Практикум: машинное обучение в медицине на примере CNTK от Microsoft

На практическом примере использования библиотеки CNTK в медицинских целях показано, как нужно правильно подбирать критерии оптимизации, чтобы получить наибольшую точность модели машинного обучения

В предыдущем гайде мы построили простую сеть и решили задачу построения оператора XOR. Имея понимание того, как работает модель из предыдущей задачи, можно переходить к более сложным задачам. Давайте рассмотрим задачу классификации на примере нескольких абстрактных заболеваний — A, B, C, D, E.
Структура:
- Задача классификации (мультикласс, немного теории);
- Задача диагностики ушных заболеваний;
- Причесывание датасета;
- Конфигурация сети в 2 варианта – SoftMax и Sigmoid;
- Сравнение результатов, приведение ответов сети к полному вероятностному пространству.
Матчасть
Выделяют 3 основных типа задач классификации:
- Бинарная классификация (Есть положительный и отрицательный признак).
- Multiclass classification (Объект носит признаки исключительно одного класса).
- Multilabel classification (Объект имеет признаки нескольких классов одновременно).
Рассмотрим 3 примера на каждый тип задач:
- Определение наличия у человека некой болезни Х. 1 – человек болен, 0 – человек здоров.
- Определение одной болезни среди болезней A, B, C, D, E.
- Определение нескольких болезней среди A, B, C, D, E.
Вопрос теперь в том, в чем будет разница выходного вектора. Для бинарной классификации мы можем использовать скалярные значения. Болен – 1, здоров – 0.
Теперь, когда у нас есть 5 болезней – A, B, C, D, E, – мы должны их представить в каком-то адекватном формате. Есть 2 способа кодирования переменных номинального типа: Label Encoding и One Hot Encoding.
Если использовать Label Encoding, A, B, C, D, E превратятся в 0, 1, 2, 3, 4. Так можно кодировать некоторые переменные, спору нет (особенно переменные ординального типа, отдельно про типы переменных читаем здесь и здесь), но в случае классификации – не стоит. Сеть определенно испытает трудности в процессе обучения, а вы – в интерпретации ответа 3,5.
Поэтому по старинке используем One Hot Encoding и получаем следующее:
A - [1, 0, 0, 0, 0]B - [0, 1, 0, 0, 0]C - [0, 0, 1, 0, 0]D - [0, 0, 0, 1, 0]E - [0, 0, 0, 0, 1]
i-ая компонента вектора указывает на вероятность наличия класса i у объекта. Вернемся к тому же ответу вида 3,5. Его можно понимать как то, что у человека что-то среднее между болезнью D и Е. В случае One Hot Encoding вектор будет иметь следующий вид:[ 0.05, 0.03, 0.1, 0.42, 0.49 ]
От теории к практике
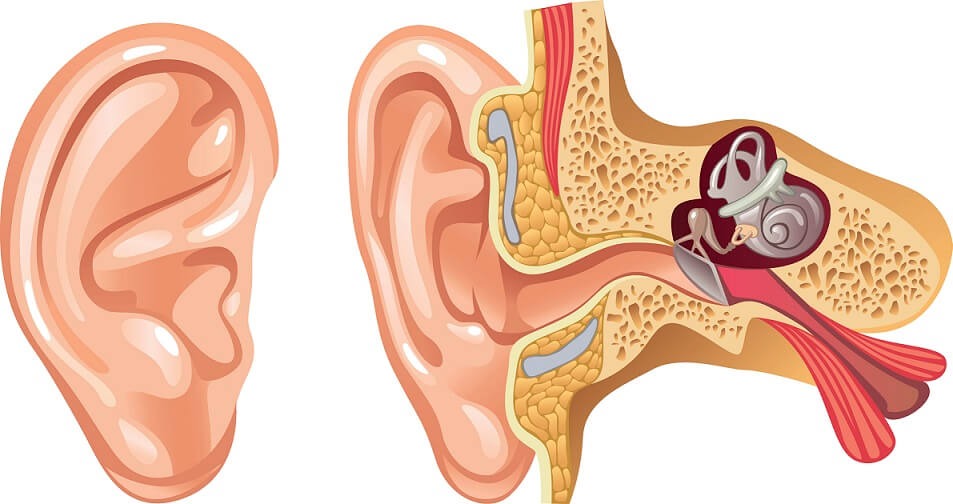
Раз уж разговор зашел о медицине, давайте решим задачу диагностики ушных заболеваний. Здесь будет интересна даже не сама задача, а те подводные камни, с которыми вы наверняка столкнетесь. Итак, датасет можно взять здесь.
Датасет небольшой, тем не менее, у него есть интересные особенности:
- Содержит переменные только номинального/ординального типа;
- Входной вектор имеет довольно большую размерность;
- Неравномерное распределение классов – с этим вы будете сталкиваться каждый день. Также разберемся, как с этим бороться.
Отдельное внимание хотелось бы уделить преобразованиям. Если мы проведем Label Encoding, размерность нашего входного вектора будет 69. Если проведем One Hot Encoding, размерность станет 161. Если проведем по-умному – 101.
Кто-то скажет, что нейронной сети будет достаточно провести Label Encoding – да, это так. Но в таком случае мы усложним ей обучение. Ну что же, поехали. Давайте прочитаем датасет и построим гистограмму распределений классов:
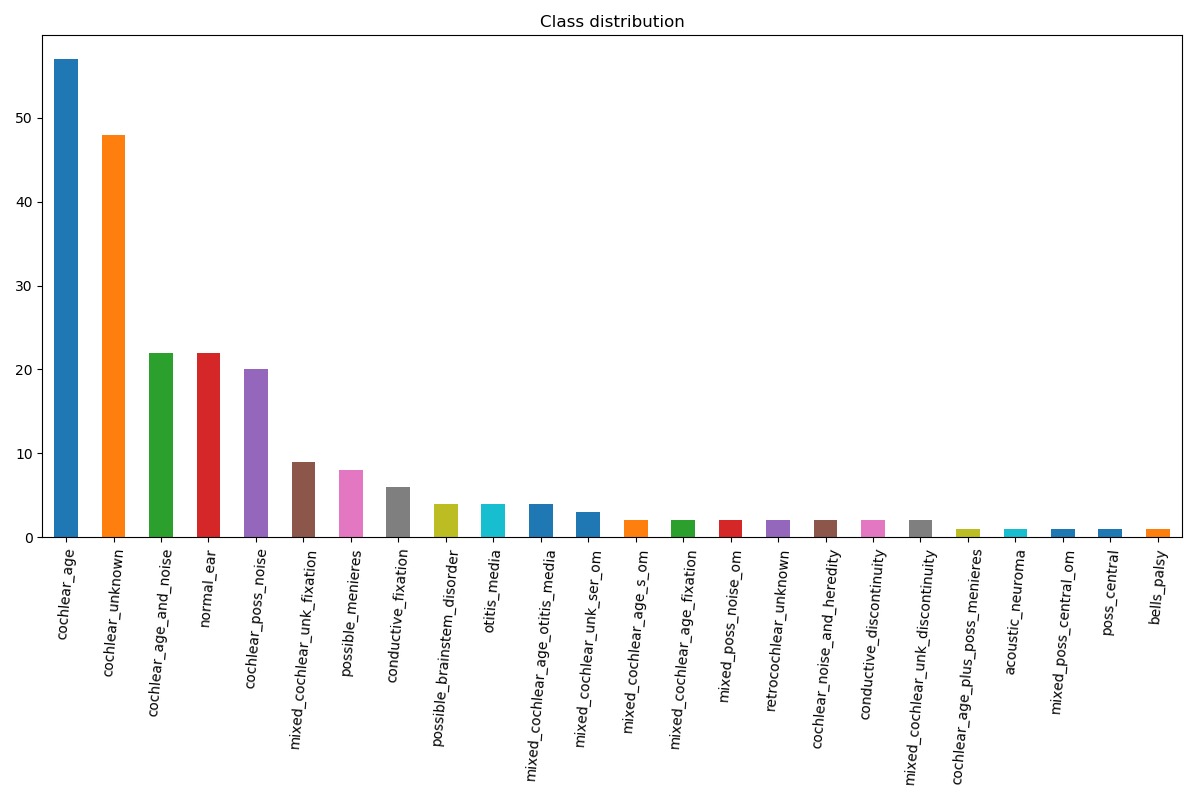
Прежде всего надо посмотреть датасет. Видим, что большинство полей принимает значение t/f. Эти поля будут представлены как 1/0 соответственно. Вопрос, что делать с полями, у которых значения имеют вид mild, moderate, severe, normal, profound.
Хорошим решением будет One Hot Encoding. Выделим список колонок, которые требуют особой обработки, и проведем необходимые преобразования:
Данные представлены в сыром виде, их нужно преобразовать в надлежащий. Вот так будет выглядеть кодировщик:
При помощи класса выше мы преобразуем входные данные, а для выходных данных используем One Hot Encoding. Так, к примеру, класс с названием cochlear_unknown имеет следующий вид:
[ 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
Теперь перейдем к сети. Какую структуру попробуем? Размерность входного вектора немаленькая, первый слой предлагаю взять 100 нейронов. Активация – сигмоид или тангенс, по усмотрению. Второй слой сделаем 150 нейронов. Выходной слой – 24. И давайте попробуем поставить активацию сигмоид на последний слой. Он как раз принимает значения от 0 до 1, т.е. подходит для нашей задачи.
Сниппет сети:
Я взял тангенсы и сигмоид на последнем слое. Сконфигурируем гиперпараметры:
Подготовим и разобьем датасет:
Конфигурируем обучение:
В качестве оптимизатора был взят «адам», как и в прошлый раз, ускорение – 0.9. Но теперь есть одно нововведение. Вторым параметром в Trainer передается пара – loss и error. Оптимизация проходит относительно функции потерь (квадратическая ошибка), error – функция оценки ошибки классификации, ее значение показывает, сколько процентов от учебных данных классифицируется ошибочно на данный момент. Довольно удобная вещь, позволяет наглядно смотреть за процессом обучения при задаче классификации.
Проводим обучение и отображаем значения функции ошибки:

Ошибка нулевая, научились всему (а опытные даже скажут, что произошло переобучение (overfitting), но об этом позже). Посмотрим на точность модели на тестовых данных:
76.9%. Неплохо, учитывая распределение классов, но и не фонтан. Итак, настало время знакомства с перекрестной энтропией. Это несколько иной критерий оптимизации, в двух словах он уменьшает меру неопределенности нашего классификатора. В нейронных сетях он обычно работает в связке с функцией SoftMax.
Для того чтобы вы не терялись, давайте разберем обе функции. Начнем с простого – SoftMax.
Далеко ходить не будем, возьмем определение с Википедии.
Softmax — это обобщение логистической функции для многомерного случая. Функция преобразует вектор z размерности K в вектор той же размерности, где каждая координата полученного вектора представлена вещественным числом в интервале [0,1] и сумма координат равна 1.
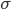{kind=link}
{kind=link}
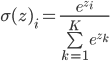
Главное преимущество функции в том, что получив на вход, условно говоря, непонятные значения, функция выдаст вероятности, причем так, что их сумма будет равна 1. Иными словами, это очень хороший выбор, когда объект может быть носителем одного класса.
Для наглядности запустим тот же CNTK и посмотрим, как работает эта функция вживую. Введем какие-то случайные значения для массива x. Условно назовем их попугаями, а потом применим к ним SoftMax:
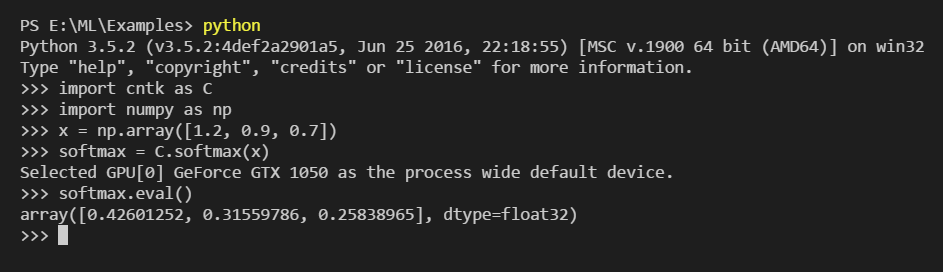
Так и вышло. На входе получили попугаи, на выходе – «причесанные» вероятности.
Теперь сложная часть — энтропия. Формул довольно много и многим они ничего не скажут, поэтому для того чтобы у вас было хотя бы интуитивное понимание, что это такое, начнем с энтропии. Энтропия – это мера неопределенности случайной величины.
Оптимизируя (минимизируя, если быть точным) энтропию случайной величины, которая порождается ответами нашей нейронной сети, мы минимизируем неопределенность (непредсказуемость) классификации объекта. Для приличия все же оставлю формулу:
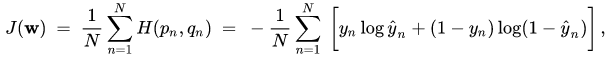
И пока эта математика не вылетела у вас из головы, меняем конфигурацию сети следующим образом:
Активацию из последнего слоя убрали и заменили ее функцией SoftMax.
Меняем критерий оптимизации – квадратическую ошибку заменяем перекрестной энтропией:
Запускаем обучение и смотрим точность: 84.61 процента. Это уже на порядок лучше, нежели 76.9%. Мораль следующая: критерии оптимизации необходимо подбирать в соответствии с поставленной задачей. Если перед вами стоит задача классификации, задумайтесь над применением оптимизации перекрестной энтропии, возможно SoftMax. В случае, когда классов уже 3 и более или они неравномерно распределены, перекрестная энтропия справляется лучше, чем квадратическое отклонение.
Продолжение следует…
Авторы:
Александр Ганджа, CTO DataTrading
Богдан Домненко, Data Scientist DataTrading

5К открытий5К показов

Курс включает в себя разнообразные практические задачи по программированию, которые помогут улучшить ваш уровень программирования на Java.

Поговорили с руководителями инженерных групп направления телекоммуникации КРОК: чем занимаются, о стажёрах и работе в команде.

Обсуждаем с руководителями компаний, лидами и рядовыми айтишниками, нужны ли программисту высшее образование или платные курсы, чтобы устроиться на работу.

Разобрались, как Google развивает решения на основе нейросетей и искусственного интеллекта, и с какими проблемами сталкивается.