Google выпустила набор видеоданных AVA для распознавания человеческих действий

Несмотря на невысокую точность, AVA может использоваться как отличный старт для будущих алгоритмов распознавания действий.
Обучение машин определению действий человека на видео является фундаментальной проблемой в области компьютерного зрения. Области применения таких технологий безграничны — от поиска человека на видео до анализа спортивных событий.
Общепринятый подход к проблеме
Несмотря на тот факт, что в прошлые годы были сделаны значительные прорывы в областях классификации и распознавания объектов на видео, определение человеческих действий остаётся большим вызовом для учёных. Это связано с тем, что действия по своей природе менее чётко определены, чем отдельные объекты на видеороликах. Поэтому так сложно создать точно определённый набор данных действий на видео.
Общепринятый подход классификации действий, используемый UCF101, ActivityNet и Kinetics от DeepMind, основывается на схеме классификации изображений и присваивает лишь одну метку каждому видео. Но на данный момент нет наборов данных, содержащих метки для нескольких людей, присутствующих на видео и выполняющих разные действия.
Разработка AVA
Чтобы облегчить дальнейшие исследования в области распознавания человеческих действий, Google выпустили набор данных AVA (atomic visual actions, атомарные визуальные действия), который предоставляет несколько меток действий для каждого человека в видеороликах.
AVA содержит URL-адреса видео YouTube, которые были аннотированы набором из 80 отдельных действий (например, прогулка, удар по объекту, рукопожатие), и, в общей сложности, состоит из почти 58 тысяч видеофрагментов, 96 тысяч человеческих действий и 210 тысяч аннотаций действий. Набор данных доступен на сайте проекта. Google также выпустила в свободный доступ статью, описывающую дизайн и разработку AVA.
Ключевые особенности AVA
- Ориентированная на человека аннотация. Каждая метка действия связана с человеком, а не с видеофрагментом. Следовательно, можно назначать разные ярлыки нескольким людям, выполняющим разные действия в одной и той же сцене.
- Атомарные визуальные действия. Каждое обозначение действий ограничено точными временными шкалами (3 секунды), где действия носят физический характер.
- Реалистичные видеоматериалы. В качестве источника данных в AVA используются реальные фильмы, а не специально снятые видеоматериалы. В результате, данные имеют широкий спектр человеческого поведения.
{kind=link}
Создание AVA
Для создания AVA команда разработчиков собрала разнообразный набор контента с YouTube из категорий «фильм» и «телевидение», в которых участвуют профессиональные актёры разных национальностей. Затем был проведён анализ 15-минутных клипов из каждого видео с последующим равномерным разделением их на 300 непересекающихся 3-секундных сегментов.
После этого была проведена ручная аннотация действий одним из 80 определённых классов. Все действия были разделены на три группы: действия движения, взаимодействие человека с объектом и взаимодействие человека с человеком.
Интересная статистика AVA
Поскольку все действия на видеороликах были помечены, учёные смогли создать график распределения каждого из них.
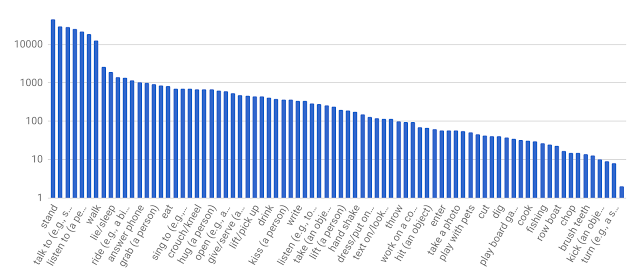
Также учёные смогли собрать более интересную статистику человеческих действий. Взяв выборку, состоящую из людей, которые совершают не менее двух действий на видеофрагменте, можно получить пары действий с их оценками совпадений. Были определены шаблоны таких действий. Например, люди часто «играют на музыкальных инструментах» во время «пения»; если «играют с детьми», то вероятное второе действие — это «подъём на руки человека». Действие «держать лопату» часто сопровождается «копать», а «объятия» — «поцелуем».

Оценка качества AVA
Чтобы оценить эффективность систем распознавания человеческих действий в наборе данных AVA, была внедрена существующая базовая модель глубинного обучения, которая обеспечивает высокую производительность на гораздо меньшем наборе данных JHMDB. Оценочная модель показала относительно скромную производительность при правильной идентификации действий на AVA (18,4% mAP). Это говорит о том, что AVA будет полезным испытательным полигоном для разработки и оценки новых архитектур и алгоритмов распознавания действий.

966 открытий968 показов

МТС разработал собственный антифрод-сервис. Алгоритм умеет определять ещё на этапе авторизации надёжность пользователя.

OpenAI сообщила, что GPT-4 8k для чат-бота ChatGPT теперь доступна всем пользователям платного API, у которых есть хорошая история платежей.

Разобрались, как Google развивает решения на основе нейросетей и искусственного интеллекта, и с какими проблемами сталкивается.
Сбер открыл бесплатный доступ к сервису для синтеза и распознавания речи SaluteSpeech для физических лиц. Но с ограничениями.