


Как использовать микросервисы в веб-разработке — возможные проблемы и их решения

Специалист из компании «Рексофт» расскажет о технических сложностях, которые возникают при работе с микросервисами, и поделится способами их решения.
19К открытий19К показов

Вадим Корнеев
старший инженер-программист практики Java компании «Рексофт»
В ИТ редко встретишь человека, который не слышал о микросервисах. В интернете и на профильных сайтах на эту тему есть масса статей, которые в целом хорошо объясняют отличия между монолитом и, собственно, микросервисами. Неискушенный разработчик Java, прочитав статьи из разряда «Что такое микросервисы для web-приложений и с чем их едят», преисполняется радости и уверенности, что вот теперь-то всё станет замечательно. Ведь главная цель — «попилить» монструозный монолит (конечный артефакт, который, как правило, представляет собой war/ear файл), выполняющий кучу всего, на ряд отдельно живущих сервисов, каждый из которых будет выполнять строго определённую, относящуюся только к нему функцию, и будет делать это хорошо. В дополнение к этому идёт горизонтальная масштабируемость — просто делай scaling соответствующих узлов, и всё будет здорово. Пришло больше пользователей или требуется больше мощностей — просто добавил 5–10 новых инстансов сервисов. Грубо говоря, в целом так это и работает, но, как известно, дьявол кроется в деталях, и то, что изначально казалось довольно простым, при более внимательном рассмотрении может обернуться проблемами, которые первоначально в расчёт никто не брал.
Как добиться транзакционной целостности данных
При попытке перевести архитектуру с монолита на микросервисы команды, у которых до этого не было такого опыта, часто начинают дробить сервисы по верхнеуровневым объектам доменной модели, например: User/Client/Employee и т. д. В дальнейшем при более детальной проработке появляется понимание, что разбить удобнее на более крупные блоки, агрегирующие внутри себя несколько объектов доменной области. За счёт этого можно избежать лишних вызовов в сторонние сервисы.
Вторым важным моментом является поддержка транзакционной целостности данных. В монолите эта задача решается посредством Application Server, где крутится war/ear, внутри которого контейнер, по сути, очерчивает границы транзакций. В случае с микросервисами границы транзакций размазываются и появляется необходимость помимо написания кода бизнес логики иметь возможность управлять целостностью данных, поддерживать их согласованность между разными частями системы. Это довольно нетривиальная задача. Рекомендации по решению подобного рода архитектурных проблем можно найти в интернете и в соответствующих технических сообществах.
В данной статье я попробую дать описание конкретных технических сложностей, возникающих при попытке команд работать с микросервисами, и пути их решения. Сразу замечу, что предложенные варианты не являются единственно верными. Возможно, есть более изящные сервисы, но те рекомендации, которые я приведу, проверены на практике и точно решают имеющиеся сложности, а использовать их или нет — личное дело каждого.
Основная проблема в работе с микросервисами в том, что их крайне легко запустить локально (например, используя spring.io и intellij idea, это можно сделать буквально за 5 минут, а то и меньше). Однако при попытке сделать то же самое в Kubernetes кластере (если до этого у вас было мало опыта работы с ним) простой запуск контроллера, печатающего «Hello World» при обращении к определенному endpoint, может занять полдня. В случае с монолитом ситуация проще. У каждого разработчика есть локальный Application Server. Процесс деплоя также достаточно прост — необходимо скопировать конечный артефакт war/ear в нужное место в Application Server вручную или средствами IDE. Обычно с этим не возникает проблем.
Нюансы отладки
Вторым важным моментом является отладка. В ситуациях с монолитом предполагается, что у разработчика на его машине стоит Application Server, на который деплоится его war/ear. Всегда можно провести отладку, т. к. всё, что нужно, есть под рукой. С микросервисами всё немного сложнее, сервис обычно представляет собой вещь в себе. Как правило, он имеет свою собственную схему БД, в которой лежат его данные, выполняет специфичные, присущие только ему функции, всё общение с другими сервисами организовано через синхронные HTTP вызовы (например через RestTemplate или Feign), асинхронные (например Kafka или RabbitMQ). Поэтому простая по сути задача сохранения или валидации некого объекта, которая раньше была реализована в одном месте, внутри одного war/ear файла, в общем случае с микросервисным подходом становится представима в виде: сходить в один или N смежных сервисов, будь то операции получения данных, например неких справочных значений, или операция сохранения смежных сущностей, данные которых нужны для выполнения бизнес логики в нашем сервисе. Прописывать бизнес логику в таком случае становится намного труднее. Соответственно, варианты решения таковы:
- Написать свой код бизнес логики. Все внешние вызовы при этом мокаются (mock) — эмулируются внешние контракты, пишутся тесты в рамках допущений, что внешние контракты именно такие, после этого происходит деплой в контур для проверки. Иногда везёт, и интеграция работает сразу, иногда не везёт — приходится переделывать код бизнес логики n-ое количество раз, т. к. за то время, что мы реализовывали функциональность, код в смежном сервисе был обновлён, сигнатуры API изменились и нам надо переделывать часть задачи на своей стороне.
- Следствием из пункта 2 является отладка. Надо либо обильно логировать всё, что можно, и потом вдумчиво читать логи после деплоя в Kubernetes, т. к. мы помним, что воспроизвести полноценно ситуацию локально нельзя — нет интеграции с нужными сервисами, либо необходимо подключаться по remote debug в контур. Становится немного лучше в плане того, что уже можно в runtime посмотреть, что и как, но есть и минусы. Во-первых, не всегда этот процесс бывает быстрым, можно запустить выполнение операции в режиме отладки и ждать 2–5 минут, т. к. по факту мы можем быть не в той сети, где Kubernetes кластер, а накладные расходы по сети никто не отменял. Во-вторых, надо не забывать ставить режим отладки для каждого потока отдельно (Per thread), иначе пока вы отлаживаетесь, все остальные смело могут идти курить.
Решение проблемы дебага в кластере Kubernetes
Вариантом решения данного вопроса, по сути, является telepresence. Вероятно, есть и другие программы подобного рода, но личный опыт был только с ним, и он зарекомендовал себя положительно. В целом принцип работы таков:
На локальную машину разработчик ставит себе telepresence, настраивает kubectl для доступа к соответствующему Kubernetes кластеру (добавляет конфигурацию контура в ~/.kube/config). После этого запускается telepresence, который по факту выступает в качестве proxy между локальным компьютером разработчика и Kubernetes. Варианты запуска есть разные, более подробно лучше смотреть в официальном guide, но в самом базовом случае всё сводится к двум шагам:
- Sudo telepresence (предполагается, что мы запускаемся в Linux-окружении по умолчанию, для других ОС команды sudo не будет. Будет аналогично, но с поправкой на запуск от имени root/администратора). Эта команда поднимет туннель на уровне сетевого интерфейса к Kubernetes кластеру и создаст deployment с именем telepresence внутри него. Посредством deployment будет вестись общение между локальным компьютером разработчика и кластером Kubernetes.
- Запуск своего экземпляра сервиса ведётся как обычно на локальном компьютере разработчика. Однако в этом случае он будет иметь доступ ко всей инфраструктуре Kubernetes кластера, будь то Service Discovery (Eureka, Consul), Api Gateway (Zuul), Kafka и её очереди, если они есть, и прочее. То есть по факту нам доступно всё нужное нам окружение кластера, но локально. Бонусом идёт возможность локальной отладки, но в окружении кластера, причём он будет уже намного быстрее, т. к. мы, по сути, находимся внутри Kubernetes (посредством туннеля), а не обращаемся к нему извне через port для remote debug.
Данное решение имеет несколько минусов:
- Telepresence отлично работает на Linux и Mac, но в Windows есть проблема с монтированием VFS, проблема известна, есть issue на GitHub. На момент написания этого материала она ещё не была исправлена. Но при условии, что вы работаете из-под Linux/Mac, в целом всё работает из коробки.
- Когда разработчик поднимает свой локальный экземпляр сервиса, он автоматически регистрируется в соответствующем Service Discovery (Eureka, Consul) со всеми вытекающими из этого обстоятельствами — балансировщик будет пытаться поочередно брать все имеющиеся у него в реестре инстансы конкретного сервиса через алгоритм Round Robin по умолчанию, когда ему будет поступать запрос на обращение к endpoint определённого вида, а это, в свою очередь, будет приводить к коллизиям:невозможность достучаться до соответствующего инстанса в направлении kubernetes -> локально запущенный сервис. Если запускать telepresence в стандартном режиме без отдельного deployment для сервиса, то в этом случае все «локальные» экземпляры будут регистрироваться в Eureka в виде ip-address:port/service-name или dns-name:port/service-name в зависимости от настроек, а т. к. доступа из Kubernetes к соответствующему узлу в режиме по умолчанию нет, то запрос будет резаться по timeout;если сервис запущен в режиме отдельного deployment и трафик может ходить туда-сюда между Kubernetes и локально запущенным сервисом, все запросы на сервис с данным именем (не только именно ваши) через определённое количество раз будут прилетать и к вам тоже (Round Robin), что слабо способствует отладке;добавление нового endpoint, допустим в рамках проверки новой feature, повлечёт за собой периодические HTTP 404 при обращении к endpoint через Gateway, так как балансировщик будет выбирать из реестра сервисов в Service Discovery ваш сервис не каждый раз, а периодически посредством Round Robin алгоритма. И так как в других версиях сервисов внутри Service Discovery вашего endpoint не будет, ожидаемо будет отдаваться HTTP 404.
По сути, мы приходим к тому, что для решения подобного рода проблем нужна динамическая маршрутизация запроса.
Динамическая маршрутизация
Под динамической маршрутизацией запроса имеется ввиду, что API Gateway (Zuul) имеет возможность выбора среди нескольких инстансов одного и того же сервиса, нужного именно нам. В общем случае эту задачу можно решить, добавив некий предикат, который позволит на этапе обработки запроса выбрать нужный сервис из общего пула сервисов с таким же именем. Естественно, каждый сервис из числа тех, с которыми мы хотим иметь возможность динамической маршрутизации, должен будет иметь в себе некую метаинформацию, содержащую данные, по которым будет определяться, нужный это сервис или нет. Spring Cloud (в случае с Eureka), например, позволяет сделать это, указав в специальном блоке метаданных в application.yml:
После регистрации такого сервиса в Service Discovery в его com.netflix.appinfo.InstanceInfo#getMetadata будет лежать метка с ключом service.label и значением develop, которую можно получить в runtime. Важным моментом на этапе старта сервиса является проверка — существует ли в Service Discovery инстанс сервиса с такой метаинформацией или нет, чтобы избежать потенциальных коллизий.
Возможные варианты маршрутизации
После этого решение задачи может быть сведено к двум вариантам:
- API Gateway с поддержкой динамической маршрутизации запроса на нужный сервис. Клиент в этом случае должен будет посылать некий признак, определяющий, что данный запрос должен быть маршрутизирован на нужный нам сервис, допустим, в Headers: DestionationService: feature/PRJ-001. Минус данного подхода в том, что на стороне клиента должна быть логика, которая при попытке обращения к нужному сервису должна проставлять соответствующий Header для возможности выбора нужного сервиса из имеющегося пула. К плюсам данного подхода можно отнести то, что в данном случае точка входа будет одна — один-единственный API Gateway.
- Поднятие группы API Gateway, каждый из которых будет отвечать за определённый маршрут, т. е., например, на картинке внизу запрос, который будет идти через Zuul 1 при попытке запроса endpoint-а вида /api/users/… всегда будет отправлен на инстанс сервиса user, у которого в метадате лежит feature/PRJ-001, а запрос через Zuul 2 при попытке запроса endpoint-а вида /api/users/… всегда будет отправлен на инстанс сервиса user, у которого в метадате лежит feature/PRJ-002. К плюсам данного подхода стоит отнести то, что в данном случае можно иметь связку из N API Gateway и N сервисов, т. е. можно распараллелить работу нескольких бэкенд и фронтенд разработчиков, т. к. как каждая feature — это, по сути, отдельная связка, существующая изолированно друг от друга и не вносящая коллизий для других участников команды, в отличие от случая, когда приходится ждать своей очереди, заливая изменения в контур поочередно друг за другом. К минусам такого подхода можно отнести лишь большое количество API Gateway, но, т. к., по сути, он довольно легковесный, и основная его задача — это просто маршрутизация, то такой подход вполне жизнеспособен.
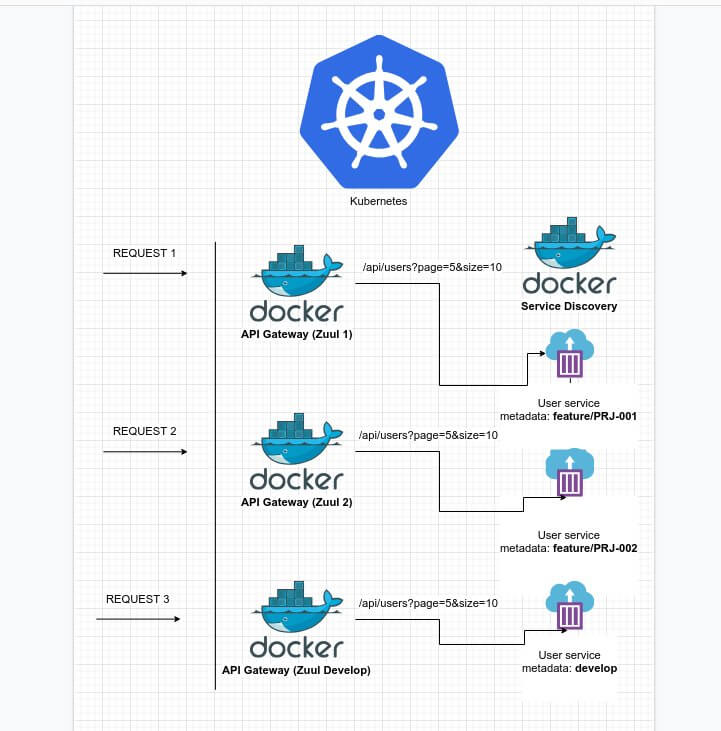
Схема диспетчеризации запроса
Советы по настройке окружения в свете динамической маршрутизации
В рамках API Gateway также стоит предусмотреть механизм, который позволит иметь возможность менять в runtime правила маршрутизации. Лучше всего вынести эти настройки в config-map. В этом случае будет достаточно перепрописать новые маршруты и либо сделать рестарт API Gateway в Kubernetes для обновления маршрутизации, либо воспользоваться Spring Boot Actuator (при условии, что есть соответствующая зависимость в API Gateway) — вызвать endpoint /refresh, который, по сути, заново перечитает данные из config-map и обновит маршруты.
Важным моментом является также то, что должен быть, условно говоря, эталонный экземпляр сервиса (допустим, с меткой develop, который будет собираться из основной ветки разработки сервиса) и отдельный основной API Gateway, у которого всегда в настройках будет прописано, что он будет обращаться к этому сервису. По сути, этим мы обеспечиваем себе независимое staging окружение, которое всегда будет работоспособным в рамках динамической маршрутизации.
Пример блока config-map для API Gateway, содержащего настройки для маршрутизации (тут это приведено лишь как пример того, как это может выглядеть, для корректной работы требуется соответствующая обвязка в виде кода на стороне backend части сервиса API Gateway):
rules.meta — это карта, содержащая правила маршрутизации для сервисов.
user/client/notification — имя сервиса, под которым он регистрируется в Eureka.
develop/feature/PRJ-010 — service label из application.yml соответствующего сервиса, на основе которого нужный сервис будет выбираться среди всех имеющихся сервисов с таким же именем из Service Discovery, если экземпляров такого сервиса больше одного.
Заключение
Как и все в этом мире, инструменты и решения в IT не идеальны. Не стоит думать, что, если вы смените архитектуру, все проблемы закончатся разом. Только детальное погружение в используемые технологии и собственный опыт дадут вам реальную картину происходящего. Надеюсь, этот материал поможет вам решить вашу задачу. Интересных вам задач и прода без багов!

19К открытий19К показов

Как развернуть сайт на Spring Boot и Angular с SSR, Docker и Nginx: пошаговый опыт настройки, устранения ошибок, подключения HTTPS и защиты от ботов.

Что приходит на смену классическим техлидам и продакт-менеджерам в IT: рассказываем, зачем нужны Technical Owner и Unit-лид, какие проблемы они решают в реальной разработке и как меняются роли в командах.

Даже самая идеальная микросервисная архитектура может упасть. В статье обсудим зарубежный материал, где автор рассказывает о проблеме Context Collapse.

Свежая статистика, исследования и советы экспертов: как российским IT-специалистам найти работу за границей в 2025 году.