanager – определяет желаемый deployment Alertmanager.
Одной из отличительных фичей Prometheus Operator является автоматические обнаружение и конфигурация таргетов, которая под капотом имеет механизм куберовских лейблов и селекторов. Она позволяет сэкономить много времени, так как процесс раскатки на большом нагруженном кластере займет не сильно больше времени, нежели на minikube.
Ниже приведена высокоуровневая схема его работы.
Масштабирование и исторические данные. Thanos
Что делать, если нам необходимо мониторить сразу несколько кластеров? Или если один экземпляр Prometheus не справляется с нагрузкой? Самое время думать о масштабировании. И тут начинается самое интересное.
У Prometheus есть несколько серьёзных недостатков. Во-первых, он не позволяет сделать Global Query и собрать данные с нескольких экземпляров Prometheus. Во-вторых, Prometheus не умеет масштабироваться.
Можно разделить таргеты по разным серверам, но тут мы возвращаемся к проблеме №1. Соответственно, и по объему хранимых метрик, и по ресурсам мы ограничены одним сервером.
И последнее, наверное, самое критичное: Prometheus не адаптирован для хранения исторических метрик. Он был создан и поддерживается разработчиками как TSDB для хранения «горячих» данных. Нас ждёт неприлично большое потребление памяти и ресурсов, так как мы не можем проагрегировать старые данные. Поэтому, если перед вами встает цель хранить исторические метрики или же просто нормально масштабироваться из-за выросшего объема метрик – стоит присмотреться к следующим решениям:
Thanos – еще один Open Source проект, разработанный компанией Improbable, который расширяет обычный Prometheus до полноценно масштабируемого хранилища исторических метрик. Он решает проблему масштабируемости, используя sidecar – дополнительный контейнер к каждому экземпляру Prometheus в кластере, который работает с локальными данными конкретного сервера Prometheus.
Для централизованного извлечения данных используется компонент Querier, работающий с сайдкарами, сначала подключаясь к ним и извлекая данные с необходимых Prometheus, а потом объединяя их в единое целое для выполнения к ним пользовательского запроса. Языком запроса будет все тот же PromQL, который Thanos поддерживает.
Ниже представлена схема работы этих компонент:
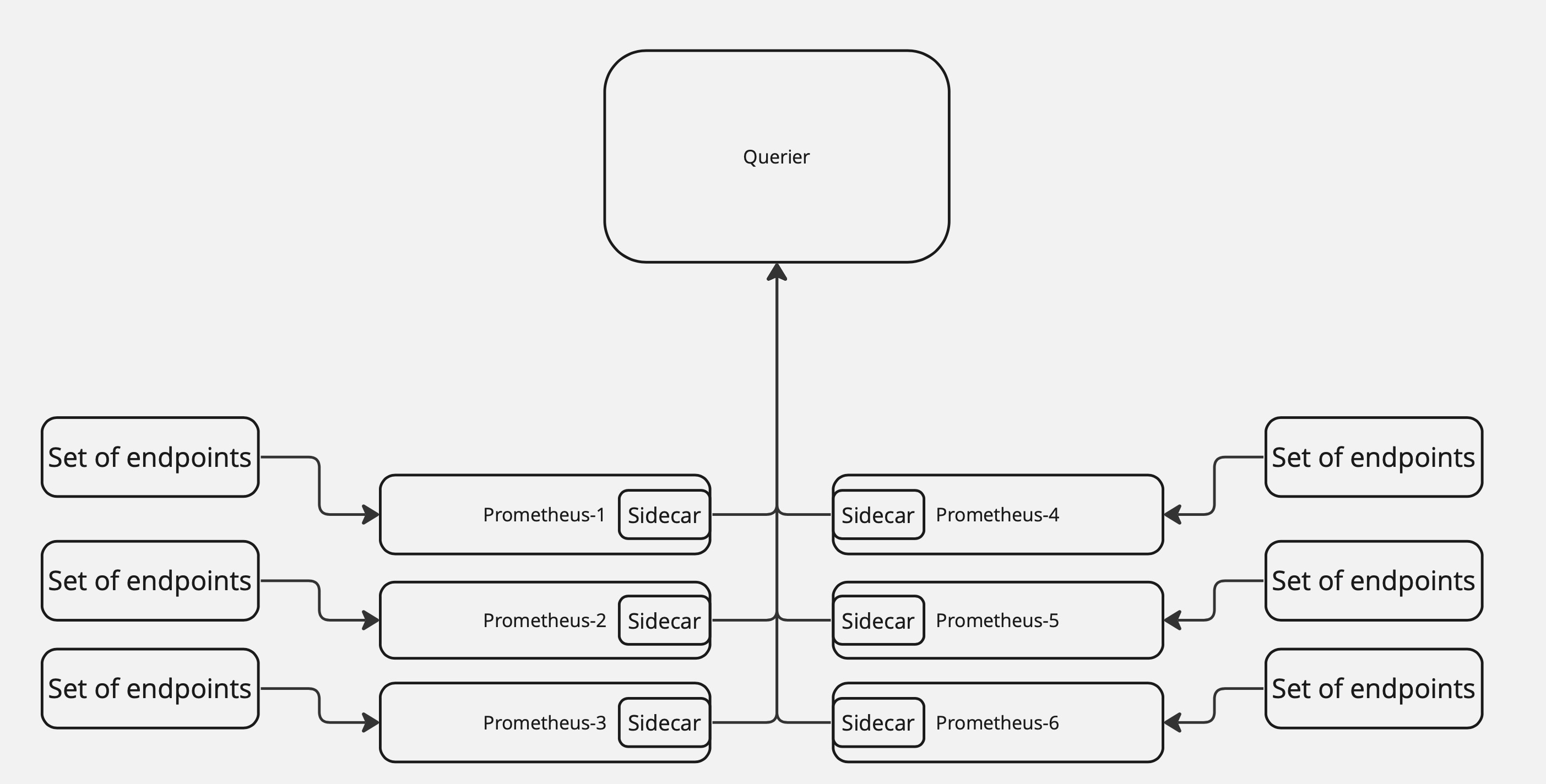
Для оптимизации хранения исторических метрик Thanos использует объектные хранилища и регулярно отгружает туда данные. В объектных хранилищах данные агрегируются с помощью компоненты Compactor. В целом, это очень мощное решение, используемое сегодня во многих больших компаниях.
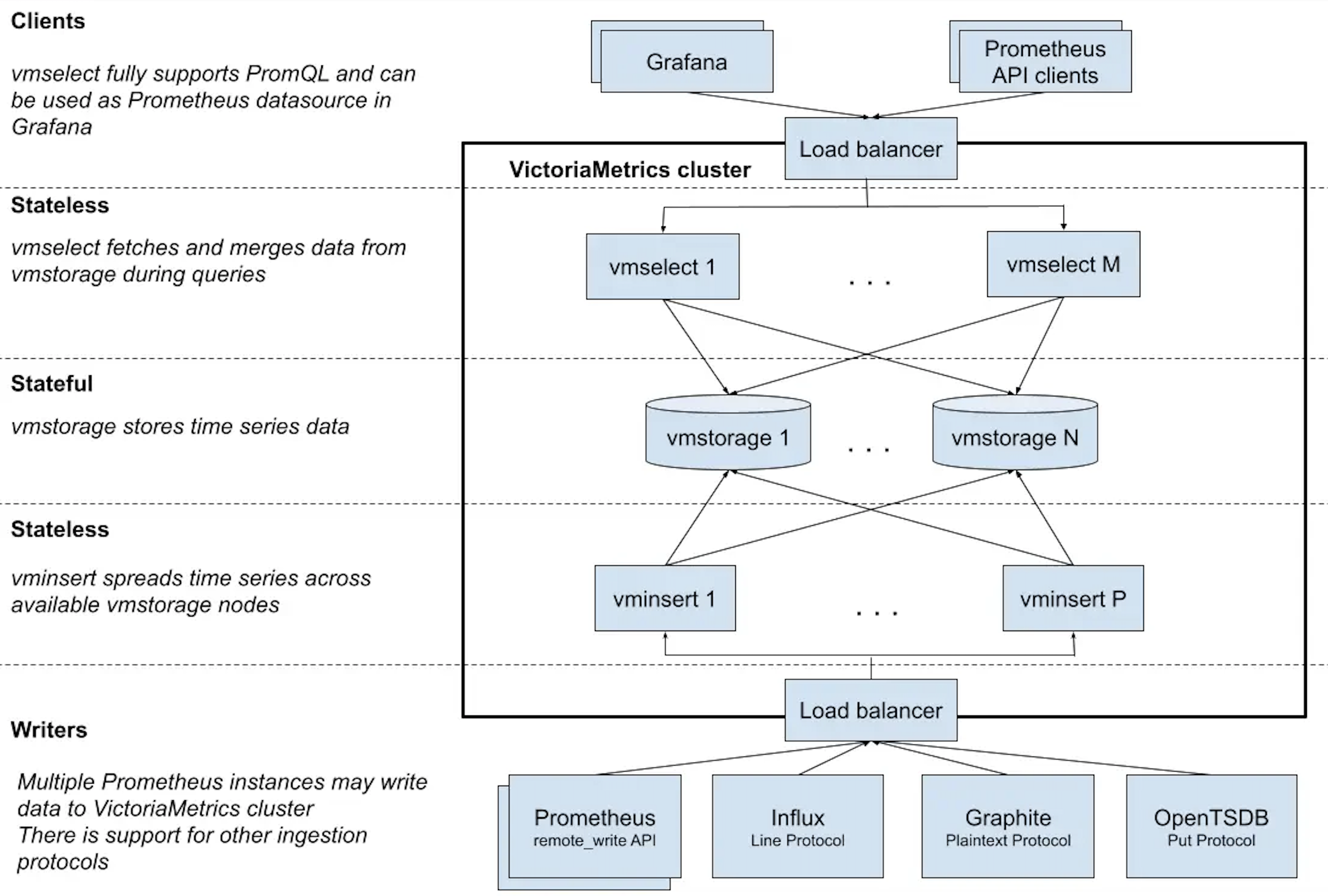
VictoriaMetrics или опять про масштабирование
Вторым решением, оптимизирующим хранение исторических метрик станет VictoriaMetrics – TSDB база, реализованная с учетом специфики долгосрочного хранения и сжатия данных и оптимизированная с точки зрения потребления ресурсов. Ее можно использовать в дополнение к Prometheus, регулярно отгружая туда необходимые данные с помощью механизма remoteWrite, в дальнейшем агрегируя их уже внутри самой Виктории. Она также поддерживает PromQL, позволяет сделать Global Query, так как является централизованным хранилищем для нескольких Prometheus.
Существуют две версии VictoriaMetrics – Single Node и Cluster. Версия Single Node гораздо проще в установке и конфигурации, и сами разработчики Виктории рекомендуют использовать ее, если количество обрабатываемых датапойнтов не превышает 1 миллиона в минуту. В случае с Single Node все нижеперечисленые компоненты находятся в одном бинарнике.
В случае, если мы хотим построить гибкую и масштабируемую систему, стоит рассмотреть поближе кластерную версию. VictoriaMetrics Cluster состоит из следующих компонент:
vminsert – принимает разноформатные данные и записывает их в storage.
vmselect – принимает PromQL запросы, выполняет сбор данных в vmstorage, процессинг данных и возвращает результат.
vmstorage – хранит и возвращает запрошенные данные в заданном временном интервале.
Помимо этого также существуют другие компоненты для бэкапов и алертинга, например – vmbackup, vmrestore, vmalert и т. д. Об этом тоже много есть на просторах сети и в самой документации Виктории, думаю, что подробное описание выходит за рамки этой статьи.
Ниже представлена схема работы стека Prometheus/Influx/Graphite-Grafana с использованием Виктории в качестве основного хранилища метрик.
В этой статье я сделал обзор наиболее популярных сейчас архитектур мониторинга, которые я когда-либо видел/строил/поддерживал, основываясь на своем опыте и проблемах, с которыми приходилось сталкиваться.
Надеюсь, что она будет полезна тем кто будет или уже сейчас строит мониторинг для нового проекта или же меняет уже существующую архитектуру. Буду рад комментариям и вопросам, с радостью на них отвечу.

4К открытий25К показов

Сравнение реальных доходов курьеров и айтишников в 2025: автокурьеры в Москве получают до 160 тыс. ₽, но junior-разработчики за 2 года вырастают до 200+ тыс. ₽. Роботы заменят 30% доставок к 2030, а в IT кризис новичков не отменяет зарплаты мидлов от 350 тыс.

Акционеры Intel подали иск против компании и экс-главы Пэта Гелсингера, обвиняя их в убытках и завышенных прогнозах. Требуют возмещения $207 млн

Зачем разработчику знать SQL, если есть NoSQL. Показываем основные отличия SQL и NoSQL. Рассматриваем пошаговую инструкцию и важные особенности ✔ Tproger

В США нашли магнитную ленту с Unix V4 1973 года. Ее восстанавливают побитово — это может стать важнейшим открытием в истории ОС