Google рассказала о собственных чипах для машинного обучения

Не секрет, что Google разработала собственные чипы для ускорения алгоритмов машинного обучения. Компания впервые показала их на своей конференции разработчиков I/O еще в мае 2016 года, но не сообщила подробностей, за исключением информации об оптимизации для фреймворка TensorFlow. Эти чипы называются Tensor Processing Units (TPU). Вчера компания поделилась более подробными сведениями о проекте и бенчмарками.
Что принципиально нового?
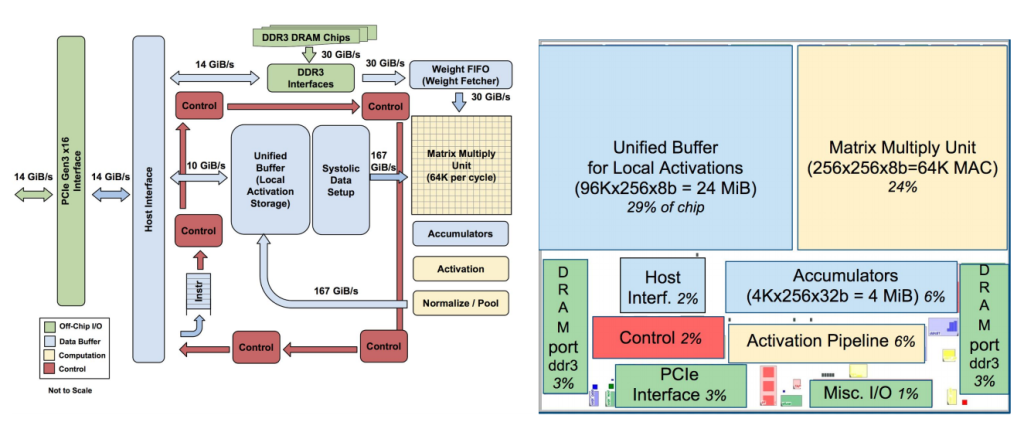
Если вы разработчик чипов, то вам могут быть интересны подробности о том, как устроен TPU. Однако наиболее важными здесь являются результаты тестов Google. TPU в среднем в 15–30 раз быстрее, чем стандартное сочетание GPU / CPU (а компания используется процессоры Intel Haswell и графические процессоры Nvidia K80).

Стоит отметить, что эти цифры касаются использования моделей машинного обучения в производстве.
Google также отмечает, что большинство архитекторов оптимизируют свои микросхемы для сверточных нейронных сетей (специальный тип нейронной сети, который хорошо работает, например, для распознавания изображений). Однако компания утверждает, что на эти сети приходится лишь около 5% рабочей нагрузки её центра обработки данных, тогда как в большинстве приложений используются многослойные перцептроны.
Чтобы лучше разобраться в этом многообразии нейронных сетей, вам стоит прочитать наши шпаргалки, посвящённые простым и более сложным сетям.

974 открытий974 показов

Илон Маск написал в своём Твиттере, что основал компанию xAI, которая будет работать над искусственным интеллектом, чтобы понять реальность.
Разобрались, кто такой Джефф Нельсон, как он придумал и создал Chrome OS и почему он всё-таки остался неизвестным разработчиком.
Telegram ввёл таргетированную рекламу для Восточной Европы. Теперь рекламу можно будет настраивать по IP-адресам и номерам телефонов.

Составили подборку новостей из мира IT. Рассказываем о запрете статьей о VPN, об огранениях Open Source в РФ и о борьбе Google с торрентами.