


Как распознавать лица с помощью библиотеки FAISS
Сейчас технология распознавания лиц — одна из важнейших в самых разных областях. В статье расскажу о фреймворках и библиотеках, предназначенных именно для этого.
541 открытий6К показов
В эпоху тотальной цифровизации и автоматизации задача распознавания лиц (face detection) стала одной из наиболее важных и актуальных задач машинного обучения, имеющей множество практических применений:
- Поиск преступника по записям с уличных камер;
- Сигнал о том, что на частную территорию зашёл незнакомый человек;
- Упрощение проверок на входе в организацию с пропускным режимом;
- Оплата услуг с помощью FaceID и многое другое.
Одной из проблем, возникающих при решении задачи face detection, является то, что лицо текущего человека нужно сравнивать со слишком большим количеством других лиц, что в случае неоптимальной реализации требует огромного количества машинных ресурсов.
Решению этой проблемы и посвящена статья.
Постановка задачи
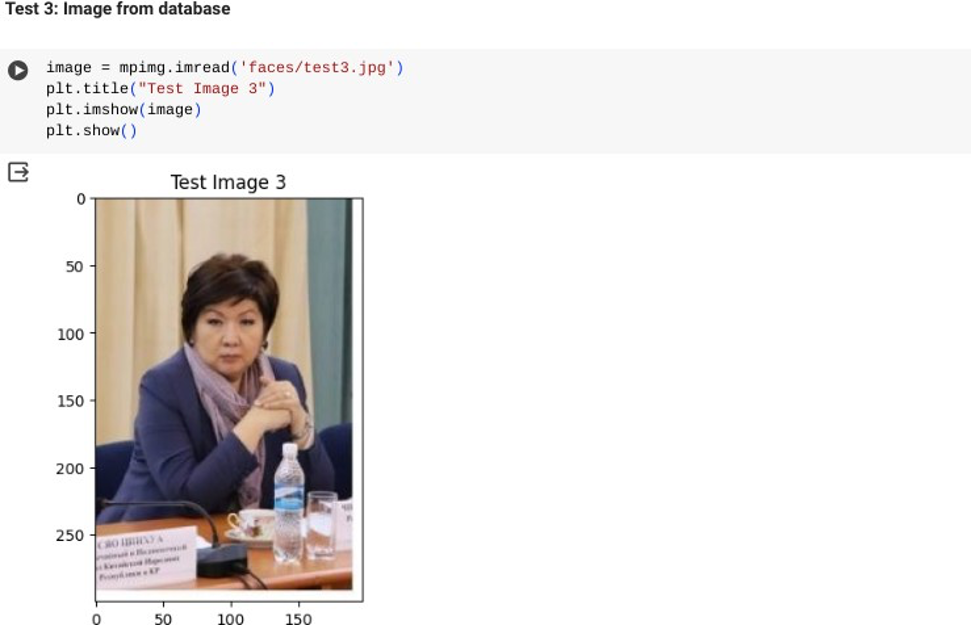
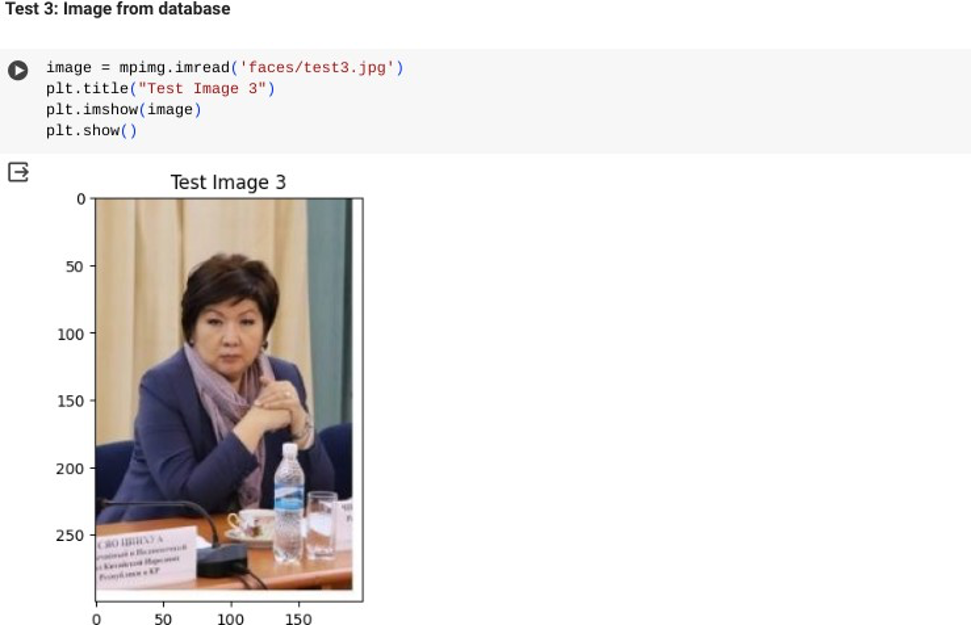
Дана база фотографий, каждая из которых содержит лица одного или более человек (около 20 тысяч фотографий; пример приведён на рис. 1). На вход поступает новая фотография. Необходимо:
- Определить, является ли эта новая фотография дубликатом одной из фотографий, находящихся в базе, и если является — вывести информацию о совпадающей фотографии;
- Если не является, то вывести одну или несколько наиболее похожих на неё фотографий из базы, а затем добавить эту новую фотографию в базу.

Фотографии считаются похожими, если похожи лица изображённых на них людей. На обработку каждой новой фотографии должно тратиться не более нескольких секунд машинного времени.
Этапы решения поставленной задачи.
Оптимизация хранения фотографий в базе. Выбор метода распознавания лиц.
Выбор метода поиска наиболее похожих лиц. Построение общего пайплайна.
1. Оптимизация хранения фотографий в базе.
Поскольку фотография хорошего качества может иметь размер вплоть до 10 мегабайт, 20 тысяч подобных фотографий могут занять до 200 гигабайт, и тогда даже попиксельное сравнение новой фотографии со всеми имеющимися в базе с целью поиска дубликата будет занимать как минимум несколько минут (не говоря уже о поиске похожих). Кроме того, разные фотографии имеют разную длину и ширину, что неудобно для сравнения.
Таким образом, необходимо каждой фотографии (а точнее — каждому лицу на фотографии) поставить в соответствие вектор чисел фиксированной длины. Эта длина не должна быть слишком маленькой (иначе большая часть информации на фотографии будет потеряна), но и не должна быть слишком большой (иначе сравнивать будет по-прежнему долго).
2. Выбор метода распознавания лиц
К счастью, существует достаточно много алгоритмов face detection, которые делают в точности то, что нам нужно:
- Определяют, где именно на фотографии находятся лица;
- Для каждого из лиц возвращают вектор фичей, причём все эти векторы одинаковой длины.
Одной из лучших современных библиотек для распознавания лиц является InsightFace, которая получила много наград на соревнованиях по face detection. Поскольку эта библиотека является свободной и реализована на языке Python, было принято решение использовать именно её.
Реализация этой библиотеки по умолчанию возвращает 512 параметров для каждого лица, что полностью удовлетворяет требованиям, поставленным в предыдущем пункте: хранение такого количества параметров для 20 тысяч фотографий займёт около 200 мегабайт, что в тысячу раз меньше, чем при хранении самих фотографий. Файл такого размера легко помещается в оперативную память и может быть считан полностью за 1-2 секунды.
3. Выбор метода поиска наиболее похожих лиц
Тем не менее остаётся проблема с производительностью при поиске похожих, но не совпадающих лиц. Чтобы найти наиболее похожую фотографию (а тем более — несколько наиболее похожих), необходимо сравнить вектор фичей каждого из лиц на новой фотографии со всеми векторами из базы (на рис. 2 нужно сравнить каждый «зелёный» вектор с каждым «красным»):

При этом для каждой пары сравниваемых векторов необходимо посчитать метрику близости (например, евклидово или косинусное расстояние), что также является достаточно затратной операцией.
Таким образом, хотя при 20 тысячах фотографий, имея достаточно быстрый компьютер, мы сможем выполнить все сравнения за несколько секунд, такое решение будет плохо масштабируемым: при 200 тысячах фотографий нам придётся выполнять сравнение уже в 10 раз дольше, а при 1 миллионе — дольше в 50 раз, что уже неприемлемо.
Кроме того, нам нужно найти лишь одну или несколько наиболее похожих фотографий, а не отранжировать их все по убыванию похожести, поэтому бóльшая часть вычислений будет лишней, так что должен существовать способ делать это более оптимально.
И действительно — существуют библиотеки эффективного поиска похожих векторов. Одной из наиболее популярных и простых в использовании является библиотека FAISS (Facebook AI Similarity Search, принадлежит компании Meta, запрещенной на территории РФ). Её суть заключается в создании индекса (оптимизированной таблицы) из всех имеющихся векторов, а затем приближённого поиска в ней нового вектора.
Хотя библиотека scann от компании Google работает в 2-3 раза быстрее, она требует намного больше предварительных настроек, так что её использование станет оправданным лишь при существенном увеличении датасета. Поэтому в данном случае выбор был сделан в сторону FAISS.
4. Построение общего пайплайна
При постановке задачи нам была дана база с фотографиями, поэтому итоговая реализация алгоритма должна содержать следующие шаги:
- Определение лиц на фотографиях и получение их фичей;
- Конвертация фотографий из базы в таблицу с векторами фичей;
- Построение индекса и нахождение похожих фотографий;
- Добавление новой фотографии в базу.
Приведём примерную реализацию каждого из этих пунктов на языке Python с учётом того, что база фотографий представляет собой папку с файлами.
1) Определение лиц на фотографиях и получение их фичей. Этот шаг полностью основан на алгоритме FaceAnalysis библиотеки insightface, при этом все фотографии предварительно преобразуются в матрицы размера 640 * 640 *3 (то есть квадратные фотографии размера 640 * 640 пикселей в RGB-формате).
Подготовка алгоритма FaceAnalysis:
2) Конвертация фотографий из базы в таблицу с векторами фичей. Теперь нужно применить функцию, приведённую в шаге 1, ко всем фотографиям из заданной папки и записать её в таблицу (в данном случае это будет локальный csv-файл).
Функция получения таблицы с фичами из всех фотографий в папке:
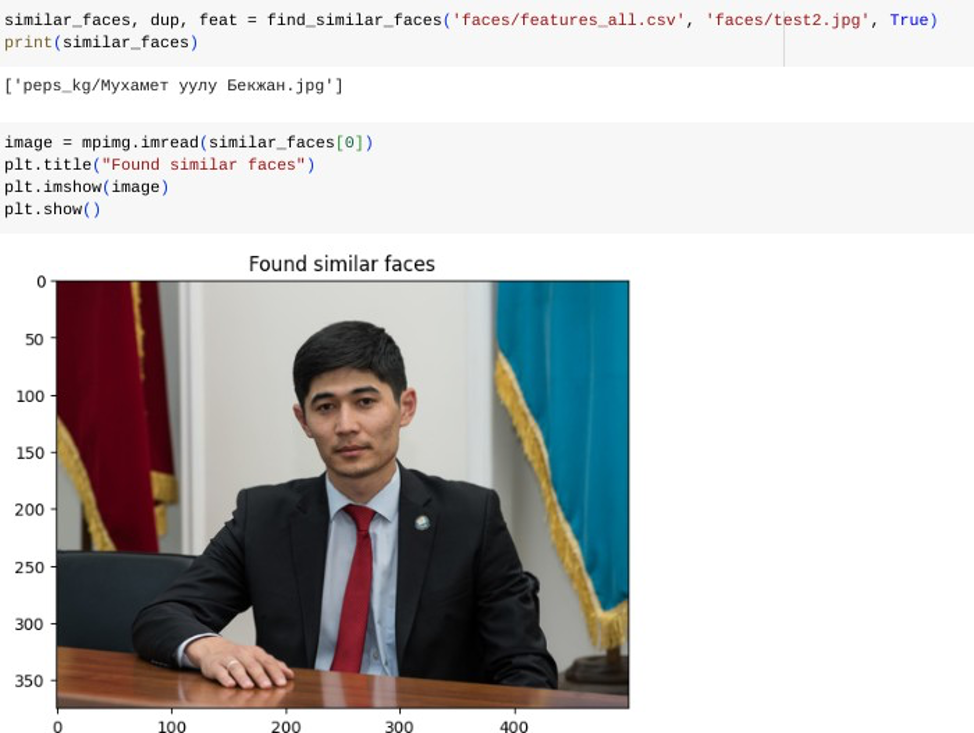
Пример использования функции:
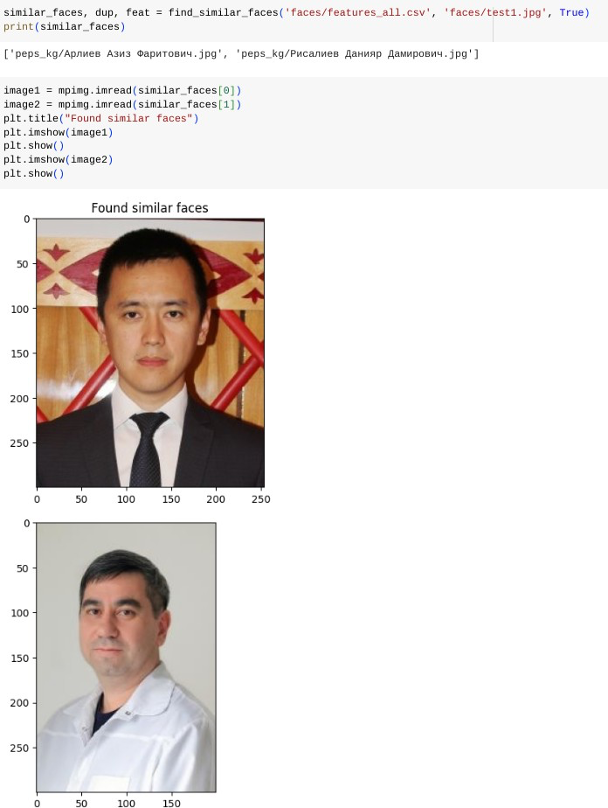
Если найденное минимальное расстояние по фичам оказалось равным нулю, то это значит, что мы нашли дубликат.
3) Добавление новой фотографии в базу. Мы можем выбирать, что делать с фотографией, которая оказалась дубликатом — добавлять в базу или игнорировать. Если же новая фотография не является дубликатом, то мы добавляем её в базу в любом случае.
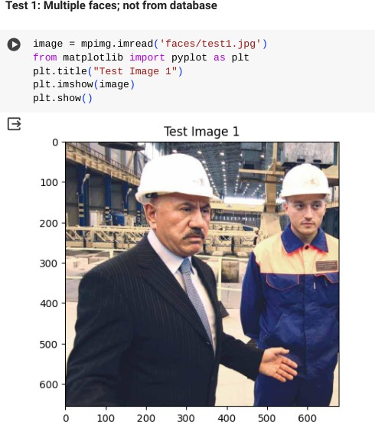
Пример тестирования программы на новой фотографии, содержащей два лица:
Заключение.
Рассмотренное решение удовлетворяет всем требованиям поставленной задачи, однако его реализация имеет пространство для дальнейшей оптимизации, в частности:
- Стоит использовать графический процессор вместо CPU; тогда версию FAISS можно будет заменить на faiss-gpu для быстродействия;
- Локальные таблицы стоит заменить на распределённую базу данных; это значительно улучшит масштабируемость, а добавление новой фотографии не потребует считывания и затем сохранения всего файла;
- Извлечение фичей из фотографий стоит делать не по одной, а батчами по нескольку десятков фотографий - это существенно ускорит первый, самый долгий этап решения задачи.

541 открытий6К показов

Узнайте, какие нейросети помогут быстро создавать видео без опыта и дорогого оборудования. Обзор 12 онлайн-сервисов: от Sora и Runway до «Шедеврума». Сравнение возможностей, языков и тарифов.

Полный список нейросетей для написания эссе. Лучшие сервисы искусственного интеллекта для генерации текстов эссе

Американские ИИ-стартапы переходят на 6-дневку в стиле китайского 996, чтобы не отстать в гонке за лидерство в искусственном интеллекте

Разработчик рассказал, как ИИ ускоряет кодинг, но лишает программистов потока — чувства счастья и вовлеченности в процессе работы