Почему мы используем Kafka вместо RabbitMQ: сравнение и преимущества
Делимся особенностями работы Apache Kafka и RabbitMQ, дав точный рецепт, когда и какой брокер стоит использовать.
При построении больших и сложных систем не обойтись без программных брокеров сообщений. Однако часто возникает вопрос, какой из них выбрать для того или иного проекта. Lead architect Группы «Иннотех» Александр Соляр поделился особенностями работы Apache Kafka и RabbitMQ, дав точный рецепт, когда и какой брокер стоит использовать.

Александр Соляр
Lead architect Группы «Иннотех»
В сложной корпоративной системе с гигантскими вычислительными задачами и огромными потоками событий для эффективной работы необходимо организовать распределённую архитектуру и наладить коммуникацию между её компонентами. Многие системы используют различные популярные брокеры сообщений для этих нужд, например, Apache Kafka и RabbitMQ. Разберёмся, чем отличаются эти брокеры сообщений и в каких случаях какой использовать.
Who is Mr. Apache Kafka
Apache Kafka — корпоративный стандарт работы больших высоконагруженных систем с брокером сообщений, особенно уровня business и mission critical с учётом георезервирования. Однако, для того, чтобы разобраться в преимуществах и понять недостатки продукта стоит разобраться в основах работы систем очередей в целом и механизмах их работы.
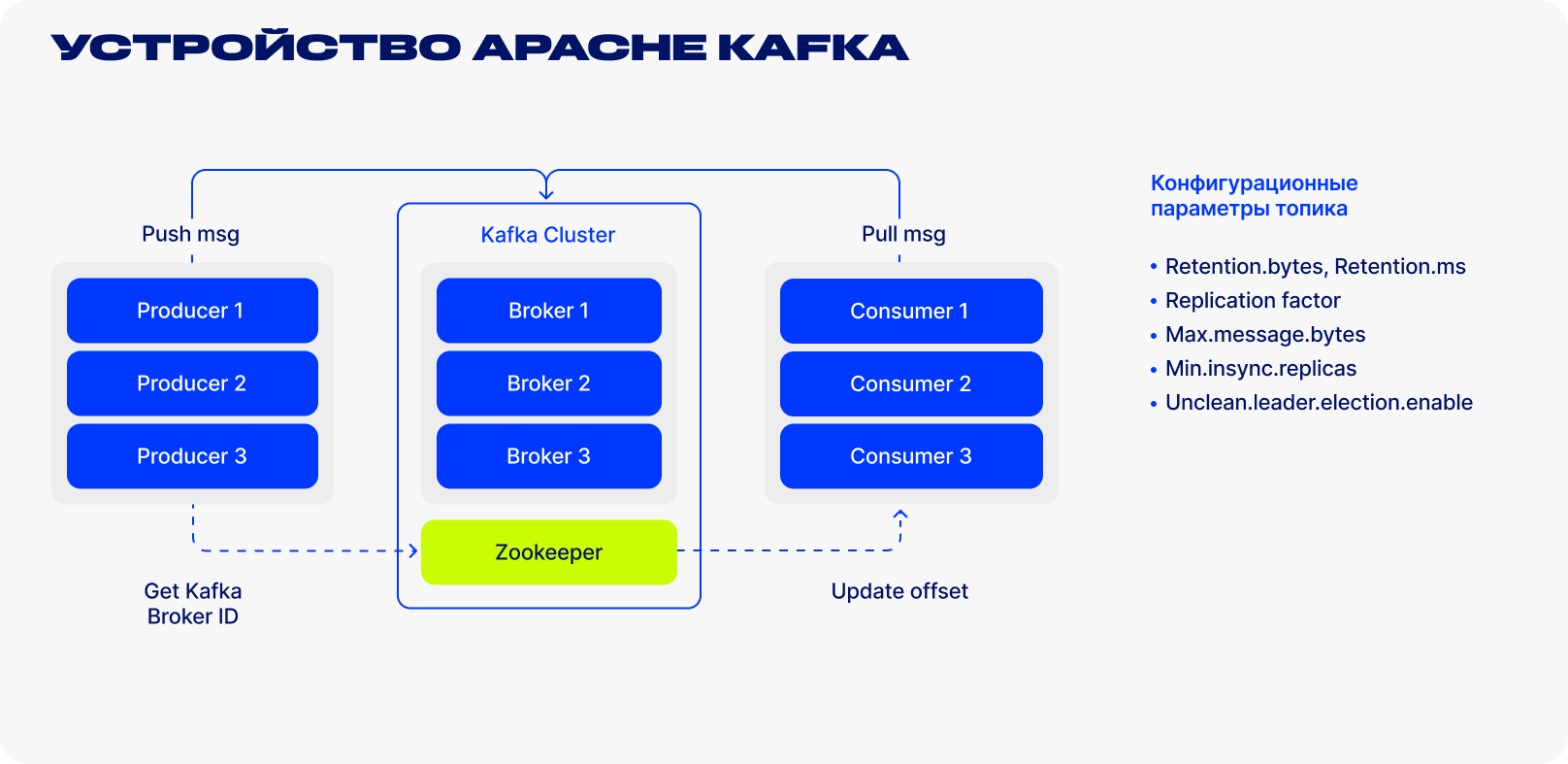
Базовая топология Kafka состоит из producer, consumer, broker и zookeeper.
За хранение ваших данных отвечает брокер (broker). Все данные хранятся в бинарном виде, и брокер мало знает про то, что они из себя представляют и какова их структура.
Каждый логический тип событий обычно находится в своей отдельном топике (topic). Например, событие создания объявления может попадать в топик item.created, а событие его изменения — в item.changed. Топики можно рассматривать как классификаторы событий. На уровне топика можно задать такие конфигурационные параметры, как:
- объём хранимых данных и/или их возраст (retention.bytes, retention.ms);
- фактор избыточности данных (replication factor);
- максимальный размер одного сообщения (max.message.bytes);
- минимальное число согласованных реплик, при котором в топик можно будет записать данные (min.insync.replicas);
- возможность провести failover на несинхронную отстающую реплику с потенциальной потерей данных (unclean.leader.election.enable);
- и ещё много других в соответствующем разделе документации Kafka.
В свою очередь, каждый топик разбивается на одну и более партицию (partition). Именно в партиции в итоге попадают события. Если в кластере более одного брокера, то партиции будут распределены по всем брокерам равномерно (насколько это возможно), что позволит масштабировать нагрузку на запись и чтение в один топик сразу на несколько брокеров.
На диске данные для каждой партиции хранятся в виде файлов сегментов, по умолчанию равных одному гигабайту (контролируется через log.segment.bytes). Важная особенность — удаление данных из партиций (при срабатывании retention) происходит как раз сегментами (нельзя удалить одно событие из партиции, можно удалить только целый сегмент, причём только неактивный).
Zookeeper — элемент выполняет роль хранилища метаданных и координатора. Именно он способен сказать:
- живы ли брокеры — посмотреть на это глазами zookeeper можно через zookeeper-shell командой
ls /brokers/ids; - какой из брокеров является контроллером —
get /controller; - находятся ли партиции в синхронном состоянии со своими репликами —
get /brokers/topics/topic_name/partitions/partition_number/state.
Также именно к zookeeper сперва пойдут producer и consumer, чтобы узнать, на каком брокере какие топики и партиции хранятся. В случаях, когда для топика задан replication factor больше 1, zookeeper укажет, какие партиции являются лидерами — в них будет производиться запись и из них же будет идти чтение. В случае падения брокера именно в zookeeper будет записана информация о новых лидер-партициях
Producer — это чаще всего сервис, осуществляющий непосредственную запись данных в Apache Kafka. Producer выбирает topic, в котором будут храниться его тематические сообщения, и начинает записывать в него информацию. Например, producer’ом может быть сервис объявлений. В таком случае он будет отправлять в тематические топики такие события, как «объявление создано», «объявление обновлено», «объявление удалено» и так далее. Каждое событие при этом представляет собой пару «ключ-значение».
По умолчанию все события распределяются по партициям топика round-robin`ом, если ключ не задан (теряя упорядоченность), и через MurmurHash (ключ), если ключ присутствует (организуется упорядоченность в рамках одной партиции).
Kafka гарантирует порядок событий только в рамках одной партиции. Но на самом деле часто это не является проблемой. Например, можно гарантированно добавлять все изменения одного и того же объявления в одну партицию, сохраняя порядок этих изменений в рамках объявления. Также можно передавать порядковый номер в одном из полей события.
Consumer отвечает за получение данных из Apache Kafka. Если вернуться к примеру выше, consumer’ом может быть сервис модерации. Этот сервис будет подписан на топик сервиса объявлений. При появлении нового объявления будет получать его и анализировать на соответствие некоторым заданным политикам.Например, настроили на экономические новости, то вам придут только экономические новости, но не новости про спорт. Apache Kafka запоминает, какие последние события получил consumer для этого используется служебный топик __consumer__offsets. Тем самым гарантируя, что при успешном чтении consumer не получит одно и то же сообщение дважды, что иногда критически важно.
Итак, коротко об особенностях Apache Kafka:
- Главным сценарием применения транзакций в Apache Kafka является упомянутый выше сценарий «чтение-обработка-написание». В транзакции могут участвовать сразу несколько топиков и разделов. Отправитель начинает транзакцию, создаёт пакет сообщений, завершает транзакцию. Если получатели используют по умолчанию изоляционный уровень «читать незафиксированное», они видят все сообщения, независимо от их транзакционного статуса (завершена, не завершена, отменена). Если получатели используют изоляционный уровень «чтение зафиксированного», они не видят сообщения, транзакции которых не завершены или отменены. Они могут принимать сообщения только завершённых транзакций.
- Apache Kafka славится способностью поглощать и пересылать титанические объёмы данных. В нём есть всё, что нужно для работы с высокими нагрузками: репликация, горизонтальное масштабирование, параллельная обработка потоков сообщений сразу на нескольких серверах.
- Для защиты от сбоёв у Kafka предусмотрена архитектура «ведущий—ведомый» на уровне раздела журнала, и в этой архитектуре ведущие называются лидерами, а ведомые ещё могут называться репликами. Лидер каждого сегмента может иметь несколько ведомых. Если на сервере, где находится лидер, происходит сбой, предполагается, что реплика становится лидером и все сообщения сохраняются, только обслуживание на короткое время прерывается.
- Уведомления о получении сообщений и отслеживание смещения. Учитывая то, как Apache Kafka хранит сообщения, и то, как они доставляются получателям, Kafka полагается на уведомления о получении сообщений для источников и отслеживание смещения чтения топика для получателей.
- Когда источник посылает сообщение, он даёт знать брокеру Kafka, какого рода уведомление он хочет получить.
- У Apache Kafka предусмотрена хорошая опция против проблем с дублированием.
- Параллелизм и распределённая архитектура хорошо сказываются на надёжности: даже выход из строя части кластера не нарушит доставку сообщений.
- В пересылке данных принимают участие поставщики и потребители данных. Поставщики пишут сообщения в Apache Kafka, потребители их читают. Для организации систем со сложной топологией применяют темы — своего рода разделы для категоризации различных сообщений по назначению.
- Для маршрутизации сообщений могут применяться Routing Keys, похожие на те, что используются в RabbitMQ. Но, в отличие от RabbitMQ, Apache Kafka гарантирует порядок доставки сообщений. Apache Kafka придерживается концепции синхронизации реплик (In Sync Replicas, ISR). Каждая реплика может быть или не быть в синхронизированном состоянии. В первом случае она получает те же сообщения, что и лидер, за короткий отрезок времени (обычно за последние 10 секунд). Она выпадает из синхронизации, если не успевает эти сообщения принять. Такое может произойти из-за сетевой задержки, проблем с виртуальной машиной узла и т.д. Потеря сообщений может произойти только в случае сбоя лидера и отсутствия участвующих в синхронизации реплик.
Who is Mr. RabbitMQ
RabbitMQ — это распределённый и горизонтально масштабируемый брокер сообщений. Он позволяет разным программам взаимодействовать с помощью протокола AMQP, а через дополнительные модули и с помощью некоторых других протоколов: MQTT, HTTP и так далее.
Устройство брокера упрощённо можно описать так:
- есть продюсер или поставщик сообщений, отправляющий события;
- очередь сообщений — своего рода «почтовый ящик», где хранятся сообщения;
- подписчики, то есть программы — получатели сообщений.
В очереди может храниться любое количество сообщений от неограниченного количества поставщиков, а получать их может неограниченное число подписчиков.
RabbitMQ поддерживает несколько языков программирования — Perl, Python, Ruby, PHP. А также обеспечивает горизонтальное масштабирование для построения кластерных решений. Поэтому RabbitMQ часто применяется в различных сложных корпоративных проектах. Однако, в связи с некоторыми его технологическими особенностями реализации, не является полноценной заменой Apache Kafka.
В упрощённом виде управление сообщениями выполняется в RabbitMQ следующим образом:
- отправители (publishers) отправляют сообщения на обменники (exchange);
- обменники отправляют сообщения в очереди и в другие обменники;
- при получении сообщения RabbitMQ отправляет подтверждения отправителям;
- получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь они получают;
- RabbitMQ проталкивает (push) сообщения получателям;
- получатели отправляют подтверждения успеха или ошибки получения сообщения;
- после успешного получения сообщение удаляется из очереди.
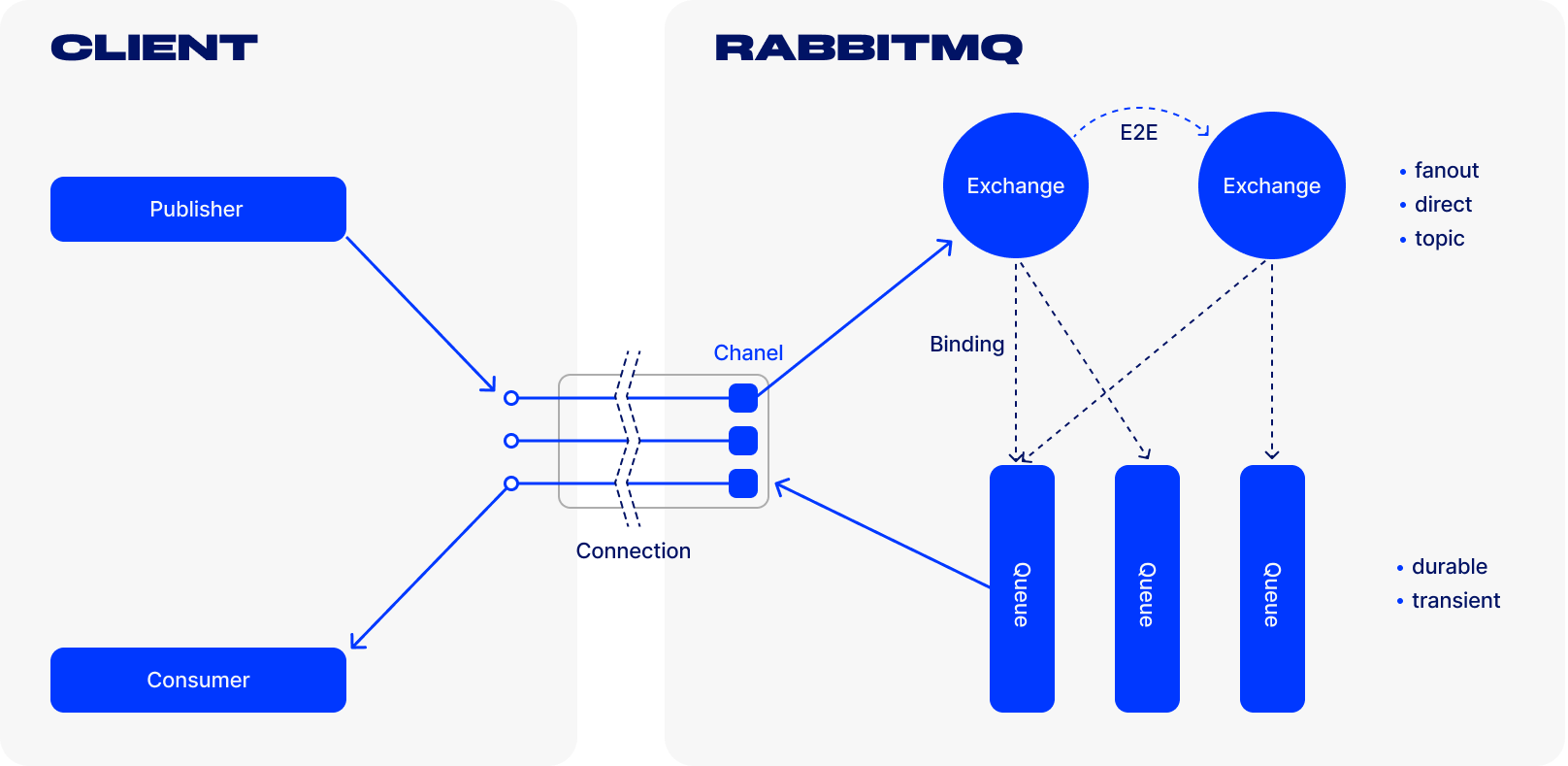
RabbitMQ принимает сообщения от поставщиков и отправляет им подтверждение о приёме, а затем перенаправляет их подписчикам. Получатели подтверждают, что сообщение доставлено, либо сигнализируют о неудаче. Во втором случае сообщение остаётся в очереди, пока не будет доставлено. А после доставки оно удалится из системы.
Основная фишка RabbitMQ — это гибкая маршрутизация сообщений между различными поставщиками и потребителями событий. Решение не ограничивается созданием простой очереди данных между двумя сторонами. В сервере реализована концепция принимающих события узлов (эксчейнджей) — они маршрутизируют данные в разные очереди сообщений RabbitMQ.
Например, одно и то же сообщение должны получить три подписчика. Оно попадёт на узел, который отправит три одинаковых сообщения в три очереди для всех подписчиков, которым оно должно быть доставлено.
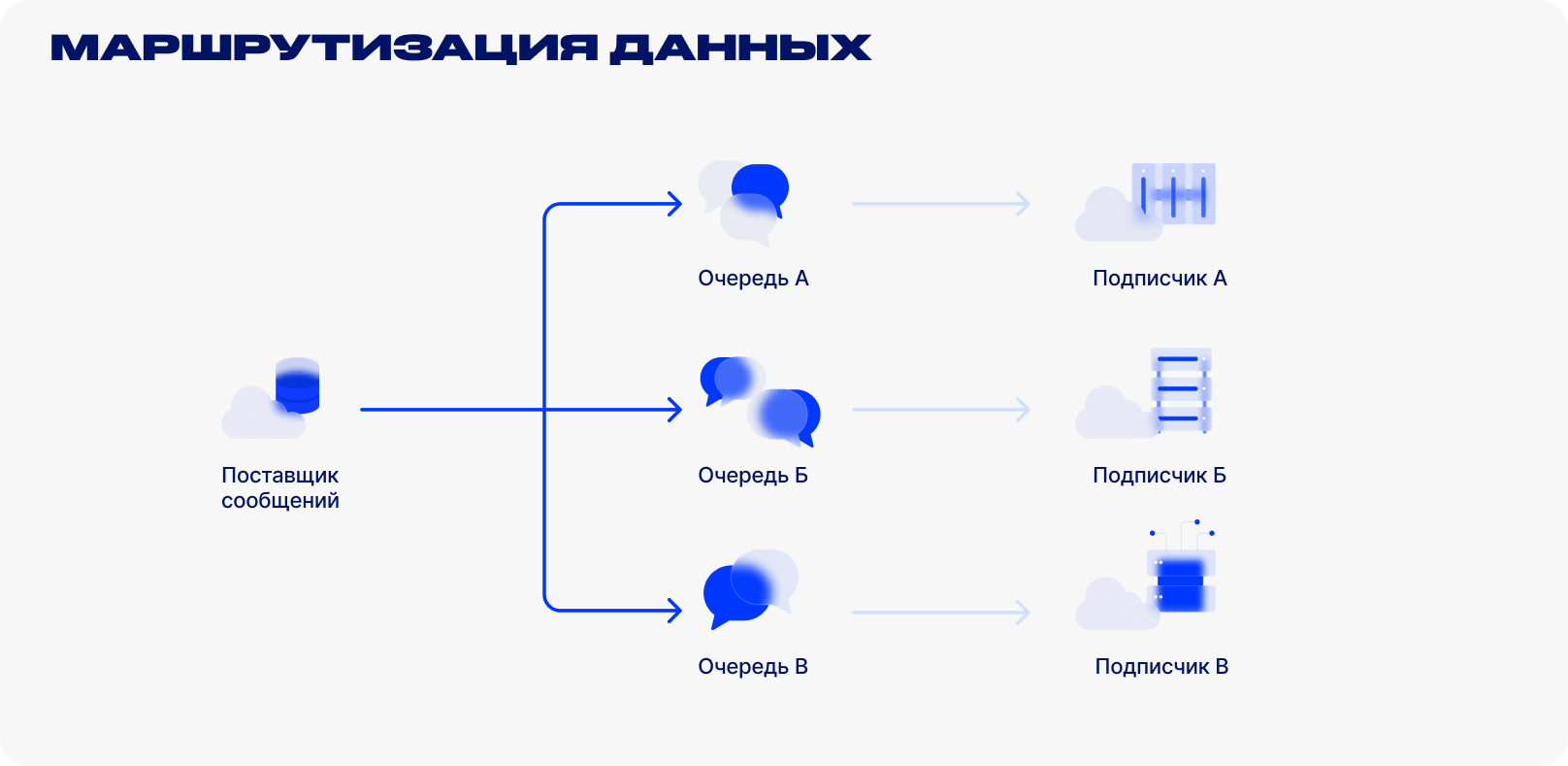
Механизм маршрутизации дополняют ключи маршрутизации (Routing Keys). Они позволяют создавать гибкие правила пересылки сообщений между источниками и потребителями. Благодаря этому RabbitMQ подходит для широкого спектра задач по реализации нетривиальных бизнес-процессов в коде.
Коротко об особенностях RabbitMQ:
- Обширные инструменты маршрутизации позволяют разработчикам и администраторам настраивать сложные системы с тысячами источников и приёмников сообщений. Решение подходит для систем бронирования билетов, логистических программ и микросервисных приложений.
- RabbitMQ реализует концепцию push-доставки: поставщик может направить новые события в сеть, но получатель не может их запросить у поставщика. При этом система не гарантирует порядок доставки сообщений.
Чем отличаются Apache Kafka и RabbitMQ
Основные отличия Apache Kafka и RabbitMQ обусловлены принципиально разными моделями доставки сообщений, реализуемыми в этих системах. В частности, Apache Kafka действует по принципу вытягивания (pull), когда получатели (consumers) сами достают из топика (topic) нужные им сообщения. RabbitMQ, напротив, реализует модель проталкивания, отправляя необходимые сообщения получателям. В связи с этим Apache Kafka отличается от RabbitMQ по следующим критериям:
Пакетирование сообщений — Apache Kafka обеспечивает более явное пакетирование сообщений. Пакетирование делается ради производительности, но иногда возникает необходимость в компромиссе между производительностью и другими факторами. Kafka более эффективно работает с пакетами со стороны получателя, потому что работа распределяется по разделам, а не по конкурирующим получателям. Каждый раздел закреплён за одним получателем, поэтому даже применение больших пакетов не влияет на распределение работы.
Сохранение сообщений — RabbitMQ помещает сообщение в очередь FIFO (First Input — First Output) и отслеживает статус этого сообщения в очереди, а Apache Kafka добавляет сообщение в журнал (записывает на диск), предоставляя получателю самому заботиться о получении нужной информации из топика. RabbitMQ удаляет сообщение после доставки его получателю, а Kafka хранит сообщение до тех пор, пока не наступит момент запланированной очистки журнала. Таким образом, Apache Kafka сохраняет текущее и все прежние состояния системы и может использоваться в качестве достоверного источника исторических данных, в отличие от RabbitMQ.
Балансировка — благодаря pull-модели доставки сообщений RabbitMQ сокращает время задержки. Однако возможно переполнение получателей, если сообщения прибудут в очередь быстрее, чем те могут их обработать. Поскольку в RabbitMQ каждый получатель запрашивает/выгружает разное количество сообщений, то распределение работы может стать неравномерным, что повлечёт задержки и потерю порядка сообщений во время обработки. Для предупреждения этого каждый получатель RabbitMQ настраивает предел предварительной выборки — ограничение на количество скопившихся неподтверждённых сообщений. В Apache Kafka балансировка нагрузки выполняется автоматически путём перераспределения получателей по разделам (partition) топика.
Пропускная способность — Kafka гарантирует порядок сообщений в разделе топика (partition) без конкурирующих получателей, что позволяет объединять сообщения в пакеты для более эффективной доставки и повышает пропускную способность системы.
Масштабируемость — Apache Kafka считается более адаптивной к масштабированию, обеспечивая ежедневный обмен миллиардами сообщений. Однако далеко на каждый проект с Big Data нуждается в таких высоких цифрах.
Маршрутизация — RabbitMQ включает четыре способа маршрутизации на разные обменники (exchange) для постановки в различные очереди, что позволяет использовать мощный и гибкий набор шаблонов обменов сообщениями. Kafka реализует лишь один способ записи сообщений на диск, без маршрутизации.
Упорядочивание сообщений — RabbitMQ позволяет поддерживать относительный порядок в произвольных наборах (группах) событий, а Apache Kafka обеспечивает простой способ поддержания упорядочения с поддержкой масштабирования путём последовательной записи сообщений в реплицированный журнал (топик).
Работа с клиентом — про Apache Kafka говорят «тупой сервер, умный клиент», что означает необходимость реализации логики работы с сообщениями на клиентской стороне, т.е. consumer заботится о получении нужных сообщений. RabbitMQ — наоборот, «умный сервер, тупой клиент», поскольку этот брокер сам обеспечивает всю логику работы с сообщениями.
Так что выбрать?
Обратной стороной широких и разнообразных возможностей RabbitMQ по гибкому управлению очередями сообщений (маршрутизация, шаблоны доставки, мониторинг получения) является повышенное потребление ресурсов и, соответственно, снижение производительности в условиях увеличенных нагрузок. Поскольку именно такой режим работы характерен для сложных систем, то в большинстве случаев Apache Kafka является наилучшим средством для управления сообщениями.
Например, в случае сбора и агрегации множества событий от десятков систем, и сервисов с учётом их георезервирования, клиентских метрик, лог-файлов и аналитики с перспективой увеличения источников информации понадобится Apache Kafka. А если необходим быстрый обмен сообщениями между несколькими сервисами, RabbitMQ отлично справится с этой задачей.
RabbitMQ можно использовать для обработки событий в режиме реального времени. Этот брокер — решение только для реагирования на события, которые происходят сейчас. Kafka, напротив, обеспечивает полную историческую достоверность и сохранность всех данных, а также упрощает их распространение. Исходные данные принадлежат только отправителю, но каждый получатель может их фильтровать, трансформировать, дополнять данными из других источников и сохранять в собственных базах данных.
В целом RabbitMQ предоставляет надёжные, долговременные гарантии обмена сообщениями, но есть очень много ситуаций, когда они не помогут. Вот список моментов, которые следует запомнить:
- Следует применять зеркалирование очередей, надёжные очереди, устойчивые сообщения, подтверждения для отправителя, флаг подтверждения и принудительное уведомление от получателя, если требуются надёжные гарантии в стратегии «как минимум однократная доставка».
- Если отправка производится в рамках стратегии «как минимум однократная доставка», может потребоваться добавить механизм дедубликации или идемпотентности при дублировании отправляемых данных.
- Если вместе с RabbitMQ используется устаревший API для считывания больших пакетов, это может привести к крайне неравномерной нагрузке между конфликтующими между собой получателями и значительным задержкам в обработке данных. RabbitMQ по своему устройству не подходит для пакетной обработки сообщений.
- Если вопрос потери сообщений не так важен, как вопрос скорости доставки и высокой масштабируемости, то подумайте о системах без резервирования, без устойчивых сообщений и без подтверждений на стороне источника. Проще говоря, RabbitMQ не подходит для финансового сектора.
Выбирайте RabbitMQ, если вам нужна гибкость маршрутизации, а порядок доставки сообщений безразличен, что, к сожалению, не подходит для финансового сектора. Apache Kafka, в свою очередь, подойдёт идеально, если работаете с большими нагрузками (mission and business critical системы), важна масштабируемость, доставка сообщений в правильном порядке и возможность просматривать историю сообщений.





