


Многоступенчатый фильтр: как очистить огромный массив данных от дубликатов
Рассказали, как удалить дубликаты в огромной базе данных, и о том, как обработать большой объем данных невысокого качества.
3К открытий6К показов
Дедупликация необходима для повышения комфорта и эффективности при использовании данных потребителями, а также при решении задач, связанных с хранением данных, аналитикой. В крупных проектах наиболее эффективен комплексный подход к дедупликации, включающий в себя несколько этапов очистки и сочетающий разные методы.
Разработчик компании IT_One Анна Зверькова рассказывает о нюансах этой процедуры и способах обработки большого объема данных невысокого уровня качества на примере из финансовой отрасли.
Общие сведения
Дедупликация – это процесс поиска и удаления дублирующихся записей в наборе данных. При этом дубликаты записей могут как быть абсолютными, то есть полностью идентичными по всем полям, так и неполными, когда несколько различающиеся записи тем не менее, относятся к одной сущности и должны быть интерпретированы как одна запись.
Пример абсолютных дубликатов:

Пример дубликатов с неидентичными полями:

Возникновение дубликатов в базе данных может быть вызвано внешними и внутренними причинами. К внешним относятся, например, загрузка сходных данных из разных источников или регулярное получение новых порций информации из одного и того же источника. К внутренним – повторное добавление в хранилище уже имеющихся в нем данных, обработанных несколько другим способом, а также другие артефакты.
Обозначим три причины, которые делают дедупликацию насущной необходимостью:
- упрощение использования данных, чтобы конечные потребители при виде трех похожих записей не ломали голову, имеют ли они дело с одной и той же сущностью, или с тремя разными;
- упрощение анализа данных, в том числе при использовании ML, когда большое количество дубликатов может привести к некорректной работе модели, ее «переобучению»;
- повышение эффективности хранения данных, сокращение объема хранимых данных.
Простейшие случаи для осуществления дедупликации – когда записи попадают в хранилище данных из одного источника, есть уникальные идентификаторы записей и качество внесения данных в базу поддерживается на высоком уровне. В этом случае, для получения дедуплицированных данных можно ограничиться применением простого DISTINCT и дедупликации по уникальным ключам.
Однако чаще всего вмешивается ряд факторов, осложняющих дедупликацию. Приведем примеры таких ситуаций на данных из сферы кредитования. Записи о кредитах физических и юридических лиц хранятся как в базах данных кредитных организаций (банков, микрофинансовых организаций и др.), так и в базах данных бюро кредитных историй и регуляторов, контролирующих их деятельность.
Факторы, осложняющие дедупликацию:
- Отсутствие уникальных идентификаторов, ошибки в заполнении уникальных идентификаторов. Например, ИНН человека, который должен быть уникален, на самом деле для регулирующего органа не всегда может быть таким уникальным идентификатором: известны случаи, когда по ошибке одному человеку присвоили несколько ИНН. Ошибки при наборе ИНН оператором, вносящим данные, также зачастую делают это поле непригодным для того, чтобы быть уникальным идентификатором, которого достаточно для того, чтобы отделить одного заемщика от другого.
- Изменение параметров сущности при сохранении ее тождественности. Например, меняя номер паспорт или фамилию при замужестве, заемщик по факту остается тем же самым человеком.
- «Мусорное» заполнение некоторых полей операторами. Например, номер телефона вместо номера паспорта, “
test test test” вместо ФИО, “1111111111” вместо номера телефона. - Незаполненные поля.
- Опечатки, в том числе одни из самых распространенных, когда соседние символы меняются местами.
- Записи в полях перепутаны местами. Например, фамилия в поле «Имя», имя в поле «Фамилия».
- Системы-источники предоставляют данные в разных форматах. Например, номера телефонов с +7 или без префикса.
- Неверно используются регистры в строчных данных – «
пЕтров» и «иванов», не тождественны «Петрову» и «Иванову». - Замена символов – ‘
ч’ и ‘4’, ‘е’ и ‘ё’, английское и русское ‘с’. - Лишние пробелы и спецсимволы.
Работая с дубликатами данных в кредитной информации, можно использовать от одного до трех шагов, описанных ниже, в зависимости от качества, полноты и объема имеющихся данных. Приведем пример на СУБД Apache Hive, однако описанные методы применимы также для других технологий хранения и типов данных.
Первый этап: предочистка, нормализация
Этап предочистки позволяет провести первичную оценку записей и отработать наиболее типичные сценарии дедупликации. Так, полностью идентичные строки мы сводим в одну запись с помощью DISTINCT.
Так же простыми командами мы можем избавиться от разногласий, связанных с различными регистрами написания строковых данных (Иванов и иванов – команда UPPER или LOWER), лишними пробелами в начале или конце строки (TRIM), лишними спецсимволами, по ошибке добавленными операторами в строковые данные.
На этом же этапе происходит унификация форматов (даты, номера телефонов).
Для того, чтобы «Аксёнов» и «Аксенов» не воспринимались как два разных человека, зачастую все «Ё» полезно привести к «Е». Вопрос английского и русского «С» менее очевиден: если операторы вводят всю информацию на русском, никогда не переключаясь на английский, приведение английского «с» к русскому может только избыточно занять мощности, не дав никакого результата.
Второй этап: работа с ошибками в данных
После первичной дедупликации полезно «посмотреть глазами» на переобъединенные группы – такие группы, куда при первичной группировке попало максимальное количество записей. Необходимо определить, корректно ли такое объединение. Зачастую оно оказывается неверным из-за «мусорного» заполнения – объединения данных по значениям, которые операторы вносят, когда у них нет реальных значений.
Например, в отсутствие паспорта у заемщика оператор вводит «1111 111111» или номер телефона вместо номера паспорта. Пустые или «мусорно» заполненные поля не должны быть использованы для дедупликации, это приведет к переобъединению – то есть отнесению разных записей к одной сущности, тогда как в реальности они являются разными сущностями. Такие записи необходимо будет дедуплицировать по сочетанию других полей.
Второй необходимый шаг этого этапа – проверка на допустимость значений в тех полях, которые мы собираемся дедуплицировать. Для ряда данных есть способы проверки их корректности, полезно обратиться к бизнес-пользователям для выяснения таких принципов для их последующей формализации в алгоритмах.
Например, контрольное число можно использовать для проверки корректности, в том числе, банковских счетов, штрих-кодов, банковских карт, СНЛС, ОКПО, ОКАТО, ISBN, ОГРН, VIN. Контрольное число – разновидность контрольной суммы, добавляется обычно в конец длинных номеров с целью первичной проверки их правильности. Это чаще всего либо последняя цифра суммы всех чисел номера, либо результат другой математической операции над цифрами.
На этом же этапе полезно использовать метрику редакционного расстояния (расстояния Левенштайна) в сочетании с оконными функциями, чтобы избавиться от опечаток в строковых данных. Например, при дедупликации кредитной информации, таким образом можно нивелировать влияние ошибок в ФИО людей.
Расстояние Левенштайна – это минимальное количество односимвольных операций (вставка, удаление, замена), которые нужно произвести для того, чтобы одну последовательность символов превратить в другую. Формула Левенштайна встроена в ряд диалектов SQL и в зависимости от характера строк может быть заменена на Jaro-Winkler.
Правда, использование обоих этих приемов сильно ограничивается тем фактом, что они значительно повышают сложность вычислений и, соответственно, снижают их скорость, в особенности на больших объемах данных.
Третий этап: таблицы дедупликации и поиск вершин в графах
Большое количество дублирующихся записей невозможно отработать только с помощью предочистки и работы с опечатками. В ситуациях, когда невозможно однозначно дедуплицировать строки по одному полю и даже по сочетанию полей, необходимо использовать таблицы дедупликации с последующим поиском вершин в графах.
Идея таблиц дедупликации состоит в том, чтобы определить дубликаты не один раз по всем имеющимся полям, а несколько раз, каждый раз по разному набору полей во разных сочетаниях, а затем объединить получившиеся данные о дубликатах.
Например, у нас есть 7 значимых полей, в части из которых допущены ошибки, часть пусты:
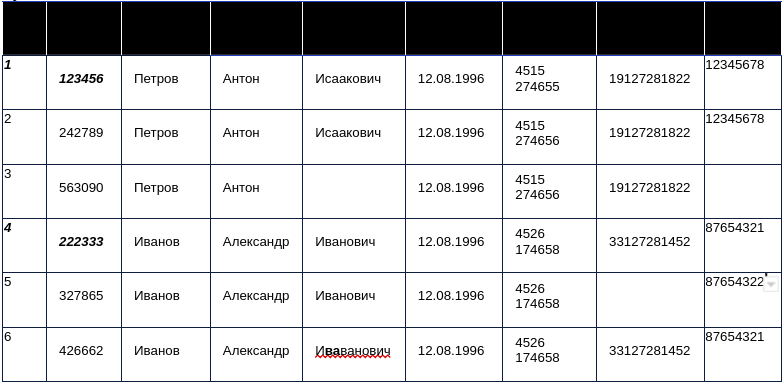
Очевидно, что запись №3 нельзя пускать в дедупликацию по полям «Отчество» и «ИНН», запись №5 – по полю «СНИЛС».
Соответственно в приведенном случае дедупликацию можно было бы провести каждому из сочетаний 4-5 полей из имеющихся 7 полей – 35 в разных сочетаниях. Однако имеет смысл с учетом бизнес-логики и опытным путем определить имеющие смысл сочетания и проводить дедупликацию только по ним. Например, в приведенном случае нет смысла дедуплицировать по сочетанию полей: «фамилия», «имя», «отчество», так как высока вероятность наличия полных тезок. В приведенном примере будет достаточно примерно 16 таблиц дедупликации.
Пример скрипта – таблица дедупликации:
Основная цель составления таблиц дедупликации – присвоить каждому «сырому id», то есть тому, с которым к нам попала запись, с неким «групповым id». Общий «групповой id» присваивается всем тем записям, которые мы определяем как дубликаты. Причем «групповым id» будет минимальный сырой по группе – то есть такой, с которым данная сущность попала к нам в первый раз.
Например:
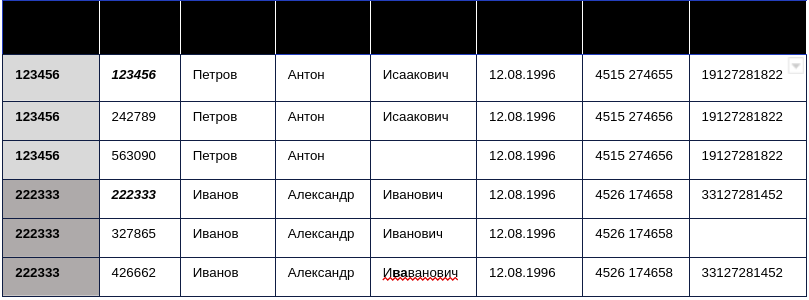
При составлении таблиц дедупликации важно проверять «глазами» пере-объединенные и недо-объединенные группы для поиска аномалий. Переобъединенные группы – такие, в которых было объединено больше всего записей. Зачастую именно в них оказываются записи с мусорным заполнением, вроде “test test test” вместо ФИО, “1111111111” вместо номера телефона, которые надо будет исключить из дедупликации по данным полям в дальнейшем.
Пример использования формулы Левенштайна для нивелирования ошибок в таблицах дедупликации:
Получившиеся таблицы дедупликации объединяем простым UNION. Мы получили одну большую таблицу, в которой каждому изначальному («сырому») ID в записи соответствует вновь присвоенный некий групповой ID. Фактически таким образом мы получили много ребер графа, которые нужно связать между собой, чтобы отнести комплект дублирующихся записей к одной сущности (в нашем примере – субъекту персональных данных).
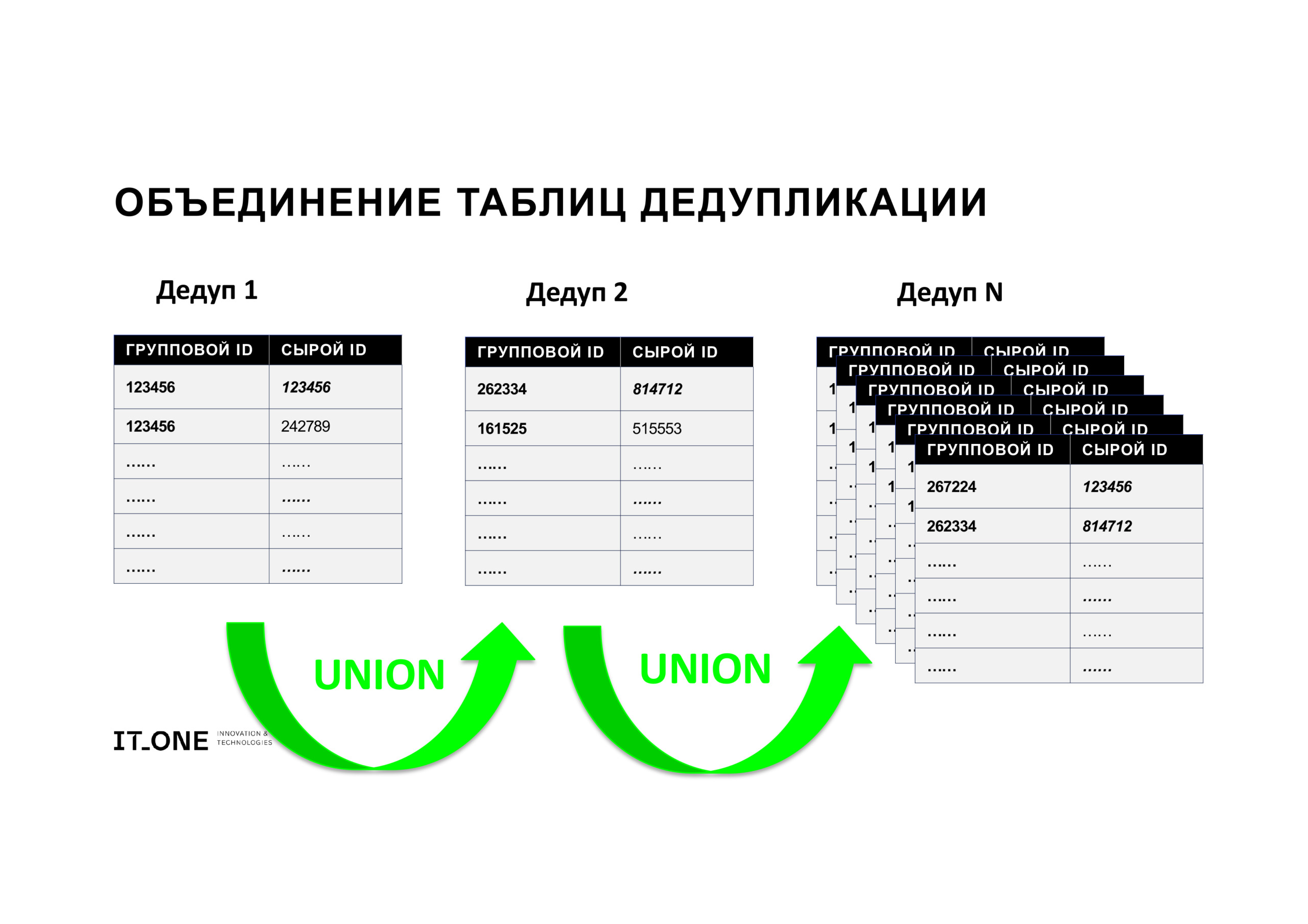
Чтобы объединить имеющиеся ребра графа в группы, мы используем инструмент Apache Spark GraphX – Connected Components. GraphX – компонент Apache Spark для манипулирования и анализа структурированных данных в виде графов.
GraphX предоставляет API для вычисления графов, которое включает в себя традиционные графовые операции и операции над RDD. ConnectedComponents – это алгоритм, используемый для определения связанных компонентов в графе.
Связная компонента графа – это подмножество графа, в котором каждая пара вершин соединена путем, и которое не связано с остальной частью графа. Загрузив в систему таблицу с ребрами, на выходе мы получаем связанные графы, в которых каждому сырому ID присваивается минимальный ID, с которым субъект появлялся в системе.

Пример: определение вершин в графах.
Заключение
Процесс дедупликации следует проводить комплексно, учитывая бизнес-логику и консультируясь с конечными потребителями. При этом недодедупликация всегда лучше, чем передедупликация, даже если при дедупликации записи не удаляются. Всегда проще додедуплицировать записи, чем «откатить» проведенную передедупликацию.
Важна итеративная очистка, визуальная проверка данных, встраивание метрик и сравнение текущих результатов дедупликации с предыдущими. Например, если раньше мы ежемесячно обрабатывали в среднем полмиллиона записей, а сейчас их количество другое, – вероятно, произошли изменения в источниках данных, в механизме их предоставления или в наших алгоритмах дедупликации.

3К открытий6К показов

Рабочий подход к тестированию трансформации данных в ETL-процессах. На примере Python-проекта с pytest, allure и psycopg2 демонстрируется, как автоматизировать создание и наполнение таблиц, хранить схемы и данные, а затем сравнивать результат.

Даниил Динько, тимлид в компании-лидере в международном кибербезе и эксперт Эйч Навыки, собрал стартер-паки для Go-разработчика каждого уровня.

Как эффективно защитить pet-проект: управление секретами, логирование, бэкапы, локальные туннели и другие базовые правила безопасности

Зачем разработчику знать SQL, если есть NoSQL. Показываем основные отличия SQL и NoSQL. Рассматриваем пошаговую инструкцию и важные особенности ✔ Tproger