


Что ещё делают RnD-специалисты, кроме разработки новшеств

Раскрываем все карты: что делают RnD-специалисты на работе и как устроены исследования в RnD-отделе Ростелекома.
1К открытий7К показов

Данил Мусин
системный инженер ПАО «Ростелеком»
RnD — это не только создание новых продуктов, но и поддержка уже существующих, создание документации и проверки, проверки, проверки. Сегодня расскажу подробнее о дне специалиста из RnD-отдела и о том, как проходит работа над задачами.
В RnD-команде мы исследуем инструменты, чтобы эффективно интегрировать их с внутренними продуктами компании — у разработки обычно нет на это времени. Также проверяем дополнительные критерии и требования, добавляем специфичные параметры, то есть задача приходит в усложнённом виде.
Каждую неделю мы встречаемся с коллегами, лидами из других команд, направлений, которые занимаются и разработкой, и поддержкой внутреннего продукта. Они предлагают гипотезы.
Формируем исследование
Из предложенных гипотез мы прорабатываем задачу. Например, коллегам из ЦХД, которые налаживают передачу данных между различными системами компании, нужно было найти open source ETL-инструмент как замену CDC и Informatica, чтобы одним продуктом обеспечить импортозамещение имеющихся. Так как один из часто используемых CDC-пайплайнов — это захват данных из санкционного Oracle и выгрузка в Postgres и GreenPlum.
Мы собрали предварительный список из 25 продуктов. Так как инструментов много, мы составили таблицу критериев оценки, чтобы на начальном этапе исключить неподходящие:
● наличие удобного UI, чтобы программистам было интуитивно понятно, как пользоваться инструментом;
● открытый исходный код;
● возможность подключения сторонних JDBC-драйверов и планировщик заданий.
Так, удалось вычеркнуть больше половины: где-то не было UI, где-то поддержки JDBC, где-то отсутствовала ролевая модель или интеграция с Active Directory. Какой-то инструмент запускался только скриптами — а планировщик заданий был неинтерактивный.

Изучаем документации продуктов и сокращаем количество вариантов
У нас осталось 5 продуктов вместо 25, их документации мы исследовали уже пристальнее. Нужно было проверить:
— работоспособность,
— надёжность,
— использование,
— производительность.
А также убедиться, что со всеми источниками действительно можно подключиться по разным протоколам: по JDBC, ODBC, через PXF. Дополнительно проверить наличие ролевой модели, возможность работать через API. Так, мы устанавливали, настраивали, пересобирали из исходников, интегрировали одни пакеты с другими.
Остановились на Apache NiFi. У него нет такого понятия, как пакеты, он не видит сырые данные. Они обрабатываются в другом формате, и инструменту требуется постоянная загрузка данных через свою очередь сообщений, чтобы выкачать их в другую систему. Это вызывает дополнительную нагрузку, поэтому ему нужна большая архитектура, инфраструктура для работы с большим объёмом данных.
Мы всё это зафиксировали и предоставили заказчику сводную таблицу со всеми факторами и объяснениями, почему остальные варианты не подходят и лучше оставить только NiFi. Да, инфраструктуру придётся создавать, зато он оказался самым подходящим по всем параметрам.
Документируем исследования (иногда это самое сложное)
Главное — задокументировать все результаты и метрики и подробно описать шаги, которые мы предпринимали, и ошибки, которые случались.
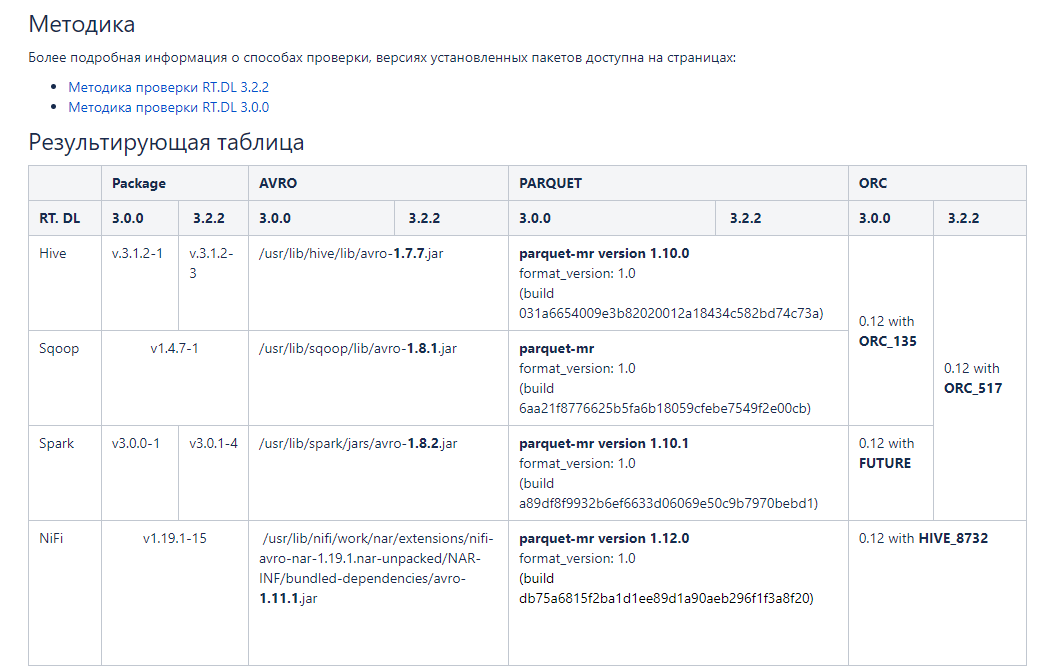
Был кейс, когда нам нужно было выявить для RT.DataLake (хранилище данных) с какими версиями файлов работают различные версии нашего Hadoop-кластера — Sqoop, Spark, Hive, NiFi. Чтобы они поддерживали и чтение, и запись в один тот же формат. А также проверяли, с каким именно форматом и версией они работают.
Нам сразу было понятно, что мы используем, в какой очерёдности и как это сделать. Самым тяжёлым стало составлять документацию. На это просто ушло много времени, потому что нужно было описать все шаги проверки, построения пайплайна.

У Avro (строковый формат хранения) нет специализированного формата файлов, там просто версии схем. Это никак не влияет на чтение и работоспособность. Есть различные версии библиотек, которые могут читать этот файл. Мы взяли не версию Avro, а версию файлов библиотеки, которая обрабатывает эти файлы.
Для ORC (столбцовый формат хранения) мы проводили запись через Hive в таблице ORC. Прочитать исходные ORC-файлы не получилось, поэтому мы записывали из NiFi в ORC-файлы через HDFS, а считывали с помощью NiFi через Hive.
Причём это были одни и те же данные, структурные таблички. Но способы получения и подключения к ним отличаются. По сути там были небольшие различия в ревизиях ORC-файлов с пометками об обновлениях поддержки.
Также мы проверяли и сравнивали версии Parquet — с этим форматом было меньше всего проблем. У него во всех продуктах используется версия 1.0, а отличия только в номере сборки. Поскольку формат Parquet часто применяют в Big Data-решениях, то мы быстро нашли инструкцию по проверке в каждом из ПО, и сложностей не возникло.
Аргументируем бесполезность инструментов
Заказчик предложил изучить, подходит ли eMondrian — форк Mondrian от зарубежной компании Pentaho, которая закрыла исходники — для внедрения в наш прод в рамках дополнительного функционала работы с OLAP-кубами с использованием Excel, OpenOffice и LibreOffice.
Мы не увидели в нём потенциала. Во-первых, он устарел и давно не поддерживается сообществом в GitHub. Во-вторых, функционал по настройке схем очень узкий, некоторые функции просто не получилось подружить с нашими продуктами. А ещё он плохо конфигурируется в части требуемой интеграции. Более того, прямо в комментариях в исходнике написано: это мы сделаем в будущем релизе, а вот эту строчку, пожалуйста, оставьте, она необходима, но зачем — мы не знаем.

В итоге мы показали заказчику тот функционал, который смогли найти. Объяснили, что это решение не достойно внедрения в прод, оно не кластерное, не отказоустойчивое, да там, грубо говоря, один Java-файл. Заказчик нас услышал, и мы закрыли исследование.
Делимся экспертизой с коллегами на демонстрациях
Бывало и такое, что изначальный заказчик отказывался от инструмента, но его подхватывал другой. Так было с Dremio. Он показался нам сырым, но, пока мы три недели его внедряли, настраивали, интегрировали, нашли много полезного функционала.

Заказчик не увидел в этом продукте пользы для себя. Но на демонстрации было другое подразделение, которое заинтересовалось наработками. Мы их переконфигурировали, нагрузили другими данными, проверили другие интеграции. Инструмент хорошо зашёл и ушёл в пилот. Сейчас для него уже развёрнуты сервера, проведён пилот, и ведётся подготовка к внедрению в прод.
В RnD не обязательно знать всё
Первое время в RnD-отделе может быть страшно: постоянно нужно быть в курсе новых трендов, кажется, что нужно знать абсолютно все продукты досконально, чтобы от тебя был толк. Но знать всё невозможно. Зато можно выработать методологию отбора инструментов и шкалу оценок, которые помогут стандартизировать процесс исследования. Тогда страх быстро развеется.
А исследования не уходят в стол. Мы оставляем документацию, и часто после демонстраций к нам возвращаются коллеги, которые видят, какую пользу мы в целом приносим как RnD-отдел. Мы сокращаем время других команд на исследования, находим недостатки в существующих продуктах, заводим баги и привносим что-то новое в другие продукты.

1К открытий7К показов
С 2018 года мы писали замену Jira — для себя и под себя. В итоге получился классный аналог продуктов Atlassian, и мы хотим поделиться им.
Представляем подробный гайд по dbt — Data Build Tool — одному из лучших фреймворков для трансформации данных.

Рассказываем, какие этапы прошли, создавая дата-офис в «Ростелекоме»: от инвентаризации проектов до формирования data-driven культуры.

Мы создаём новую среду разработки приложений для ОС Аврора и не только. При этом стараемся сделать её интуитивно понятной, без необходимости вручную настраивать окружение и гуглить каждый шаг. Рассказали, что уже есть и что планируем добавить.