Как serverless-технологии помогают снизить нагрузку на разработчиков

Используйте serverless-технологии, чтобы разработчики сосредоточились на написании кода, а продукт вышел на рынок быстрее и дешевле.


Антон Черноусов
Developer advocate Yandex Cloud
В мире наблюдается острый дефицит разработчиков. По данным IDC, в 2021 году компаниям во всем мире не хватало 1,4 млн штатных разработчиков. А к 2025 году их дефицит вырастет до 4,0 млн. Чтобы дать разработчикам возможность сосредоточиться на написании кода и бизнес-логике приложений, ускорить время вывода продукта на рынок, и при этом снизить затраты на инфраструктуру, организации всех размеров — от стартапов, до крупных предприятий — все чаще используют serverless-технологии. Согласно данным исследования компании Datadog, спрос на FaaS сервис AWS Lambada вырос в три раза всего за один год. По прогнозам Mordor Intelligence, в 2021-2026 годах среднегодовой темп роста рынка serverless превысит 23%. Как использование бессерверных вычислений меняет практику DevOps?

Почему идея о разделении ресурсов снова стала популярной
Развитие технологий циклично — одни и те же подходы и методы регулярно повторяются на новом этапе технологического развития. Все началось во времена мейнфреймов и старых компьютеров, когда вычислительных ресурсов не хватало и они выделялись под конкретную задачу. Следующим этапом стали shared-сервера, внутри которых работали исполняемые скрипты. Запрос поступал на сервер, обрабатывался, затем совершался вызов и конкретному скрипту выделялось определенное количество ресурсов. Различные механизмы разделения вычислительных ресурсов одного сервера применялись и ранее в рамках операционных систем, например Jail в FreeBSD, С-groups в Linux, зоны в Solaris. Serverless — это новый виток идеи о разделении ресурсов в рамках большой системы.
Облако можно представить как большой компьютер, на котором можно расшарить ресурсы и забросить в него кусочек кода, чтобы он там исполнялся. Основная идея serverless в том, чтобы меньше думать о том, где и как хранятся данные, где они будут обрабатываться. Задача разработчиков внутри компании — сфокусироваться на реализации бизнес-логики, а за исполнением конкретных функций (количество экземпляров, время запуска, утилизация ресурса и т.д.) будет следить облачный провайдер.
Еще один важный фактор — логика развития технологий, которая стремится к микросервисной архитектуре и разделению больших монолитных приложений на отдельные составляющие, которые могут быть микроскопическими. В рамках подхода function as a service каждая отдельная функция — это микросервис, который реализует определенную функциональность в рамках общего процесса.
Но когда ПО разделено на микросервисы, управлять им становится дорого и сложно. Возникают дополнительные расходы, связанные с менеджментом, безопасностью, обслуживанием. И здесь экономически оправданным становится использование облачной платформы, которая позволяет оптимизировать управление микросервисами и, как следствие, сокращать издержки.
Разделение ответственности
Жизненный цикл сервиса завязан на платформу, которая обеспечивает его запуск, скорость ответа, runtime, безопасность. При работе с отдельными функциями или serveless-контейнерами разработчикам не нужно думать о поддержании работоспособности инфраструктуры — достаточно создать функцию и она будет выполняться, а все необходимые параметры может обеспечить облачный провайдер.
Полноценная serverless экосистема обязательно включает в себя объектные хранилища, базы данных, сервисы работы с потоками, поддержку триггеров. Разработчику больше не нужно думать о том, как разворачивать или обслуживать данные сервисы. Например, чтобы запустить функцию, достаточно загрузить ее код в сервисы облачных функций и настроить к ней публичный доступ. Не нужно совершать действия, связанные с обеспечением безопасности, выделением ресурсов и дополнительных мощностей на запуск экземпляров функций в рамках существующей квоты. Например, для serverless баз данных большую часть работы, связанной с администрированием, берет на себя облачный провайдер, а пользователю остается получать доступ к автоматические масштабируемой системе и оплачивать только объем потребленных ресурсов.
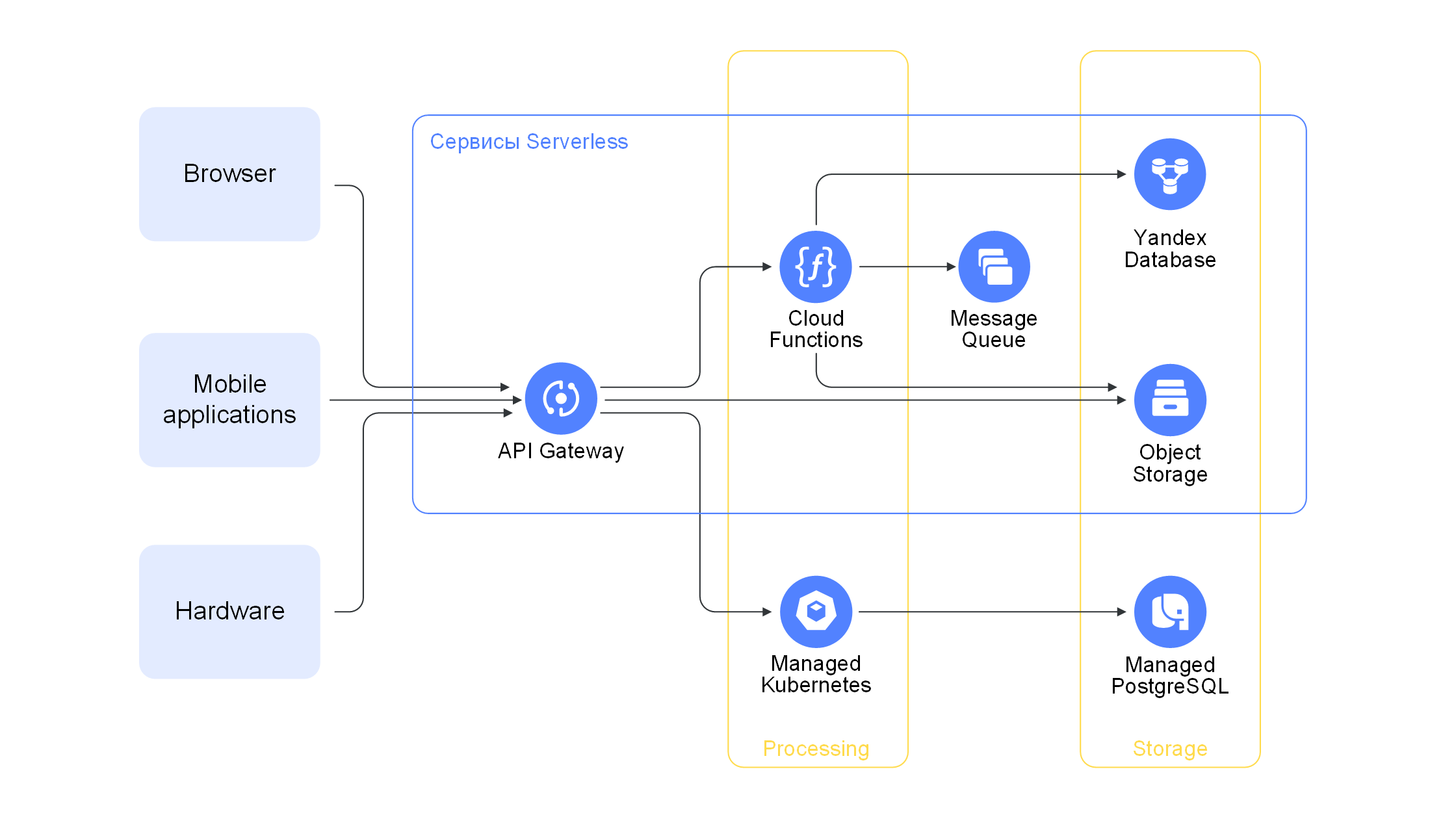
Благодаря такому подходу сокращается объем DevOps-задач в рамках микросервисных архитектур, с разработчиков снимается часть рутины и снижается когнитивная нагрузка. Использование бессерверных вычислений меняет практику DevOps, так как они не требуют того, чтобы разработчики поддерживали операционные системы и отвечали за все возможные риски. Вместо этого они могут создавать универсальный код, а затем загружать его в бессерверную платформу и контролировать его выполнение.
Например, биоинформатики компании Genotek благодаря применению бессерверного подхода смогли сосредоточиться на написании кода и не задумываться о производительности, обслуживании и масштабировании баз данных. Их сервис позволят создавать генеалогические деревья и искать родственников с помощью базы генетических данных. Технологии serverless позволяют реализовать подход «функция как услуга», при котором для выполнения каждого запроса автоматически создается отдельный контейнер или виртуальная машина с необходимыми характеристиками, после выполнения созданный объект уничтожается. Функция забирает из базы данные по запросу и создает деревья для каждого пользователя. Разработчик получает автоматическое масштабирование и отказоустойчивость, а приложения превращаются в совокупность отдельных функций, которые запускаются по необходимости. При увеличении количества пользователей сервиса не нужно поднимать новые виртуальные машины или настраивать балансировку — вместо этого автоматически создаются дополнительные экземпляры функции, которые выполняются параллельно.
Для решения каких задач подходит serverless
Serverless — идеальное решение для пиковых нагрузок, зависящих от сезонности и прочих периодических факторов. Например, в рамках маркетинговых кампаний, для анализа уже обработанных заказов. Или в ситуации, когда разработчику необходимо регулировать нагрузку за счет квот. Увеличение количества экземпляров функции, которые могут одновременно принять входящие сообщения, увеличивает пропускную способность системы. Потому что квоты — хороший инструмент для регулирования и обработки такого объема данных. Сейчас такой подход можно реализовать с помощью других инструментов — например, весь входящий поток данных принять в serverless-очередь и разобрать ее с помощью триггеров. Но этот сценарий применим в случае, когда не требуется срочный ответ на запросы внешних потребителей.
Например, портал Auto.ru использовал serverless-технологии, при запуске проекта «Большой экзамен ПДД» — онлайн-теста для пешеходов и водителей. Ожидалось, что специально запущенный лендинг будет испытывать высокую нагрузку, когда в онлайн-тесте массово начнут участвовать пользователи. Поэтому было важно обеспечить автоматическое масштабирование сервиса. В результате приложение выдержало пиковые нагрузки — более 100 тыс. людей успешно проверили себя в тестировании.
Serverless-решения не подходят для задач, где требуется гарантированное быстрое время ответа и обработка запросов в режиме реального времени. Serverless предполагает постоянно изменяющийся паттерн нагрузки. Если нагрузка постоянная, проще использовать сервисы, рассчитанные на постоянную загрузку выделенных ресурсов (контейнеры в Kubernetes-стеке, базы данных, работающие 24/7 с гарантированным временем отклика).
Что будет дальше с serverless-технологиями
На конференции AWS re:Invent 2021 главные анонсы гиперскейлера были посвящены serverless-технологиям. Основная идея, которая связывала доклады, заключалась в том, что serverless-подход прошел пик хайпа и вышел на плато продуктивности. Сообщество разработчиков приходит к мысли, что ресурсы, которые предоставляются облачными провайдерами, должны стать serverless.
Serverless — это следующий этап развития облачных сервисов на основе открытых баз данных. Разработчики давно привыкли к существующим решениям и хотят иметь либо точно такой же протокол работы с serverless-базами данных, либо собственную базу данных, работающую по принципу serverless. В ближайшие пару лет можно ожидать расширения поддержки бессерверных технологий внутри существующих баз данных или появления решений, которые эмулируют их.

2К открытий2К показов

Google активно встречается со СМИ и предлагает протестировать свой новый инструмент на основе ИИ для написания новостей.

Урс Питер на KotlinConf 2023 объяснил, какие принципы сделают код функциональнее, рассказал про монады, контейнеры и библиотеку Arrow.

Сбер создал веб-приложение на основе технологий PWA, которые позволяют использовать сайт как обычное приложение для смартфона.
Наука о данных стала популярна лишь в 2010-е, но история Data Science началась чуть ли не 40 000 лет назад. Рассказываем, с чего именно.