


Почему нейросети забывают старое, когда учатся новому? Как ученые пытаются это решить
О катастрофическом забывании: почему модели теряют навыки и что делать разработчикам

Эта статья адаптация англоязычного материала The Amnesia Problem: Why Neural Networks Can’t Learn Like Humans (rewire.it)
Что такое катастрофическое забывание
Представьте пианиста, который десять лет играл классику, а потом решил освоить джаз. На первом уроке джаза он вдруг полностью забывает Баха, а уже через неделю больше не помнит простейших гамм.
В машинном обучении это явление называют катастрофическим забыванием. Нейросеть, когда обучается на новой задаче, стирает знания о старой, и это не сбой конкретной архитектуры или фреймворка — это особенность самого способа обучения нейросетей.
Как выглядит забывание на практике
Возьмём простую ситуацию. Мы обучаем нейросеть распознавать собак (Задача A) — она показывает 95% точности, потом даём ей новую задачу — классифицировать котов (Задача B). После обучения по новой выборке сеть отлично отличает котов (92%), но если снова проверить её на собаках — точность падает с 95% (как было изначально на собаках) до 10%, то есть до уровня случайного угадывания.
Это не потому, что у сети не хватает параметров. Исследования показывают: ёмкости модели достаточно, чтобы хранить знания по обеим задачам. Проблема в другом — в том, как работает градиентный спуск.
Почему обучение стирает старое
Градиентный спуск видит только текущие ошибки и стремится минимизировать функцию потерь именно для новой задачи. То, что было важно для старой, в этот момент не учитывается.
Во время обучения сеть перемещается по пространству весов, чтобы найти минимум потерь. Для Задачи A она находит подходящее устойчивое решение. Когда приходит Задача B, алгоритм начинает с тех же весов, но дальше шаг за шагом уводит их в новое направление под новую цель. Многие параметры для старой задачи при этом переписываются.
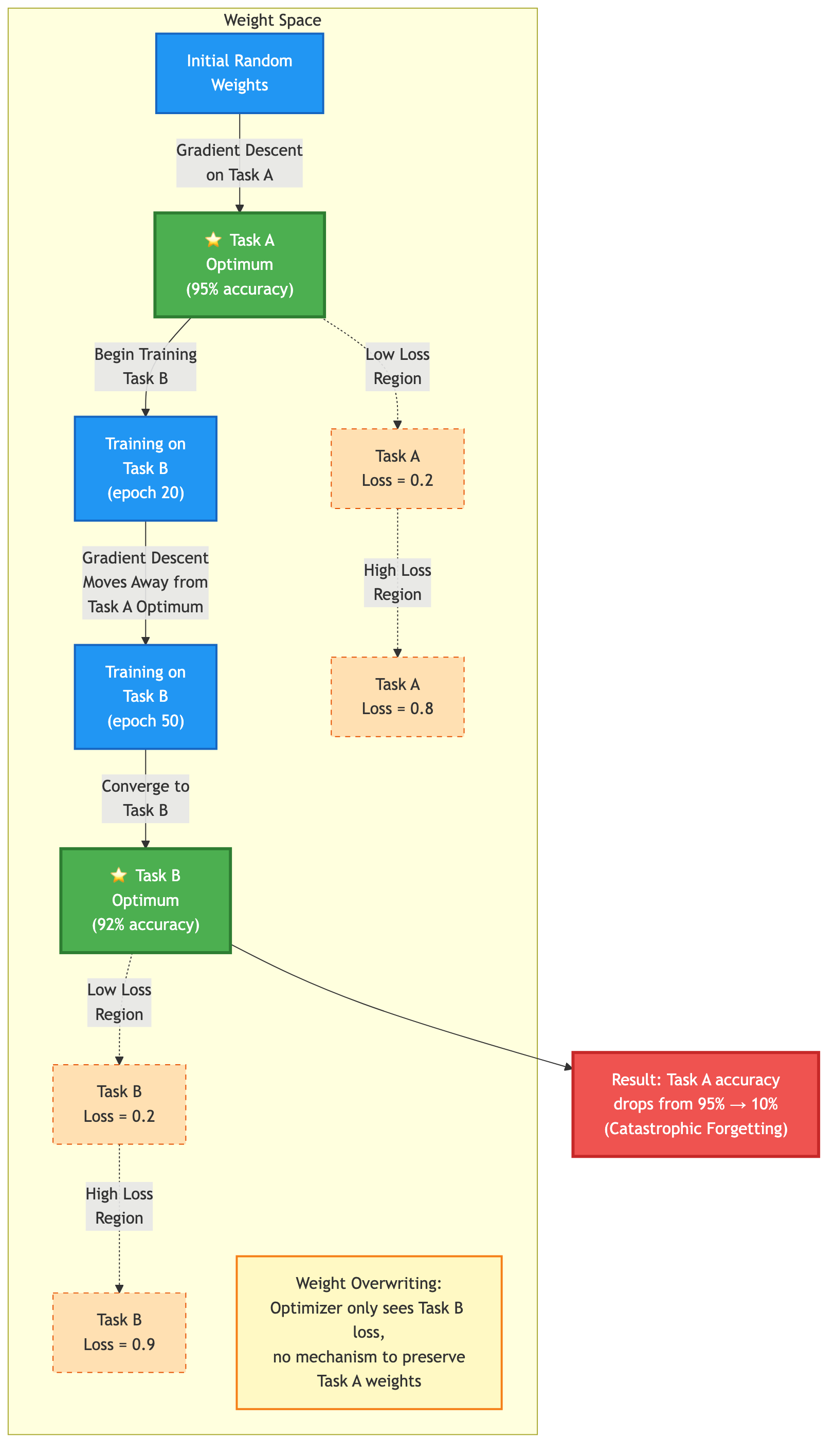
В итоге то, что помогало распознавать собак, оказывается теперь непригодным для собак, а подходит только для котов. Алгоритм не учитывает, как теперь работает старая задача — он смотрит только на текущие задачи.
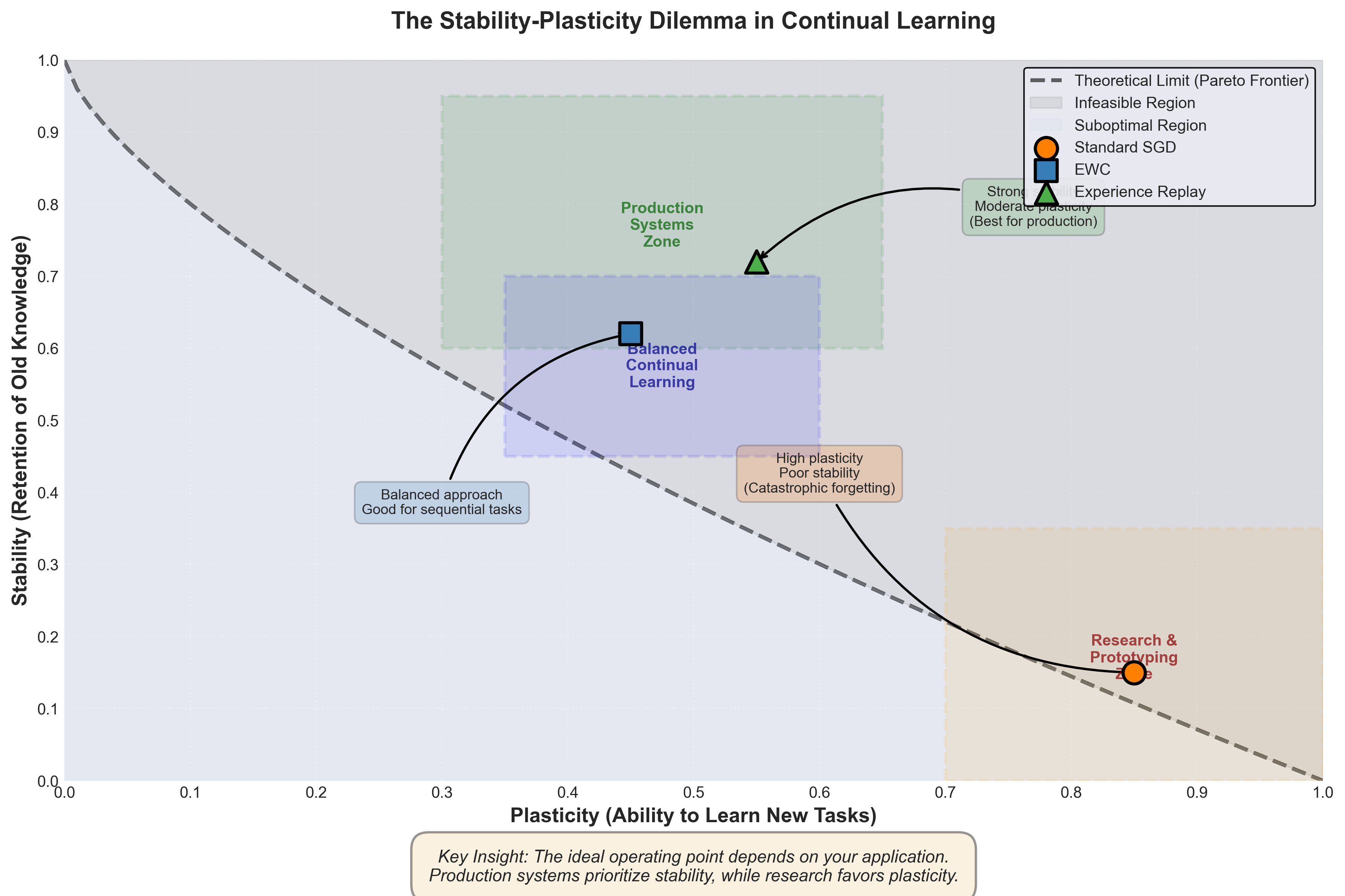
Дилемма стабильности и пластичности
Чтобы понять, почему катастрофическое забывание вообще возникает, нужно вспомнить о главной проблеме — дилемме стабильности и пластичности. Это правило работает не только для нейросетей, но и для любых систем, которые учатся последовательно.
Пластичность — это способность учиться новому. Когда сеть встречает новую задачу, ей нужно быть гибкой, менять веса и быстро подстраиваться под новые данные.
Стабильность — противоположное качество: умение сохранять старые знания, не давая им разрушиться при каждом обновлении весов.
Проблема в том, что нельзя увеличить и стабильность, и пластичность одновременно. Если сеть слишком гибкая — она хорошо впитывает новое, но моментально забывает старое. Если наоборот — слишком стабильная, то перестаёт учиться и застывает на месте.
Это ограничение встроено в саму природу обучения через распределённые параметры. Каждый нейрон обновляет свои веса локально, исходя только из текущей ошибки. И те же механизмы, что помогают сети адаптироваться к новому, одновременно приводят к тому, что старое знание постепенно стирается.
Потеря геометрии ландшафта: почему архитектура нужна
Чтобы понять, почему одни нейросети подвержены катастрофическому забыванию сильнее других, нужно разобраться в процессе оптимизации. Во время обучения модель корректирует миллионы параметров, минимизируя функцию потерь. Этот процесс можно визуализировать как перемещение по многомерному ландшафту потерь (loss landscape), где каждая точка представляет уникальную конфигурацию весов.
Ландшафт потерь состоит из областей с разными значениями функции потерь:
- Локальные минимумы — области с низким значением потерь, где модель показывает хорошее качество
- Высокие области — конфигурации параметров с большой ошибкой
При обучении на первой задаче (например, классификация собак) модель сходится к одному минимуму. При переходе ко второй задаче (классификация кошек) градиентный спуск направляет модель к совершенно другому минимуму, который может быть далеко от первого. Это приводит к перезаписи весов и потере знаний из предыдущей задачи.
Критический фактор — геометрия этих минимумов. В одних архитектурах минимумы узкие и острые (sharp minima) — небольшое возмущение параметров резко увеличивает функцию потерь. В других минимумы широкие и плоские (flat minima) — модель более устойчива к изменению весов.
Исследования показали, что архитектуры с skip connections, например ResNet, как раз формируют такие плоские минимумы — это делает их более устойчивыми к изменению весов, даже когда модель дообучается на новой задаче, её настройки остаются близки к старым, и забывание происходит не так сильно.
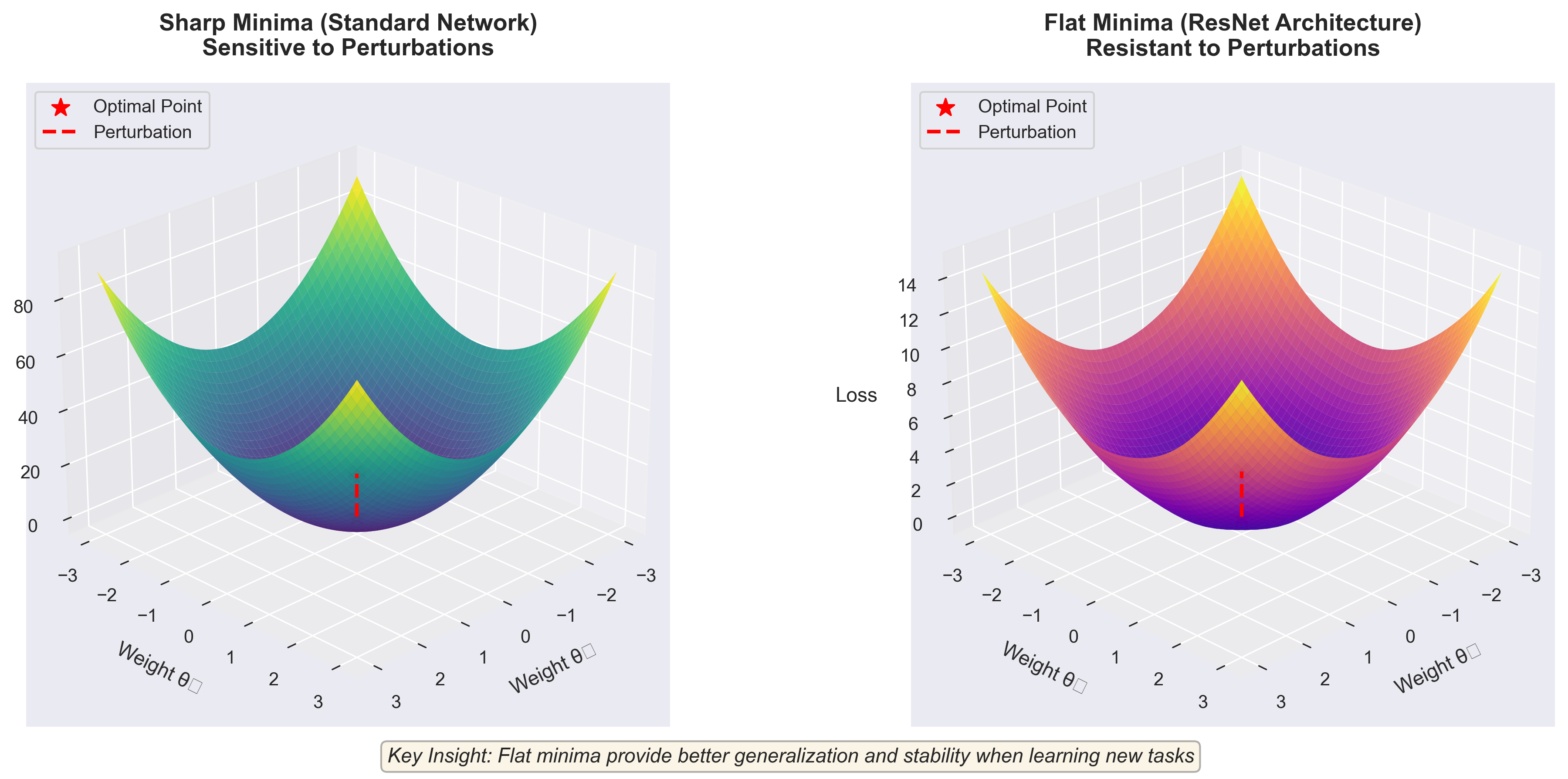
Это объясняет, почему современные архитектуры забывают меньше старых. У них принципиально другое устройство процесса обучения — более стабильное, которое труднее случайно сломать при добавлении новых задач.
Как нейроны конкурируют друг с другом
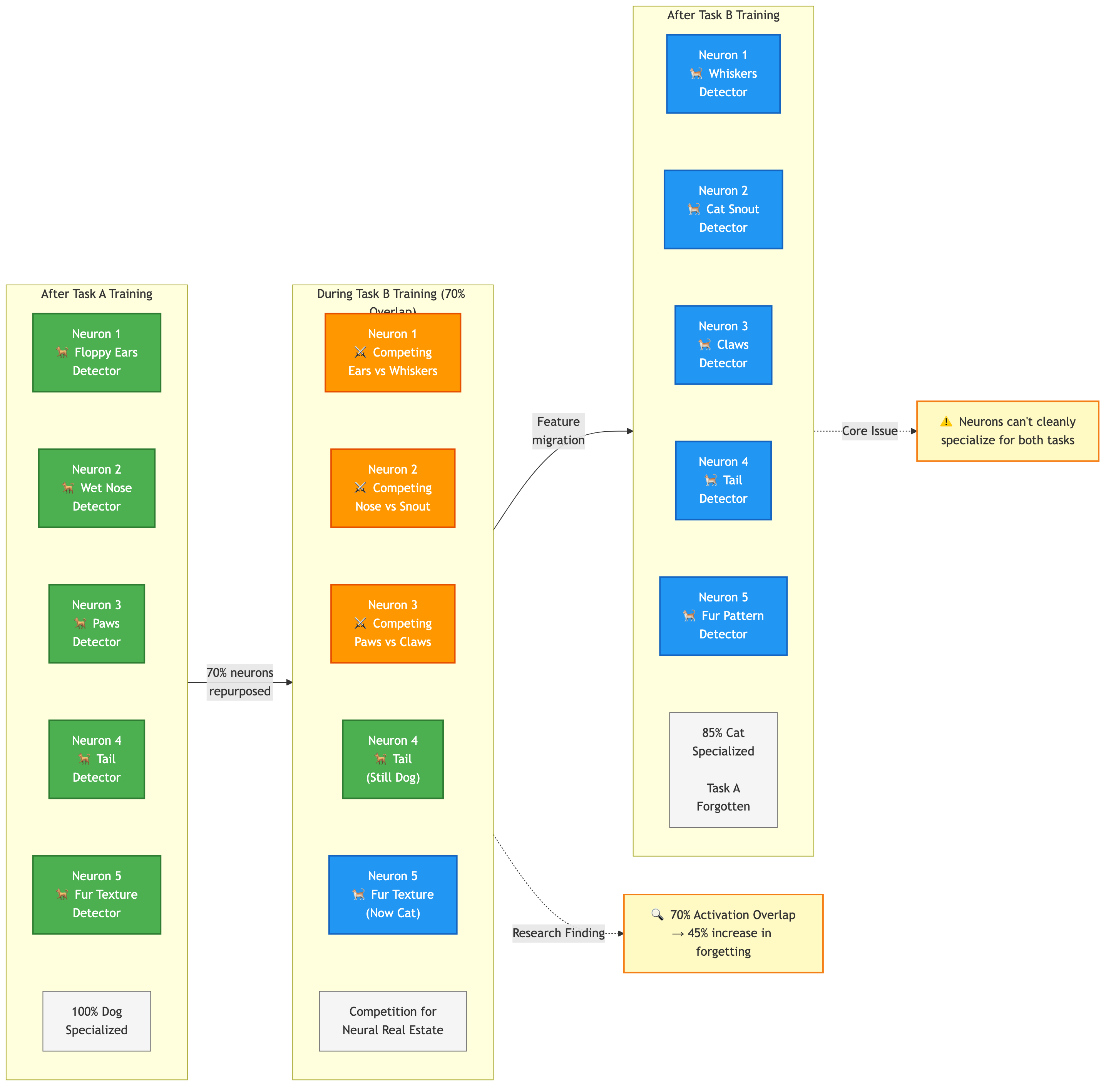
Внутри нейросети каждый нейрон отвечает за определённые признаки, когда сеть обучается распознавать собак, одни нейроны начинают реагировать на уши, другие — на форму морды или лапы. Это и есть специализация — каждый нейрон берёт на себя свою часть работы.
Но когда мы начинаем дообучать ту же сеть на новой задаче, например на распознавании котов, часть этих же нейронов переиспользуется. Теперь они начинают подстраиваться под морды котов, их уши и хвосты. Постепенно сеть перенастраивает внутренние связи так, чтобы быть полезной для новой задачи, и старые навыки теряются.
Нейронам не могут одинаково хорошо специализироваться и на собаках, и на котах. Одни и те же группы нейронов работают на разные задачи, из‑за чего старая специализация стирается.
Исследования показывают, что если две задачи активируют одну и ту же часть нейронов, эффект забывания становится сильнее — до 40–50%. Получается, сеть забывает не из‑за нехватки параметров, а потому что внутренние ресурсы перекрываются. Она просто переучивает старые нейроны на новую роль и не создает новые.
Почему повторное обучение не спасает
Можно подумать, что проблему легко решить: просто чередовать старую и новую задачу. Сначала немного обучаем сеть на собаках, потом на котах, потом снова на собаках — и так по кругу. Это действительно помогает, но не решает проблему полностью.
Когда сеть обучается на новой задаче, обновление весов всё равно изменяет параметры, которые нужны для старой. Даже если повторно возвращать старые данные, оптимизатор начнёт переписывать часть старых знаний. Эффект забывания уменьшается, но не исчезает.
Кроме того, такое обучение становится дорого по ресурсам. Нужно хранить старые выборки, чередовать их с новыми, настраивать порядок подачи данных. Это не подходит для потоковых систем, где задачи появляются одна за другой, или для областей с ограничениями по хранению данных, например, банковская сфера или медицина.
Как разработчики пытаются найти баланс
На практике дилемма стабильности и пластичности проявляется в выборе параметров обучения. Например, в методе регуляризации разработчики могут настроить, насколько сильно защищать старые данные от изменения.
Если усилить регуляризацию — старые знания лучше сохранятся, но сеть хуже будет учиться новому. Если ослабить — сеть быстро впитает новую задачу, но забудет старую. Получается постоянный выбор: жертвовать старым или новым.
Любая точка на этом спектре — компромисс. Нет такого параметра, который позволит и запомнить всё прошлое, и учиться на будущем — на данный момент, это главное ограничение.
Хуже того, что даже если удаётся сохранить старые знания, появляется другая проблема. После обучения на множестве последовательных задач сеть теряет саму способность учиться. Её нейроны либо перестают реагировать на новые данные, либо повторяют одну и ту же реакцию.
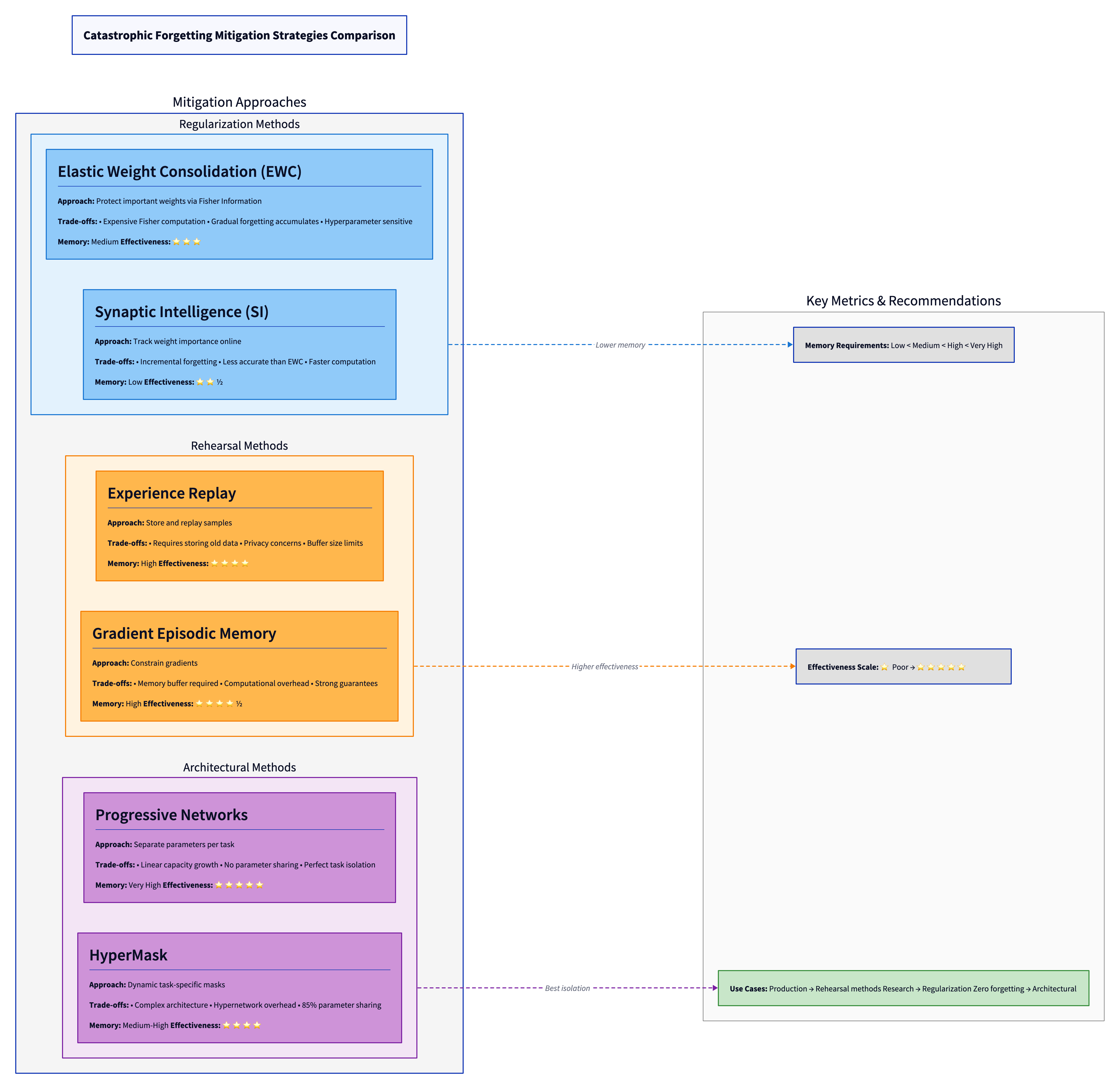
Методы борьбы с забыванием
Исследователи разработали несколько способов снизить катастрофическое забывание. Но ни один из них не решает проблему полностью — у каждого есть свои ограничения.
Elastic Weight Consolidation (EWC) — защита важных весов
Это метод, который старается определить, какие параметры критичны для предыдущей задачи, и защищает их от сильных изменений. Когда сеть дообучается на новой задаче, алгоритм смотрит: если какой-то параметр был очень важен для собак, его не надо сильно менять при обучении на котах.
Звучит хорошо, но есть минусы. Вычислять важность параметров дорого по ресурсам, и метод всё равно не гарантирует полного сохранения знаний.
Rehearsal — повторение старых примеров
Этот способ работает просто: сеть хранит в памяти часть примеров из старой задачи и время от времени подмешивает их при обучении на новой. Это снижает забывание, но требует хранить старые данные, что может быть невозможно из-за ограничений по памяти или приватности.
Архитектурные подходы — разные задачи, разные параметры
Самый радикальный способ — выделить разные части сети под разные задачи. Тогда обучение одной задачи вообще не трогает другую, потому что используются разные параметры. Забывания нет, но сеть становится огромной — чем больше задач, тем больше параметров.
HyperMask (2024 год) использует специальные маски, которые позволяют переиспользовать до 85% параметров между задачами, сохраняя изоляцию.
Современные гибридные методы
CURLoRA — метод, который комбинирует математическое разложение матриц с ограничениями при дообучении. Он показывает хорошие результаты на больших языковых моделях: например, для модели Mistral 7B удалось снизить ухудшение с 53 896 до 5,44 по метрике perplexity. Но такие методы заточены под конкретные модели и не всегда переносятся на другие архитектуры.
Пример на практике
Простой эксперимент на PyTorch показывает, как это выглядит. Сеть обучается на двух задачах: сначала на A, потом на B. Полный код доступен в оригинале в файле catastrophic-forgetting-demo.py.
Без защиты: точность на старой задаче падает с 93,6% до 53,6% — потеря 40%.
С методом EWC: точность падает с 91,8% до 74,4% — потеря 17,4%, что на 52% лучше. Но на новой задаче EWC тормозит обучение: вместо 95,6% получается только 73,8%.
Здесь видно главное: в каждом методе нужно выбирать чем жертвовать. Либо памятью, либо вычислением, либо производительностью на новой задаче. Вы не решаете проблему катастрофического забывания полностью, вы только управляете ею.
Как катастрофическое забывание проявляется в продакшене
В реальных системах катастрофическое забывание выглядит не как внезапный сбой, а как постепенное ухудшение работы — дрейф модели. Модель, обученная на прошлых данных, уверенно работает сегодня, но через пару месяцев начинает ошибаться. Это и есть то же самое забывание, только в замедленном виде.
Исследования показывают, что 75% компаний сталкиваются с падением качества моделей без постоянного мониторинга.
Если модель полгода не обновлять, ошибки на новых данных вырастают примерно на треть. А если просто дообучать её на новых данных, часто улучшается работа на свежих примерах, но при этом падает точность на старых — классическая форма забывания.
В итоге разработчику приходится выбирать из двух зол: либо держать несколько моделей под разные типы данных, либо мириться с тем, что качество со временем падает. Некоторые компании даже полностью переобучают модели каждый месяц, чтобы вернуть стабильность, хотя это дорого.
Понимание механизма забывания помогает объяснить, почему идея «просто дообучить модель на новых данных» не работает. Это также оправдывает сложные и затратные пайплайны мониторинга, проверки метрик и периодического переобучения.
Например, в рекомендательных системах забывание снижает точность старых сегментов пользователей на 20–25%. В медицинском AI модели, обновленные на новых пациентах, теряют около 18% точности на старых группах — и это уже риск для качества диагностики.
Для инженеров это значит одно: катастрофическое забывание — не теоретическая проблема. Это реальный фактор, который нужно учитывать, если вы строите систему, которая учится на живых данных.
Новые подходы: не бороться, а обойти проблему
Исследователи всё больше приходят к выводу, что катастрофическое забывание нельзя вылечить напрямую. Вместо этого стоит менять сам способ, как модели обучаются и обновляются.
Сегодня развиваются три основных направления:
1. Непрерывное предобучение
Модель постоянно обновляет свои знания, когда появляются новые данные, но делает это аккуратно — чередуя новую информацию со старой из кеша. Такой подход сохраняет примерно 90–95% исходных способностей модели, при этом добавляя свежие знания.
2. Непрерывное дообучение (fine-tuning)
Здесь используется идея модульности: новая задача обучается поверх базовой модели, но сама база остаётся “замороженной”. Получается, что каждая дополнительная функция подключается как надстройка, не ломая основную логику. Это похоже на плагины, где каждая новая задача — отдельный модуль, не влияющий на предыдущие.
3. Множество моделей вместо одной
Третий подход — вообще отказаться от идеи универсальной модели, которая знает всё. Вместо этого создают ансамбли: набор специализированных моделей, которые работают вместе. Каждая отвечает за свой участок задачи, и таким образом проблема забывания просто не возникает — разные знания не мешают друг другу.
Все три подхода не устраняют забывание напрямую, но делают его несущественным. По факту вам просто нужны разные модели под разные задачи.
Если вы никогда не будете обучать одну и ту же модель сначала на задаче A, а затем на задаче B, проблема забывания исчезает.
Это немного философское наблюдение: не пытаться побороть ограничение, а выстраивать архитектуру вокруг него.
Вопросы, которые остаются
Существует ли математический предел, ниже которого забывание уже невозможно снизить?
Некоторые исследования указывают на такие пределы, но точные границы пока не найдены.
Как выбирать баланс между стабильностью и пластичностью?
Сейчас это делается вручную через подбор параметров методом проб и ошибок. Но нет чёткого понимания, как именно рассчитать оптимальный баланс для конкретной задачи.
Влияет ли размер модели на забывание?
Практика показывает, что большие модели забывают меньше, но почему это происходит и как именно зависит сила забывания от размера — неясно.
Можем ли мы достичь теоретического максимума?
Даже если знать предел, можно ли разработать процедуру обучения, которая его достигает? Сейчас методы работают примерно на 70% от теоретически возможного оптимума.
Как ведут себя большие модели?
Ранние данные показывают, что большие модели забывают данные по-другому, чем маленькие сети. Но системного описания этих различий пока нет.
Эти вопросы нужны, потому что от них зависят архитектурные решения. Если бы мы могли точно рассчитать границу забывания, можно было бы строить системы с запасом прочности. Если бы умели находить оптимальный баланс, не пришлось бы подбирать параметры вручную.
Выводы, которые можем сделать
Катастрофическое забывание — не техническая ошибка, которую можно исправить очередным алгоритмом. Это фундамент того, как работают распределённые системы обучения.
Дилемма стабильности и пластичности встроена в саму природу нейросетей. Каждый нейрон обновляет свои веса на основе текущей задачи, и механизма для сохранения прошлого просто нет. То же свойство, что позволяет сети учиться, одновременно делает её уязвимой перед забыванием.
Это означает, что правильная постановка задачи — не «как победить забывание», а «как управлять им осознанно». В одних случаях важна стабильность — сохранить старые знания любой ценой. В других важна гибкость — быстро учиться новому. Большинство реальных систем требует баланса.
Для разработчиков, которые работают с продакшен ML, это значит следующее: последовательное обучение сложнее одноразового обучения в принципе, и никакой алгоритм этого не изменит. Системы, которые хорошо справляются с меняющимися данными, не пытаются впихнуть всё в одну модель. Они признают ограничение и строятся вокруг него — с мониторингом, переобучением, специализированными моделями или ансамблями.








![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)


