


Инструменты машинного обучения для начинающих

Помогаем новичкам разобраться и систематизировать различные инструменты машинного обучения (фреймворки, библиотеки и сервисы).
18К открытий20К показов
Прежде, чем мы с вами перейдём к инструментам машинного обучения, стоит проговорить одну простую, но важную вещь. Начинающие часто воспринимают машинное обучение как огромный цельный процесс. Нередко пугаются и впадают в ступор из-за обширности темы. Поэтому начнём с разделения процесса машинного обучения на три основных этапа:
- Сбор и обработка данных.
- Обучение и оценка модели.
- Использование обученной модели.
В таком же порядке рассмотрим и инструменты, которые помогут всё это реализовать.
Языки программирования для машинного обучения
Нам понадобятся готовые библиотеки и фреймворки для машинного обучения. Мы ведь хотим научиться ездить на машине, а не конструировать её. Если вы пытаетесь подобрать «тот, самый подходящий» язык, то не переживайте: в любом современном языке программирования уже написаны такие инструменты, поэтому берите любой, который нравится (или знаете).
Но если мы начнём рассказывать обо всех языках в одной статье, то она будет очень длинной. Поэтому дальше будем рассматривать всё, что связано именно с Python, популярность которого стабильно растёт на протяжении вот уже нескольких лет благодаря своей гибкости, хорошей читаемости и простоте в обучении. Написанные под него библиотеки машинного обучения — самые популярные на момент выпуска статьи.
Инструменты для сбора, обработки и визуализации данных
Здесь мы собираем данные с различных сайтов и создаём датасет, который потом используем для обучения алгоритма. Сбор данных с сайтов ещё называют веб-скрейпингом (ранее мы подробно рассказывали об инструментах для веб-скрейпинга).
После того, как собрали данные, их нужно обработать, чтобы избавиться от ошибок, шума и несогласованностей, которые приведут к ситуации «мусор на входе — мусор на выходе». Это очень важно, так как от корректности данных будет зависеть точность результатов алгоритма.
Визуализация поможет определить линейность структуры данных, существенные признаки и аномалии. Для этих задач можно воспользоваться готовыми веб-сервисами, либо написать собственный код.
После того как мы почистили наш датасет, нужно поделить его на 80% — для обучения модели, — и 20% — для её проверки и тестирования.
pandas: библиотека для обработки и анализа данных
Она построена поверх NumPy, о котором поговорим чуть дальше. Это наши группировки, сортировки, извлечения и трансформации. Для работы с файлами CSV, JSON и TSV pandas превращает их в структуру данных DataFrame со строками и столбцами. Выглядит, как обычная таблица в Excel, и работать с ней легче, чем с for-циклами для прохода по элементам списков и словарей.
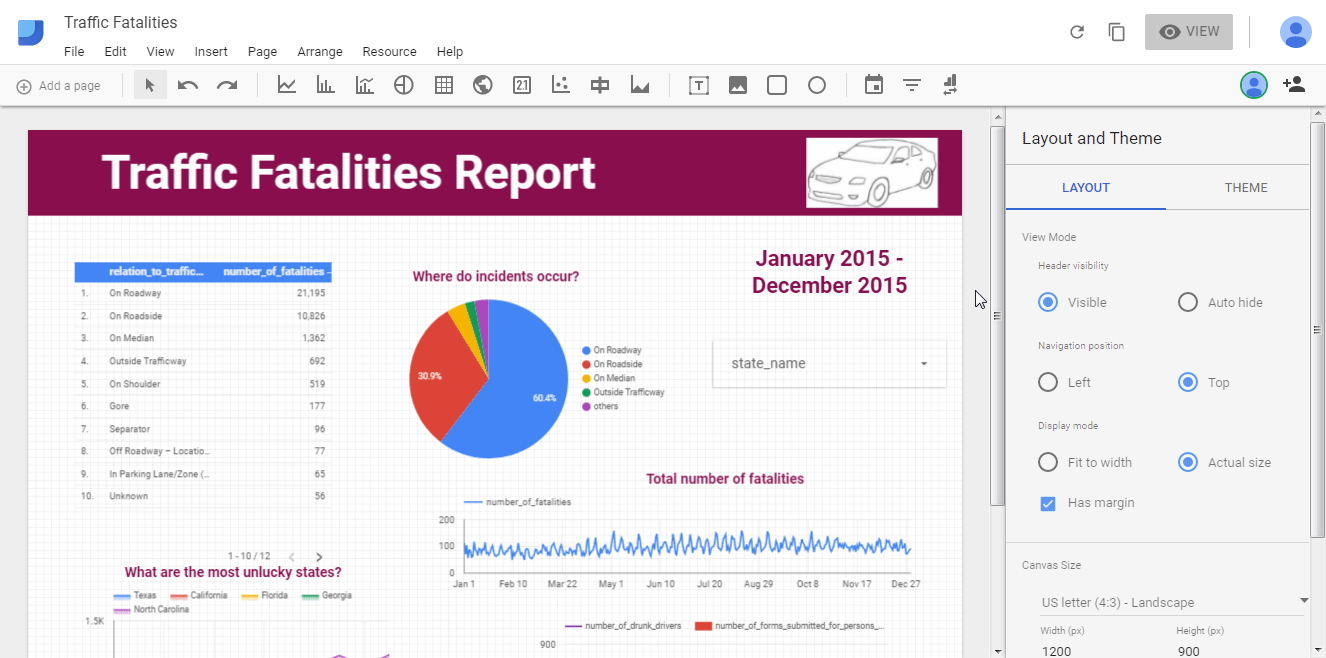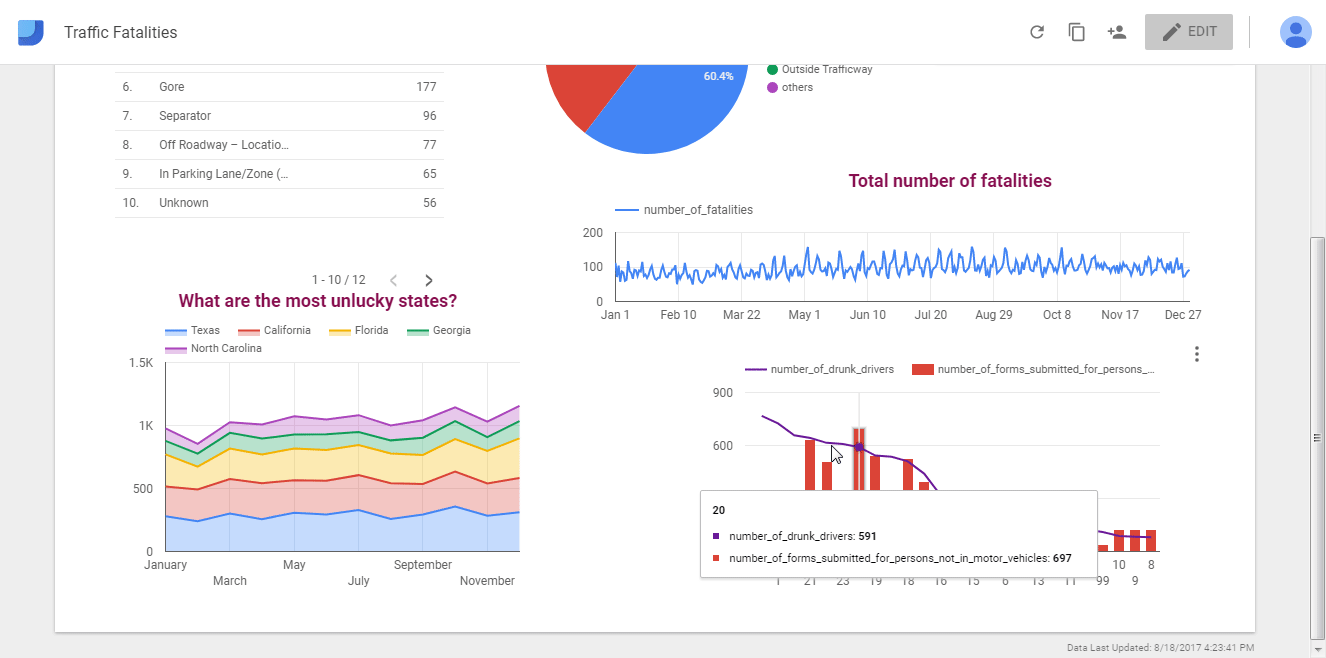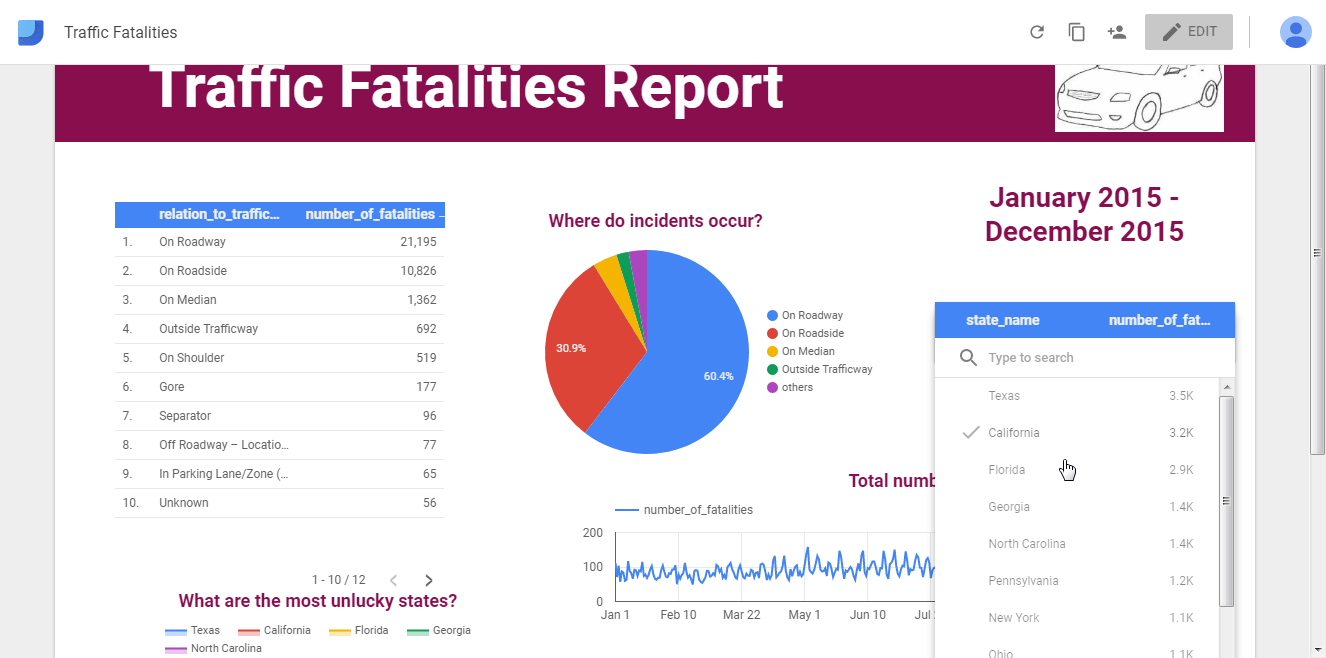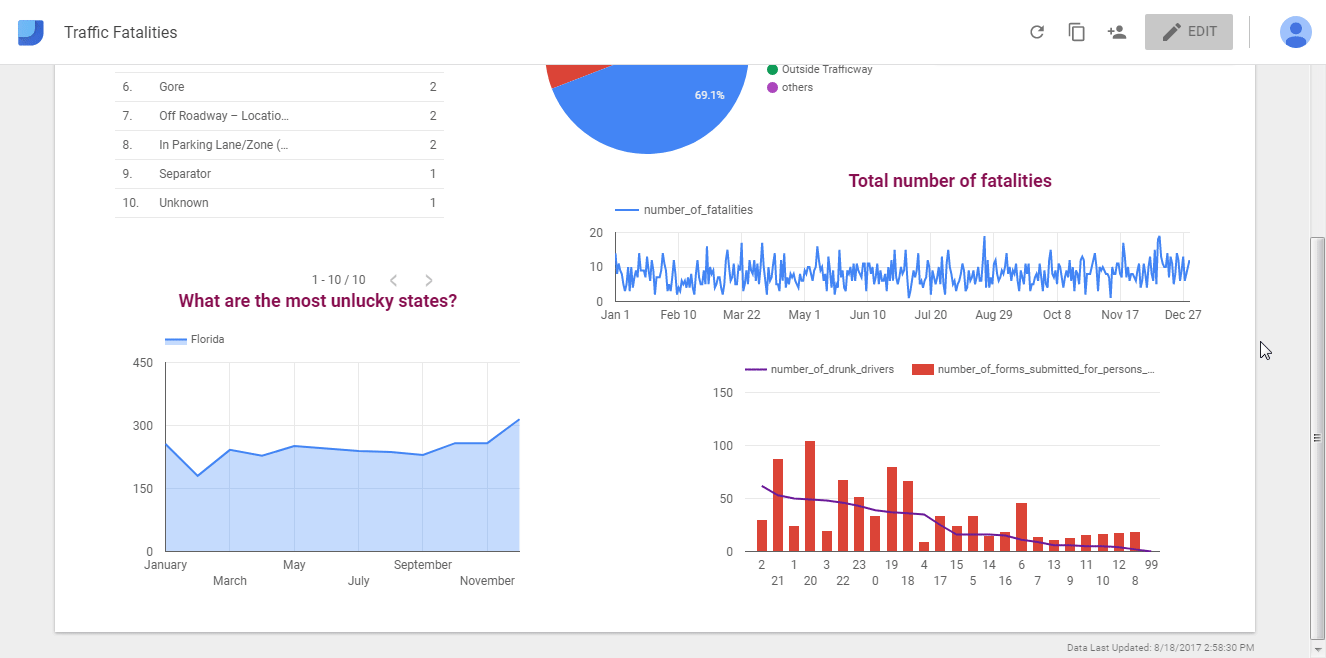
Tableau, Power BI, Google Data Studio: простая онлайн-визуализация без кода
Инструменты для бизнес-аналитики и людей без особых навыков программирования. Ключевое слово здесь — визуализация. Загружаем датасет и пользуемся встроенными функциями, фильтрами и аналитикой в реальном времени. Эти сервисы быстро собирают инсайты и представляют их в наглядной форме. И Tableau, и Power BI, и Google Data Studio имеют как платные подписки, так и бесплатные версии (само собой, с ограничениями).
Matplotlib: библиотека для построения 2D-графиков
Matplotlib в связке с библиотеками seaborn, ggplot и HoloViews позволяет строить разнообразные графики: гистограммы, диаграммы рассеяния, круговые и полярные диаграммы, и много других. Для большинства из них достаточно написать всего пару строк.
Интерактивные среды разработки
Эти инструменты часто используются для Data Science и машинного обучения. Веб-среда (её также называют «notebook») позволяет разработчикам на лету тестировать небольшие части кода, проверять функциональность и разные гипотезы. Тем не менее, при желании в ней можно поместить и целый проект.
Jupyter Notebook: интерактивное моделирование
Простая в использовании бесплатная интерактивная веб-оболочка. Помимо Python, Jupyter Notebook поддерживает более чем 40 языков программирования. В нём удобно экспериментировать с новыми идеями в режиме «зашёл-сделал-вышел», писать документацию и создавать аналитические отчёты. Напоминает IDE, но по функциональности, хоть и достаточно широкому, до неё не дотягивает.
Среди инструментов для машинного обучения, и в целом Data Science, Jupyter хорош благодаря быстрому анализу, моделированию и визуализации данных. Результаты можно экспортировать во множество форматов, в числе которых — широко распространённые PDF и HTML.
Kaggle: сообщество Data Science
Kaggle также предоставляет интерактивную среду разработки. Разница в том, что всего один клик отделяет вас от целого сообщества Data Science и машинного обучения. Здесь можно найти готовые датасеты, модели и даже программный код для решения разных задач.
Также крупные коммерческие компании часто проводят здесь конкурсы и разыгрывают призовой фонд в обмен на бесплатную лицензию на использование интеллектуальной собственности (алгоритма и программного обеспечения) победившего участника.
Фреймворки и библиотеки для общего машинного обучения
Обучение модели делится на две большие категории: с учителем и без. В первом случае мы маркируем датасет, объясняя алгоритму машинного обучения, где правильный ответ, а где — нет. Так данные можно представить таблицей соответствий «элемент-категория».
Во втором случае алгоритм сам вынужден искать признаки и закономерности, так как в датасете мы даём данные без уточняющей информации. Датасет представлен сплошным потоком данных нужного типа: текста, картинок и др.
Для каждой категории используются свои алгоритмы машинного обучения (кластеризация, классификация, регрессия, ассоциация). Оптимальный выбор зависит от задачи, сложности модели, размера и типа данных.
Имейте в виду, что обучение и отладка собственной модели — долгий и затратный процесс. Очень вероятно, что кто-то уже решал похожую задачу и подготовил модель. Поэтому стоит поискать, воспользоваться реализованной архитектурой и переучить алгоритм под ваши данные. Но чем больше ваша задача отличается от той, что решает готовая модель, тем больше нужно её переучивать и менять параметры.
NumPy: готовые вычислительные алгоритмы и линейная алгебра для машинного обучения
Данные в машинном обучении представлены числовыми массивами. Даже если мы работаем с картинками или естественной речью, они должны быть преобразованы в числовые массивы. В NumPy уже реализовано всё необходимое для этого: преобразование Фурье, генерация случайных чисел, перемножение матриц и другие сложные операции. Вам остаётся только пользоваться.
NLTK: разбираем естественный язык на части
Один из ведущих инструментов для обработки естественного языка. По аналогии с тем, как NumPy упрощает линейную алгебру, NLTK упрощает парсинг текста, анализ тональности, структуры предложений и всё, что с этим связано.
scikit-learn: всё гениальное просто
Позиционируется как простая библиотека с кучей примеров на официальном сайте, из-за чего хорошо подходит новичкам. Но это не значит, что для серьёзных проектов он не годится.
Spotify, например, сделали свою рекомендательную систему как раз с помощью scikit-learn. Работает в связке с SciPy, NumPy и Matplotlib. Все базовые функции типа кластеризации, классификации и регрессии, разумеется, на месте.
Фреймворки глубокого обучения и моделирования нейросетей
Упомянутые инструменты машинного обучения позволяют нам получить модель, способную выполнять сравнительно простые задачи. Однако дальше речь пойдёт о глубоком машинном обучении нейронных сетей. Здесь для принятия более сложного решения алгоритм учитывает различные факторы, пропуская входящие данные через множество слоёв нейронов.
Само собой, для этого нужно больше вычислительной мощности и данных для обучения. Например для GPT-3 OpenAI насобирали датасет из 45 ТБ текстовых данных и отфильтровали его до 570 ГБ. Обучение модели стоило им миллионы долларов. При этом использовали они даже не весь текст. Поэтому в проектах поменьше обучение часто делегируют облачным сервисам типа Google Cloud или Amazon AWS.
На рынке инструментов глубокого машинного обучения классическая ситуация: бодаются два мастодонта — фреймворки PyTorch и TensorFlow. Раньше в них были существенные отличия. Но разграничения постепенно стираются с тем, как они перенимают друг у друга лучшие особенности.
PyTorch: король исследований
Прост в изучении и понимании, хорошо дружит с остальной питоновской экосистемой. Поэтому к новичкам PyTorch относится мягко. Отладка проходит на интуитивном уровне: ставим брейкпоинт куда угодно в коде и смотрим значения переменных. Ещё исследователям нравятся динамические графы, благодаря которым можно менять поведение модели на ходу. Всё это позволяет проверять различные теории и подходы на небольших датасетах без долгих задержек.
TensorFlow: король продакшена
Главное отличие — в подходе. Если PyTorch правит в академической среде, то TensorFlow изначально ориентирован на рынок. Да, графы у него статические; для отладки нужно учиться работать с отдельным дебагером tfdbg; а его API меняли кучу раз, ломая при этом обратную совместимость. Но он заточен для решения задач именно бизнеса: пропускать через себя огромные массивы данных при хорошей производительности и с возможностью использовать модели на мобильных устройствах без костылей и бубнов. Хотя и PyTorch уже двигается в этом направлении.
Keras: «С++ машинного обучения»
Первое, что новичок замечает в TensorFlow — это сложность. Ведь буквально всё находится и происходит внутри графа — и операции, и числа. А значит, не так, как обычно.
Keras — более высокоуровневый интерфейс для TensorFlow, CNTK, Theano, MXNet и PlaidML. Простыми словами, он создан, чтобы стать языком «С++ машинного обучения» для низкоуровневых фреймворков. Новичок может не думать, как реализовать тензорную алгебру, построить модель и прочее. Он просто воспользуется готовыми строительными блоками. Мыслительный ресурс освобождается, из-за чего начинающие специалисты быстрее учатся, а более опытные разработчики больше концентрируются на стратегических задачах.
TensorBoard: козырь в рукаве TensorFlow
Человеку непросто держать и анализировать в голове все данные. Нативная визуализация графов в браузере с разными метриками и возможностью отслеживать работу моделей — то, чего нет у PyTorch. Конечно, можно сказать про Visdom, но по возможностям он сильно уступает TensorBoard. Поэтому в PyTorch приходится часто использовать Matplotlib для визуализации и писать графики самому.
В этом аспекте TensorFlow выигрывает. Помимо метрик, разные структуры можно окрашивать в зависимости от используемого для вычислений устройства (CPU или GPU), подсвечивать узлы для отслеживания входящих данных, отображать несколько графов одновременно. Словом, всё, чтобы мониторить работу было легко и удобно.
Какие ещё инструменты машинного обучения вы бы посоветовали? Расскажите в комментариях!

18К открытий20К показов

Как мы убили 400ms лаги в банке и выжали из Java 55k транзакций/сек: хардкор про GC и адреналин

Что обсуждали на PyCon 2025? Отказ от GIL в CPython 3.14, управление зависимостями, статический анализ, научный код, ML4Code и безопасность open source — всё о будущем Python.

Как создать инструмент, который позволяет переключать слайды с помощью голосовых команд и контекстного анализа речи. В статье разбирается микросервисная архитектура на React и Python (FastAPI), использование модели OpenAI Whisper для транскрибации в реальном времени и интеграция LLM GigaChat для интеллектуального ведения презентации. Также описываются проблемы нестабильности нейросетей в живых выступлениях и реализованные решения: режим байпаса и навигация по ключевым словам.

Вместе с Никитой Егоровым, ведущим аналитиком в МТС Диджитал, объясняем принципы партиционирования простыми аналогиями, сравниваем с шардированием, разбираем стратегии разбиения данных и популярные инструменты (PostgreSQL, BigQuery, ClickHouse).