В статье собраны технические и поведенческие вопросы, которые задают на собеседовании в Apple. Ответы на технические вопросы даны на C++.
16К открытий17К показов
Собеседование в Apple — непростая задача. В этой статье вы найдёте вопросы, которые чаще всего задают соискателям, и советы по прохождению собеседования.
Содержание:
Как проходит собеседование в AppleМассивы и графыСвязные спискиДеревьяСтрокиДинамическое программированиеМатематика, статистика и поиск с возвратомПоиск и проектированиеПоведенческие вопросыСоветы по прохождению собеседования
Как проходит собеседование в Apple
Взаимодействие с компанией обычно состоит из следующих шагов:
Предварительный разговор с рекрутером: в среднем ответ на резюме занимает около недели. Обычно с вами связываются по email или LinkedIn, чтобы договориться о телефонном звонке. Звонок длится от 15 минут до получаса. На этом этапе не будет серьёзных технических вопросов. Вас могут спросить о том, почему вы хотите работать в этой компании или какой ваш любимый продукт Apple.
Техническое собеседование по телефону: обычно назначается через неделю. Таких собеседований может быть одно или два. В течение часа вам будут задавать вопросы о вашем резюме, алгоритмах и структурах данных. Из них полчаса будет отведено на выполнение заданий.
Собеседование в офисе: такое собеседование длится примерно шесть часов. С вами пообщаются около десяти сотрудников компании. В процессе собеседования с вами обсудят ваши знания, зададут поведенческие вопросы и дадут задания с кодом. Каждое интервью длится около часа. Поведенческие вопросы особенно важны если вы собеседуетесь на роль менеджера.
Структуры данных, которые нужно знать: массивы, связные списки, стеки, очереди, деревья, графы, кучи, hash set и hash map.
Алгоритмы, которые нужно знать: поиск в глубину, поиск в ширину, бинарный поиск, быстрая сортировка, сортировка слиянием, динамическое программирование, парадигма «Разделяй и властвуй».
Формулировка: Дан массив целых чисел и значение, определите, есть ли в этом массиве три числа, сумма которых равна этому значению.
Решение
bool find_sum_of_two(vector& A, int val,
size_t start_index) {
for (int i = start_index, j = A.size() - 1; i < j;) {
int sum = A[i] + A[j];
if (sum == val) {
return true;
}
if (sum < val) {
++i;
} else {
--j;
}
}
return false;
}
bool find_sum_of_three_v3(vector arr,
int required_sum) {
std::sort(arr.begin(), arr.end());
for (int i = 0; i < arr.size() - 2; ++i) {
int remaining_sum = required_sum - arr[i];
if (find_sum_of_two(arr, remaining_sum, i + 1)) {
return true;
}
}
return false;
}
int main(){
vector arr = {-25, -10, -7, -3, 2, 4, 8, 10};
cout<<"-8: " <<find_sum_of_three_v3(arr, -8)<<endl;
cout<<"-25: "<<find_sum_of_three_v3(arr, -25)<<endl;
cout<<"0: " <<find_sum_of_three_v3(arr, 0)<<endl;
cout<<"-42: " <<find_sum_of_three_v3(arr, -42)<<endl;
cout<<"22: " <<find_sum_of_three_v3(arr, 22)<<endl;
cout<<"-7: " <<find_sum_of_three_v3(arr, -7)<<endl;
cout<<"-3: " <<find_sum_of_three_v3(arr, -3)<<endl;
cout<<"2: " <<find_sum_of_three_v3(arr, 2)<<endl;
cout<<"4: " <<find_sum_of_three_v3(arr, 4)<<endl;
cout<<"8: " <<find_sum_of_three_v3(arr, 8)<<endl;
cout<<"7: " <<find_sum_of_three_v3(arr, 7)<<endl;
cout<<"1: " <<find_sum_of_three_v3(arr, 1)<<endl;
return 0;
}
В этом коде мы сортируем массив. Затем фиксируем один элемент e и находим пару — (a, b), среди оставшихся элементов массива, такую что required_sum - e = a + b.
Мы начинаем с первого элемента массива — e, и пытаемся найти такую пару значений (a, b) в оставшемся массиве (например от A[i + 1] до A[n – 1]), которая удовлетворяет условию a+b = required_sum – e. Если мы её нашли, то выходим из цикла.
В противном случае мы повторяем описанные шаги для всех элементов с индексами от 1 до n – 3 до тех пор, пока не найдём соответствующую пару.
Вычислительная сложность: квадратичная, O(n²).
Эффективность алгоритма: константная, O(1).
Объединение пересекающихся интервалов
Цель этого задания – объединить все пересекающиеся интервалы в списке, чтобы получить список, в котором останутся только непересекающиеся интервалы.
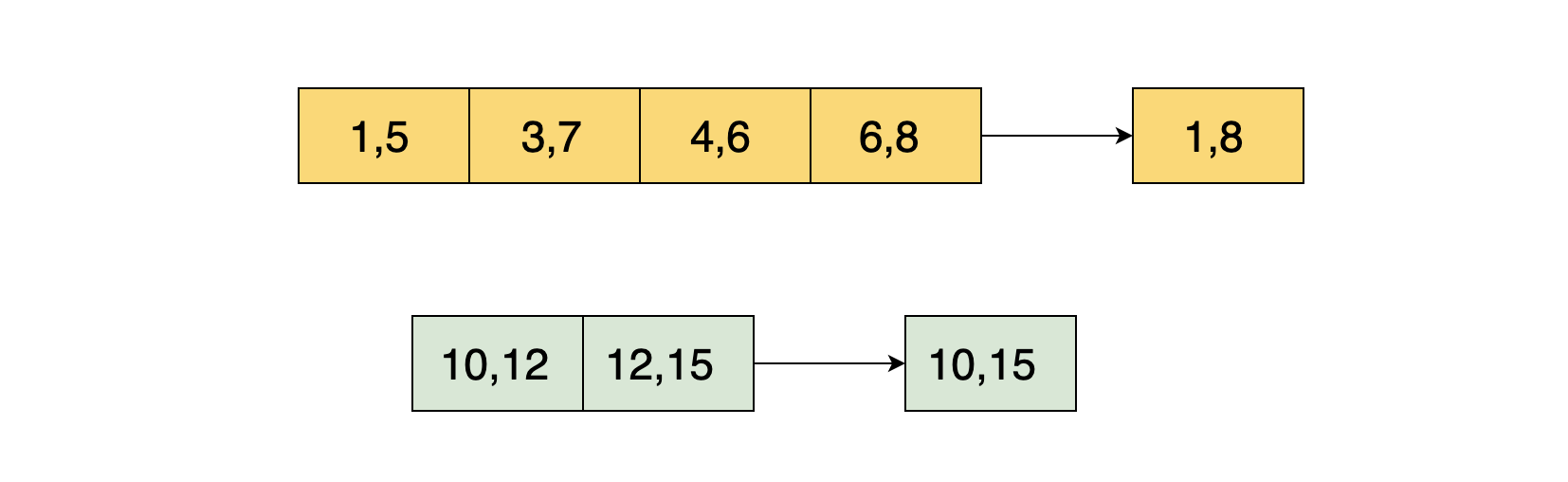
Формулировка: Дан массив (список) пар интервалов, где каждый интервал это timestamp, отсортированный по первому значению. Объедините пересекающиеся интервалы и верните полученный массив.
В данном примере интервалы: (1, 5), (3, 7), (4, 6),( 6, 8) пересекаются и должны быть объединены в интервал (1, 8). Интервалы (10, 12) и (12, 15) должны быть объединены в (10, 15).
Решение
class Pair{
public:
int first, second;
Pair(int x, int y){
first = x;
second = y;
}
};
vector merge_intervals(vector& v) {
if(v.size() == 0) {
return v;
}
vector result;
result.push_back(Pair(v[0].first, v[0].second));
for(int i = 1 ; i < v.size(); i++){
int x1 = v[i].first;
int y1 = v[i].second;
int x2 = result[result.size() - 1].first;
int y2 = result[result.size() - 1].second;
if(y2 >= x1){
result[result.size() - 1].second = max(y1, y2);
}
else{
result.push_back(Pair(x1, y1));
}
}
return result;
}
int main() {
vector v {
Pair(1, 5),
Pair(3, 7),
Pair(4, 6),
Pair(6, 8),
Pair(10, 12),
Pair(11, 15)
};
vector result = merge_intervals(v);
for(int i = 0; i < result.size(); i++){
cout << "[" << result[i].first << ", " << result[i].second << "] ";
}
}
Эту задачу можно решить с помощью алгоритма linear scan.
Для каждого интервала из списка:
Если интервал из входного списка пересекается с последним интервалом из результирующего списка, то они объединяются, и результат заменяет последний интервал в результирующем списке.
В противном случае, интервал из входного списка добавляется в итоговый список.
Сложность: линейная, O(n).
Эффективность: линейная, O(n).
Клонировать ориентированный граф
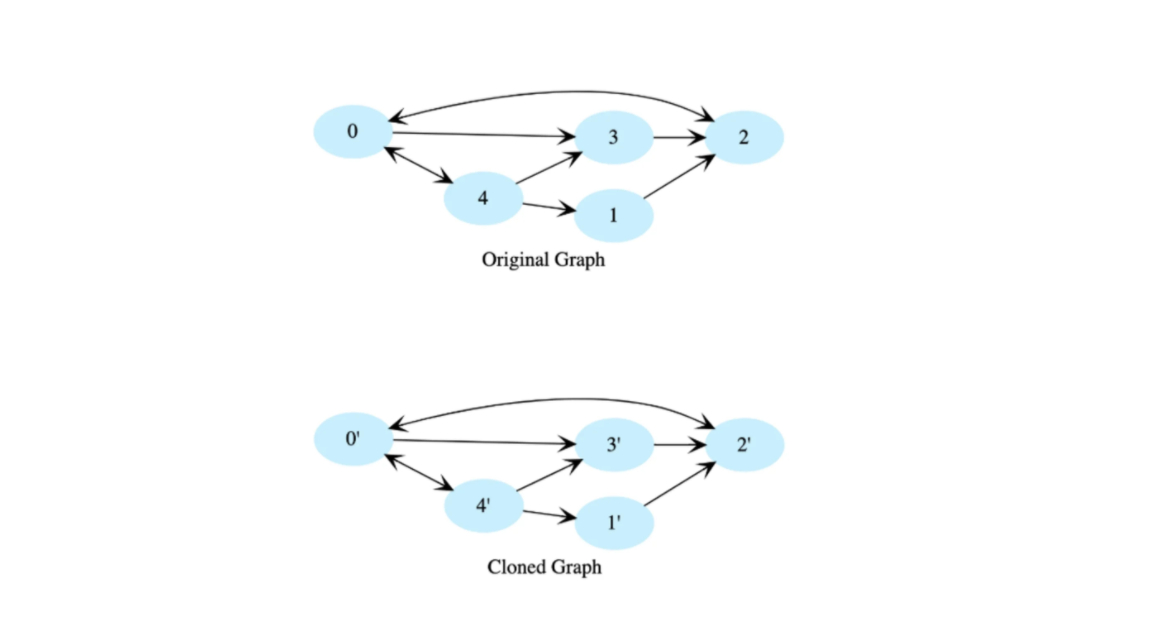
Формулировка: Есть корневой узел ориентированного графа, нужно клонировать граф с помощью глубокого копирования. Клонированный граф должен иметь такие же ребра и узлы.
Решение
struct Node {
int data;
list<Node*> neighbors;
Node(int d) : data(d) {}
};
Node* clone_rec(Node* root,
unordered_map<Node*,
Node*>& nodes_completed) {
if (root == nullptr) {
return nullptr;
}
Node* pNew = new Node(root->data);
nodes_completed[root] = pNew;
for (Node* p : root->neighbors) {
auto x = nodes_completed.find(p);
if (x == nodes_completed.end()){
pNew->neighbors.push_back(clone_rec(p, nodes_completed));
} else {
pNew->neighbors.push_back(x->second /*value*/);
}
}
return pNew;
}
Node* clone(Node* root) {
unordered_map<Node*, Node*> nodes_completed;
return clone_rec(root, nodes_completed);
}
// это неориентированный граф, то есть
// если есть ребро от x к y
// то должно быть ребро от y к x
// и не должно быть ребра от узла к нему самому
// тогда максимально может быть (nodes * nodes - nodes) / 2 рёбер в этом графе
void create_test_graph_undirected(int nodes, int edges, vector<Node*>& vertices) {
for (int i = 0; i < nodes; ++i) {
vertices.push_back(new Node(i));
}
vector<pair<int, int>> all_edges;
for (int i = 0; i < vertices.size(); ++i) {
for (int j = i + 1; j < vertices.size(); ++j) {
all_edges.push_back(pair<int, int>(i, j));
}
}
std::random_shuffle(all_edges.begin(), all_edges.end());
for (int i = 0; i < edges && i < all_edges.size(); ++i) {
pair<int, int>& edge = all_edges[i];
vertices[edge.first]->neighbors.push_back(vertices[edge.second]);
vertices[edge.second]->neighbors.push_back(vertices[edge.first]);
}
}
void print_graph(vector<Node*>& vertices) {
for (Node* n : vertices) {
cout << n->data << ": {";
for (Node* t : n->neighbors) {
cout << t->data << " ";
}
cout << "}" << endl;
}
}
void print_graph(Node* root, unordered_set<Node*>& visited_nodes) {
if (root == nullptr || visited_nodes.find(root) != visited_nodes.end()) {
return;
}
visited_nodes.insert(root);
cout << root->data << ": {";
for (Node* n : root->neighbors) {
cout << n->data << " ";
}
cout << "}" << endl;
for (Node* n : root->neighbors) {
print_graph(n, visited_nodes);
}
}
void print_graph(Node* root) {
unordered_set<Node*> visited_nodes;
print_graph(root, visited_nodes);
}
int main() {
vector<Node*> vertices;
create_test_graph_undirected(7, 18, vertices);
print_graph(vertices[0]);
Node* cp = clone(vertices[0]);
cout << endl << "After copy" << endl;
print_graph(cp);
return 0;
Мы используем обход в глубину и создаем копию каждого узла в процессе обхода графа. В хэш-таблице сохраняем каждый скопированный узел, чтобы не скопировать его дважды. Ключ в хэш-таблице – это узел в оригинальном графе и его значение, соответствующее значению в скопированном графе.
Сложность: линейная, O(n).
Эффективность: логарифмическая, O(n), где n — это количество вершин графа.
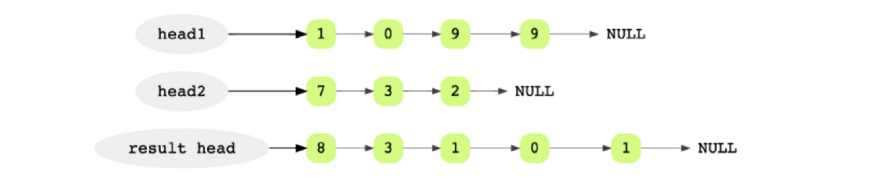
Формулировка: Даны указатели на головы двух связных списков, где каждый список это целое число (каждый узел это цифра). Сложите их и верните результат.
Решение
// оба целых числа хранятся в связных списках
// например 415 хранится в виде 5->1->4
// 32 хранится в виде 2->3
LinkedListNode* add_integers(
LinkedListNode* integer1,
LinkedListNode* integer2) {
LinkedListNode* result = nullptr;
LinkedListNode* last = nullptr;
int carry = 0;
while (
integer1 != nullptr ||
integer2 != nullptr ||
carry > 0) {
int first =
(integer1 == nullptr ? 0 : integer1->data);
int second =
(integer2 == nullptr ? 0 : integer2->data);
int sum = first + second + carry;
LinkedListNode* pNew =
new LinkedListNode(sum % 10);
carry = sum / 10;
if (result == nullptr) {
result = pNew;
} else {
last->next = pNew;
}
last = pNew;
if (integer1 != nullptr) {
integer1 = integer1->next;
}
if (integer2 != nullptr) {
integer2 = integer2->next;
}
}
return result;
}
int main(int argc, char* argv[]) {
vector v1 = {1, 2, 3}; // 321
vector v2 = {1, 2}; // 21
LinkedListNode* first = LinkedList::create_linked_list(v1);
LinkedListNode* second = LinkedList::create_linked_list(v2);
// sum should be 321 + 21 = 342 => 2->4->3
LinkedListNode* result = add_integers(first, second);
vector r = {2, 4, 3}; // 342
LinkedListNode* expected = LinkedList::create_linked_list(r);
assert(LinkedList::is_equal(result, expected));
cout << endl << "First:";
LinkedList::display(first);
cout << endl << "Second:";
LinkedList::display(second);
cout << endl << "Result:";
LinkedList::display(result);
result = add_integers(first, nullptr);
assert(LinkedList::is_equal(result, first));
result = add_integers(nullptr, second);
assert(LinkedList::is_equal(result, second));
}
Допустим, что мы хотим сложить 9901 и 237. В результате должно получиться 10138.
Для облегчения задачи числа хранятся в инвертированных связных списках. Самая значимая цифра числа это последний элемент списка. Мы начинаем сложение с голов списков.
На каждой итерации мы складываем текущие числа и добавляем результат в хвост итогового списка. Для каждого шага нужно учитывать переполнение.
Нам нужно сделать это для каждого узла обоих списков. Если один из них кончится раньше, мы продолжаем действия для оставшегося. Когда списки закончатся, и не будет чисел, которые переносятся, алгоритм заканчивается.
Сложность: линейная, O(n).
Эффективность: линейная, O(n).
Слияние двух отсортированных связных списков
Формулировка: Даны два отсортированных связных списка, объедините их так, чтобы итоговый список остался отсортированным.
Указатели на голову и хвост итогового списка сохраняются. Его голова будет результатом сравнения первых узлов объединяемых списков.
Для всех последующих узлов, выбираем наименьший текущий и добавляем его в хвост итогового списка. Затем сдвигаем текущий указатель этого списка на шаг в перед.
Если один из списков кончился, то оставшиеся элементы другого добавляются в хвост итогового списка. Изначально итоговый список — Null.
Сравниваем значения первых двух узлов и создаём узел с меньшим значением в голове итогового списка. В примере это 4 в head1. Пока в списке только один узел, то он будет также и хвостом. Затем сдвигаем голову head1 на один шаг вперёд.
Сложность: линейная, O(m+n), где m и n — это длины первоначальных списков.
Эффективность: константная, O(1).
Деревья
Проверить два бинарных дерева на идентичность
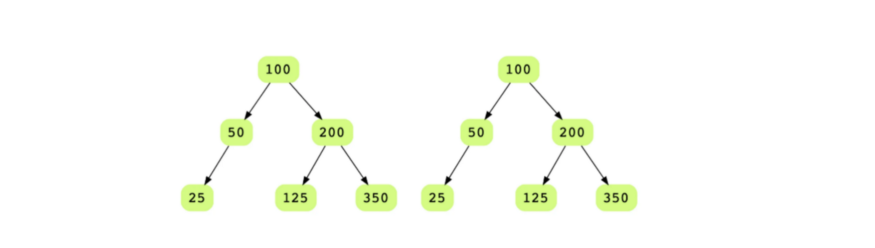
Формулировка: Даны два бинарных дерева. Нужно проверить их на идентичность, то есть у них должны быть одинаковые структуры и данные в каждом узле.
Эта задача решается с помощью рекурсии. Рекурсия останавливается, если хотя бы один из сравниваемых узлов равен null.
Деревья A и B идентичны если:
Данные в корневых узлах этих деревьев идентичны или равны null.
Левое поддерево A идентично левому поддереву B.
Правое поддерево A идентично правому поддереву B.
Это проблема решается с помощью одновременного глубокого обхода и сравнения данных на каждом уровне.
Сложность: линейная, O(n).
Эффективность: O(h) для лучшего случая, или O(logn) для сбалансированного дерева, или O(n) для худшего случая.
Отзеркаливание узлов бинарного дерева
Формулировка: Дано бинарное дерево. Нужно поменять местами левых и правых потомков каждого узла.
Решение
void mirror_tree(BinaryTreeNode* root) {
if (root == nullptr) {
return;
}
// Делаем обратный обход бинарного дерева.
if (root->left != nullptr) {
mirror_tree(root->left);
}
if (root->right != nullptr) {
mirror_tree(root->right);
}
// Меняем местами левый и правый узел.
BinaryTreeNode* temp = root->left;
root->left = root->right;
root->right = temp;
}
int main(int argc, char* argv[]) {
BinaryTreeNode* root = create_random_BST(15);
display_level_order(root);
mirror_tree(root);
cout << endl << "Отзеркаленное дерево = " << endl;
display_level_order(root);
}
Мы используем обратный обход бинарного дерева. Меняем местами левого и правого потомка каждого узла. Используем обход в глубину — перед возвращением из узла все его потомки пройдены и отзеркалены.
Сложность: линейная, O(n).
Эффективность: линейная, в худшем случае O(n).
Строки
Найти все палиндромы в строке
Формулировка: Дана строка, найдите все возможные подстроки палиндромы длиной больше одного символа. Строка — «aabbbaa».
Решение
int find_palindromes_in_sub_string(const string& input, int j, int k) {
int count = 0;
for (; j >= 0 && k < input.length(); --j, ++k) {
if (input[j] != input[k]) {
break;
}
cout << input.substr(j, k - j + 1) << endl;
++count;
}
return count;
}
int find_all_palindrome_substrings(const string& input) {
int count = 0;
for (int i = 0; i < input.length(); ++i) {
count += find_palindromes_in_sub_string(input, i - 1, i + 1);
count += find_palindromes_in_sub_string(input, i, i + 1);
}
return count;
}
int main() {
string str = "aabbbaa";
cout << "Total palindrome substrings: " << find_all_palindrome_substrings(str) << endl;
}
От каждой буквы из входной строки начинаем расширятся влево и вправо, проверяя на палиндромы подстроки чётной и нечетной длины. Затем, если палиндрома нет, переходим на следующую букву.
Сложность: квадратичная, O(n²).
Эффективность: константная, O(1).
Смена порядка слов в предложении
Формулировка: Обратите порядок слов в предложении (хранящемся в массиве символов). Строка — «Hello world!».
Решение
void str_rev(char * str, int len) {
if (str == nullptr || len < 2) {
return;
}
char * start = str;
char * end = str + len - 1;
while (start < end) {
if (start != nullptr && end != nullptr) {
char temp = * start;
* start = * end;
* end = temp;
}
start++;
end--;
}
}
void reverse_words(char * sentence) {
// sentence это C-строка заканчивающаяся символом '\0'.
if (sentence == nullptr) {
return;
}
// Сначала мы переворачиваем всю строку
// Теперь всё слова на нужных местах, но их буквы в обратном порядке
// "Hello World" -> "dlroW olleH".
int len = strlen(sentence);
str_rev(sentence, len);
// Теперь переворачиваем каждое слово.
// "dlroW olleH" -> "World Hello"
char * start = sentence;
char * end;
while (true) {
// находим начало слова.
while (start && * start == ' ') {
++start;
}
if (start == nullptr || * start == '\0') {
break;
}
// находим конец слова.
end = start + 1;
while (end && * end != '\0' && * end != ' ') {
++end;
}
// переворачиваем слово.
if (end != nullptr) {
str_rev(start, (end - start));
}
start = end;
}
}
int main() {
string str = "Hello World!";
char* a = const_cast<char*>(str.c_str());
cout << a << endl;
reverse_words(a);
cout << a << endl;
}
Решение состоит из двух этапов: переворот строки и обход строки и переворот каждого слова.
Сложность: линейная, O(n).
Эффективность: константная, O(1).
Динамическое программирование
Поиск подотрезка массива с максимальной суммой элементов
Формулировка: Найдите подотрезок в массиве, используя динамическое программирование и алгоритм Кадане. В приведённом ниже массиве такой отрезок имеет индексы (3, 6).
Решение
int find_max_sum_sub_array(int A[], int n) {
if (n < 1) {
return 0;
}
int curr_max = A[0];
int global_max = A[0];
for (int i = 1; i < n; ++i) {
if (curr_max < 0) {
curr_max = A[i];
} else {
curr_max += A[i];
}
if (global_max < curr_max) {
global_max = curr_max;
}
}
return global_max;
}
int main() {
int v[] = {-4, 2, -5, 1, 2, 3, 6, -5, 1};
cout << "Наибольшая сумма подотрезка: " << find_max_sum_sub_array(v, sizeof(v) / sizeof(v[0])) << endl;
return 0;
}
Мы используем для решения алгоритм Кадане. Идея алгоритма в том, чтобы просканировать весь массив и для каждой позиции найти наибольшую сумму для отрезка массива, который кончается в этой позиции. Это достигается сохранением текущей максимальной суммы (current_max) для текущего индекса и global_max (максимальной для всего массива).
Код алгоритма:
Решение
current_max = A[0]
global_max = A[0]
for i = 1 -> size of A
if current_max is less than 0
then current_max = A[i]
otherwise
current_max = current_max + A[i]
if global_max is less than current_max
then global_max = current_max
Сложность: линейная, O(n).
Эффективность: константная, O(1).
Математика и статистика
Возведение числа в степень
Формулировка: Даны два числа, x (double) и y (integer), напишите функцию, которая возводит x в степень y.
Решение
double power_rec(double x, int n) {
if (n == 0) return 1;
if (n == 1) return x;
double temp = power_rec(x, n/2);
if (n % 2 == 0) {
return temp * temp;
} else {
return x * temp * temp;
}
}
double power(double x, int n) {
bool is_negative = false;
if (n < 0) {
is_negative = true;
n *= -1;
}
double result = power_rec(x, n);
if (is_negative) {
return 1 / result;
}
return result;
}
bool test_power(double x, int n) {
double r1 = power(0.753, n);
double r2 = pow(0.753, n);
double diff = r1 - r2;
if (diff < 0) {
diff = diff * -1;
}
if (diff > 0.00000000001) {
cout << "Failed for " << x << ", " << n << endl;
return false;
}
return true;
}
int main(int argc, char* argv[]) {
bool pass = true;
for (int n = -5; n <= 5; ++n) {
bool temp_pass = test_power(0.753, n);
pass &= temp_pass;
}
pass &= test_power(0, 0);
cout << "Power(0, 0) = " << pow(0, 0) << endl;
if (pass) {
cout << "Passed." << endl;
} else {
cout << "Failed." << endl;
}
}
Для наиболее эффективного решения этой задачи мы используем алгоритм «Разделяй и властвуй». На стадии разделения мы рекурсивно делим n на 2 пока не достигнем условия выхода.
На стадии объединения мы получаем результат подпроблемы r и вычисляем результат текущей проблемы, используя следующие правила:
Если n — чётное, результат — r * r (где r — это результат подпроблемы)
Если n — нечётное, результат — x * r * r (где r — это результат подпроблемы)
Сложность: логарифмическая, O(logn).
Эффективность: логарифмическая, O(logn).
Найти комбинации чисел дающие указанную сумму
Формулировка: Дано положительное целое число target, выведите все возможные комбинации положительных целых чисел, сумма которых равна target.
Вывод должен быть либо в форме массива массивов, либо списка списков, где каждый элемент это одна комбинация. Вот пример для числа 5:
void print(vector<vector> output){
for(int i = 0; i < output.size(); i++){
cout << "[ ";
for(int j = 0; j < output[i].size(); j++){
cout << output[i][j] << ", ";
}
cout << "]" << endl;
}
}
void print_all_sum_rec(
int target,
int current_sum,
int start, vector<vector>& output,
vector& result) {
if (target == current_sum) {
output.push_back(result);
}
for (int i = start; i < target; ++i) {
int temp_sum = current_sum + i;
if (temp_sum <= target) {
result.push_back(i);
print_all_sum_rec(target, temp_sum, i, output, result);
result.pop_back();
} else {
return;
}
}
}
vector<vector> print_all_sum(int target) {
vector<vector> output;
vector result;
print_all_sum_rec(target, 0, 1, output, result);
return output;
}
int main(int argc, const char* argv[]) {
int n = 4;
vector<vector> result = print_all_sum(n);
print (result);
}
Мы рекурсивно перебираем все возможные комбинации сумм и печатаем подходящую комбинацию.
Каждый вызов рекурсии содержит цикл, который работает от start до target (start изначально равен 1). current_sum это переменная, которая увеличивается с каждым вызовом рекурсии.
Каждый раз, когда значение добавляется в current_sum, оно также добавляется в список result. Когда current_m = target мы знаем, что список result содержит комбинацию, которая добавляется в финальный список output. Вот пример:
//Условие выхода из рекурсии:
if current_sum == target {
print(output)
}
Перед каждым рекурсивным вызовом в result добавляется элемент. После вызова этот элемент удаляется, для очистки списка. Сложность: экспоненциальная, O². Эффективность: линейная, O(n).
Поиск и проектирование
Поиск в циклически сдвинутом массиве
Формулировка: Нужно найти конкретное число в отсортированном массиве (с уникальными элементами), который был циклически сдвинут на некоторое число, учитывая, что массив не содержит дубликатов. Верните -1 если такого числа не найдено.
Вот массив до сдвига:
Вот массив поле сдвига на 6 позиций:
Решение
int binary_search(vector& arr, int start, int end, int key) {
// предполагается что все ключи уникальны.
if (start > end) {
return -1;
}
int mid = start + (end - start) / 2;
if (arr[mid] == key) {
return mid;
}
if (arr[start] <= arr[mid] && key <= arr[mid] && key >= arr[start]) {
return binary_search(arr, start, mid-1, key);
}
else if (arr[mid] <= arr[end] && key >= arr[mid] && key <= arr[end]) {
return binary_search(arr, mid+1, end, key);
}
else if (arr[end] <= arr[mid]) {
return binary_search(arr, mid+1, end, key);
}
else if (arr[start] >= arr[mid]) {
return binary_search(arr, start, mid-1, key);
}
return -1;
}
int binary_search_rotated(vector& arr, int key) {
return binary_search(arr, 0, arr.size()-1, key);
}
int main(int argc, char* argv[]) {
vector v1 = {6, 7, 1, 2, 3, 4, 5};
cout<<"Key(3) found at: "<<binary_search_rotated(v1, 3)<<endl;
cout<<"Key(6) found at: "<<binary_search_rotated(v1, 6)<<endl;
vector v2 = {4, 5, 6, 1, 2, 3};
cout<<"Key(3) found at: "<<binary_search_rotated(v2, 3)<<endl;
cout<<"Key(6) found at: "<<binary_search_rotated(v2, 6)<<endl;
}
Для решения мы использовали немного модифицированный бинарный поиск. Отметим, что как минимум одна половина массива всегда отсортирована. Если число n находится в этой половине, тогда проблема решается бинарным поиском.
Сложность: логарифмическая, O(logn).
Эффективность: логарифмическая, O(logn).
Реализовать LRU-кэш
Формулировка: Алгоритм LRU заключается в том, что для добавления новых элементов из кэша удаляются элементы, которые дольше всего не использовались.
Для примера возьмём кэш, в который помещаются 4 элемента. В нем находятся 4 элемента.
Теперь мы добавим туда элемент — 5.
Решение
// Linked list operations
// void add_at_tail(int val)
// void delete_node(ListNode* node)
// void delete_from_head()
// void delete_from_tail()
// ListNode* get_head()
// void set_head(ListNode* node)
// ListNode* get_tail()
// void set_tail(ListNode* node)
// простой однопоточный LRUCache
class LRUCache {
unordered_set cache;
// each entry in linked list is the value of the element
LinkedList cache_vals;
int capacity; // total capacity
public:
LRUCache(int capacity) {
this->capacity = capacity;
}
~LRUCache() {
cache.clear();
}
ListNode* get(int val) {
auto p = cache.find(val);
if (p == cache.end()) {
return nullptr;
}
else{
ListNode* i = cache_vals.get_head();
while(i != nullptr){
if (i->value == val){
return i;
}
i = i->next;
}
}
}
void set(int value) {
ListNode* check = get(value);
if(check == nullptr){
if(cache.size() >= capacity){
cache_vals.add_at_tail(value);
int head_val = cache_vals.get_head()->value;
cache.erase(head_val);
cache_vals.delete_from_head();
}
else{
cache_vals.add_at_tail(value);
cache.insert(value);
}
}
else{
if(check == cache_vals.get_tail()){
return;
}
if(check == cache_vals.get_head()){
cache_vals.add_at_tail(check->value);
cache_vals.delete_from_head();
return;
}
if(check->prev != nullptr){
check->prev->next = check->next;
}
if(check->next != nullptr){
check->next->prev = check->prev;
}
cache_vals.add_at_tail(check->value);
delete check;
}
}
void print() {
ListNode* i = cache_vals.get_head();
while(i != nullptr){
cout << i->value << ", ";
i = i ->next;
}
cout << endl;
}
};
int main(int argc, char const *argv[])
{
LRUCache cache(4);
cache.set(1);
cache.print();
cache.set(2);
cache.print();
cache.set(3);
cache.print();
cache.set(4);
cache.print();
cache.set(5);
cache.print();
cache.set(2);
cache.print();
return 0;
}
Кэширование — это техника хранения данных в более быстром хранилище (обычно в оперативной памяти), для того чтобы иметь к ним быстрый доступ. Обычно кэш ограничен в объёме. Поэтому при заполнении кэша нужно удалять из него данные.
LRU — очень простой и популярный алгоритм для этого. Мы удаляем самые старые данные, чтобы освободить место для новых.
Чтобы реализовать LRU кэш, нам понадобятся две структуры данных: хэш-таблица и двусвязный список. Двусвязный список помогает поддерживать порядок удаления из кеша, а хэш-таблица используется для поиска кэшированных элементов.
Вот описание алгоритма:
Если элемент существует в хэш-таблице
передвинуть его в хвост связного списка
Иначе
если кэш заполнился
удалить головной элемент из списка и запись о нём в хэш-таблице
Добавить новый элемент в хвост списка и в таблицу.
Получить элемент из кэша и вернуть
Замечание: Элемент, находящийся в конце списка — последний использовавшийся. Новые элементы также добавляются в конец списка.
Сложность:
get (hashset): константная,O(1).
set (hashset): константная,O(1).
Удаление головы при добавлении нового элемента: константная,O(1).
Поиск для удаления и добавления в хвост: линейная,O(n).
Эффективность: линейная, O(n), где n — размер кэша.
Поведенческие вопросы на собеседовании в Apple
Расскажите про ваш самый лучший и самый худший день, за последние 4 года.
Расскажите про ваш любимый продукт или сервис Apple. Объясните почему.
Опишите достижение, которым вы особенно гордитесь.
Были ли у вас разногласия с менеджерами по рабочим вопросами. Опишите ситуацию и то, как вы разрешили конфликт.
Как вы преодолевали неудачу? Что вы из этого вынесли?
Почему вы хотите работать в Apple?
Что первое вы замечаете, когда заходите в Apple Store?
Опишите самую сложную проблему в разработке, с которой вы сталкивались. Как вы её решили?
Если вас примут в Apple, то будете ли вы скучать по чёму-то с прошлой работы? По чёму вы будете скучать больше\меньше всего?
Занимаетесь ли вы улучшением своих навыков вне работы?
Опишите случай, когда вы сделали для клиента всё возможное.
Объясните 8-ми летнему ребёнку, что такое модем\роутер и его функции.
Как должность, на которую вы претендуете, сочетается с вашим 5-ти летним карьерным или жизненным планами?
Над чем вы хотели бы работать, если мы вас наймём?
Как бы вы тестировали ваше любимое приложение?
Как бы вы повели себя, если бы в поддержку обратился клиент с устаревшим продуктом?
На собеседовании в Apple советуем вам использовать метод STAR для ответа на поведенческие вопросы:
Опишите ситуацию.
Опишите задачу.
Опишите шаги которые нужно предпринять для её решения.
Опишите достигнутый результат.
Советы для подготовки к собеседованию в Apple
Работайте с разными инструментами. Хорошая идея сочетать использование маркерной доски, онлайн курсов, и имитации собеседования. Очень важно тренироваться говорить вслух о том, как вы решаете задачу.
Напишите план обучения. Рекомендуется написать детальный план на 3-6 месяцев, чтобы ничего не упустить.
Избегайте заучивания. Также не заучивайте вопросы. Вместо этого практикуйтесь в создании реальных продуктов, которые могла бы использовать Apple. Это идеальный способ подготовиться к собеседованию: вы изучаете концепции, практикуетесь в решении проблем и обретаете уверенность, проектируя для Apple.
Аналитик прошёл 45 собеседований за два месяца — рассказываем, как изменился рынок труда в IT, через что проходят кандидаты, как не перегореть, отсеивать токсичные компании и выстроить стратегию поиска, которая действительно работает.