


С чего начать карьеру в ML в 2025: инструменты, навыки, практика


По оценкам McKinsey, до 40% задач, связанных с анализом данных и ML, теряются на стадии подготовки. Расскажем, как можно выучить базу ML, чтобы поправить печальную статистику.
1К открытий5К показов

Машинное обучение в 2025 году — это быстро меняющийся стек, десятки новых библиотек и постоянное ощущение, что вы не успеваете. Старт похож на вход в лабиринт: стены высокие, где-то притаились баги, а на карте нет подсказок.
В статье расскажем, с чего начать тем, кто хочет зайти в ML с практической стороны. Дадим информацию о стеке, который используется в реальных проектах и поможет собрать свой первый рабочий ML-сервис.
Сначала выберитесь из симулятора
Начинать сразу с нейросети — это как пытаться собрать космический корабль, когда ещё не знаешь, как держать отвёртку. Если сразу нырять в модели, как делают на многих курсах, то совсем скоро наступает эффект симулятора. Вы отлично справляетесь в учебной среде, но стоит попытаться применить всё в реальной системе, как внезапно ничего не работает. Как будто учились водить на автодроме, а потом выехали в час пик на МКАД.
Если вы правда хотите зайти в ML, начните не с курсов, а с вопроса — что это вообще за область? В 2025 году машинное обучение — это десятки направлений, а не просто учим Python и запускаем GPT.
Многие новички кидаются в ML, потому что это тренд. Потом сталкиваются с тем, что у них всё лагает. Чтобы избежать этого, нужна база — научиться писать нормальный код и читать чужой. Другими словами, стать крепким инженером-программистом.
Это не обязательно человек с дипломом MIT и 10 годами в FAANG. В первую очередь, это разработчик, который умеет думать системно и собирать рабочие решения.
Вот его ключевые харды:
- умеет строить сервисы — разбирается, как модули общаются друг с другом;
- дебажит код — понимает, где и почему всё лажает;
- пишет тесты, чистый код, умеет проводить код-ревью;
- владеет Git и CI/CD;
- понимает, как автоматизировать запуск и деплой моделей в продакшн.
В реальных ML-проектах модель — это лишь одна часть системы. Чаще всего модель должна работать внутри веб-сервиса, обрабатывать реальные данные, взаимодействовать с другими модулями, логировать ошибки и масштабироваться под нагрузкой. Именно здесь вступает в игру инженер.

По данным исследования 365 Data Science, в 78% вакансий data scientist в 2023 году требовался Python, а в 2024‑м — в 57%. Python — это универсальный язык для всего ML-стека: от загрузки данных и визуализации до построения нейросетей и взаимодействия с API. Его поддерживают почти все библиотеки в ML. Легко подключить нужные инструменты, а не писать код с нуля. Например:
- scikit-learn — простая и понятная библиотека для классических моделей (логистическая регрессия, деревья решений).
- PyTorch и TensorFlow — два основных фреймворка для работы с нейросетями. Они позволяют строить простые модели для начинающих и сложные, многослойные архитектуры для продвинутых задач.
- Hugging Face Transformers — библиотека с готовыми моделями, которые умеют работать с текстом (например, перевод, суммаризация, генерация).
- LangChain — инструмент, который помогает собирать ассистентов на базе языковых моделей.
Если вы знаете Python, можете взять любую из этих библиотек и сразу пробовать писать код.
Чтобы комфортно работать с ML-инструментами, важно уверенно обращаться с базовыми возможностями языка. Это нужно, чтобы не спотыкаться о синтаксис и не тратить время на борьбу с окружением:
- Писать чистые функции и классы, использовать list comprehensions — чтобы ваш код легко могли читать другие, и он не превращался в кашу при росте проекта.
- Работать с pip и виртуальными окружениями (venv, poetry) — чтобы проекты не конфликтовали между собой, а зависимости не ломались при каждом обновлении.
- Читать и использовать чужой код, особенно в open source — потому что почти всё в ML строится на готовых библиотеках и чужих решениях. Понимать чужой код — значит, адаптировать, дебажить и развивать решения быстрее.
C++ встречается гораздо реже — например, в проектах, связанных с оптимизацией скорости работы модели, inference на edge-устройствах или в библиотечном ядре фреймворков. Это уровень хард, где начинающим пока делать нечего.
Что поможет выжить: теория без перегруза
Машинное обучение — это прикладная статистика и немного линейной алгебры. Не нужно знать всё, чтобы начать. Нужно разобраться в основах, чтобы понимать, что вообще происходит в модели и почему она работает:
- Что такое модель. Это формула или набор правил, которые помогают находить закономерности в данных — например, отличать спам от нормальных писем.
- Как она учится. Модель смотрит на примеры из прошлого — обучающую выборку. Она подбирает внутренние параметры и учится предсказывать результат. После этого модель нужно проверить на новых данных, чтобы понять, не переучилась ли она. Если слишком точно запомнила обучающие примеры, может угадывать, вместо того, чтобы выявлять общие закономерности. Такая модель отлично работает на старых данных, но даёт много ошибок на новых — это и называется переобучением (overfitting).
- Почему accuracy = 99% — не всегда хорошо. Допустим, у вас 99% нормальных отзывов и 1% фейков. Модель, которая всегда отвечает «всё нормально», покажет 99% точности — но не найдёт ни одного фейка. Поэтому важны другие метрики: precision — точность срабатываний, recall — насколько хорошо находит редкости, F1-score — баланс между ними.
- Что такое трансформеры и эмбеддинги. Трансформеры — архитектура нейросетей, которая хорошо работает с текстами. Эмбеддинги — способ превращать текст или объекты в набор чисел, с которыми можно работать как с векторами. Например, GPT — это трансформер с эмбеддингами.
- Где грань между знанием и применением. Вы не обязаны самостоятельно выводить формулы, но нужно понимать: модель может ошибаться. В идеале ещё хорошо бы знать, как это проверить.
В комментариях дадим ссылки на бесплатные онлайн-курсы по ML, подходящие для быстрого старта.
Как работает обученная модель — заглянем под капот ML-проектов
Обучить модель — это только половина дела. Чтобы она действительно приносила пользу, её нужно обернуть в сервис и внедрить в продуктовую цепочку. Здесь начинается работа с инфраструктурой. Вот как это выглядит на практике:
- API — кнопка «позвать модель» в сервисе. Без неё никто не сможет использовать продукт. Например, фрейм FastAPI помогает обернуть модель в веб-приложение, чтобы она принимала запросы через интернет.
- Docker — контейнер, в который вы собираете всю модель, зависимости и окружение. Благодаря этому код работает одинаково у вас на ноутбуке и у коллеги в облаке.
- Облачные сервисы типа AWS, GCP и Kubernetes — позволяют автоматически запускать и масштабировать модели в продакшене. Если у вас тысячи пользователей, система сама создаст нужное количество копий модели и будет следить, чтобы всё работало.
- Очереди и базы данных (Kafka, Redis, PostgreSQL) — позволяют обмениваться данными между частями системы. Kafka принимает потоки данных в реальном времени, Redis — быстро отдаёт часто запрашиваемое.
- Мониторинг и логирование (OpenTelemetry, Grafana, Sentry) — чтобы понимать, когда модель ломается, тормозит или начинает давать странные ответы.
- CI/CD — чтобы можно было обновлять модель и код автоматически. Например, после пуша в GitHub система сама собирает и выкатывает новую версию.
- Хранилища артефактов (MLflow, Weights & Biases) — журналы экспериментов. Они позволяют отслеживать, какая модель была обучена, на каких данных, с какими параметрами и как себя вела.
По данным Wallaroo.AI, путь от модели до продакшена в компаниях обычно занимает от 31 до 90 дней, а иногда — больше года. Только 13% моделей доходят до боевого запуска. Всё из-за того, что инфраструктура сложнее, чем сама модель.
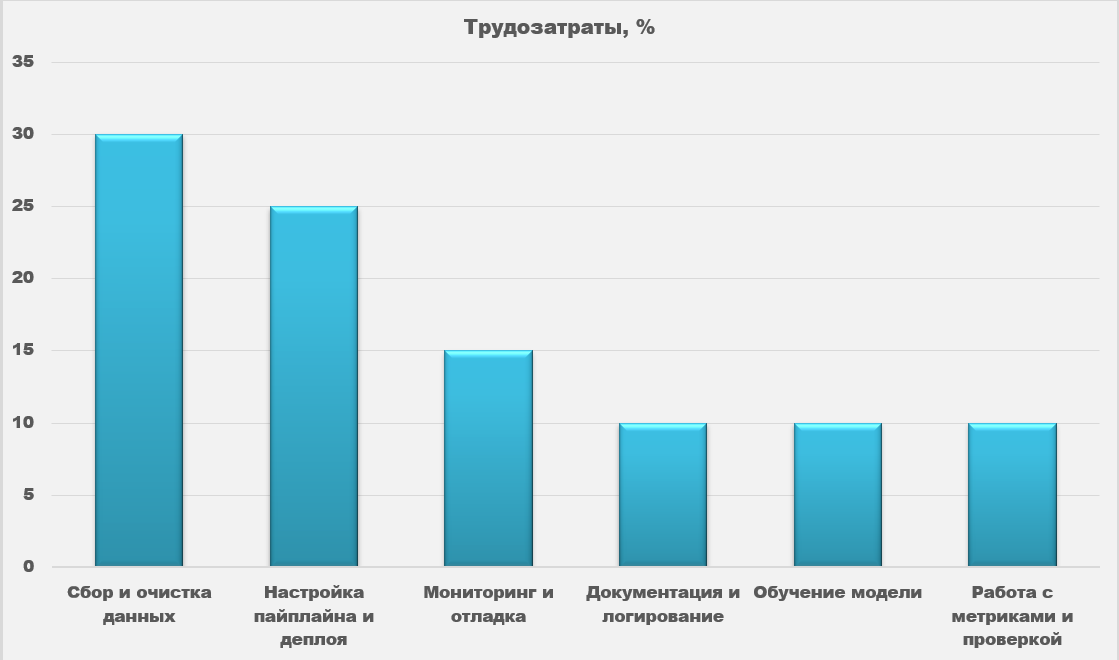
Соберите агента из кубиков
Многие не тренируют свои модели с нуля, а используют LLM (large language model). Это большие языковые модели, обученные на огромных объёмах текста. Они понимают человеческий язык и генерируют его сами. Для обращения к модели нужен API, как канал связи с мозгом. Вы пишете запрос, она отвечает.
Примеры популярных LLM:
- GPT (Open AI)
- Claude (Ahtropic)
- Llama (Meta*)
- Gemini (Google)
*Meta признана экстремистской организацией и запрещена в России
А если вы хотите, чтобы бот делал цепочку действий, нужен LangGraph. Это библиотека, которая собирает многошаговые сценарии. Например, пользователь пишет в чат: «Помоги написать жалобу в банк».
Что делает агент:
- Определяет суть запроса.
- Запрашивает пользовательские данные.
- Подставляет шаблон.
- Формирует письмо.
- Возвращает готовый текст.
Аналогично можно строить агентов для поддержки, ассистентов, генераторов контента.
Как не потеряться в AI-шуме
Каждую неделю появляются десятки новых инструментов, библиотек, фреймворков. Это создаёт иллюзию: «чтобы не отстать, надо учить всё».
Чтобы не страдать от FOMO (fear of missing out) — страха пропустить что-то важное:
- Следите за 2–3 проверенными источниками
- Не скачивайте каждый новый хайповый инструмент — спросите себя: «Я это реально буду использовать?»
- Не гонитесь за громкими названиями (AutoGPT, Agentic Framework, Prompt Flow), потому что они приходят и уходят.
Лучше знать, как стабильно задеплоить простую модель, чем разобраться в десятке фреймворков, которыми никто не пользуется.
Полезные источники:
- Блоги и сайты: OpenAI, Google DeepMind, Hugging Face, KDnuggets, The Gradient, MarkTechPost, Distill
- Рассылки: The Rundown AI, TLDR AI, Ben’s Bites, The Batch, Import AI
- Telegram-каналы: Chat GPT, DeepLearning_ai, Machine Learning, Data Science Info
Подпишитесь на пару из каждой категории, чтобы оставаться в курсе, но не утонуть в потоке.

Хватит читать туториалы — пора наступать на грабли
Самый важный навык — уметь разбираться в новом. На курсах вы получаете теорию, но настоящий рост начинается, когда вы сами что-то строите.
Что можно сделать на старте:
- Ассистент для обработки писем с GPT + LangGraph.
- Модель, которая предсказывает, когда тебе пора за кофе, по данным с ноутбука.
- Классификатор отзывов на сайте + FastAPI + Docker.
- Парсер, который берёт данные с сайта, и ML-модель, которая классифицирует категории.
Пытаться сразу охватить весь ML, особенно на старте, тяжело и вредно. Лучше выбрать конкретную область, формализовать, какие умения там нужны, и двигаться оттуда. Иначе вы рискуете знать всё понемногу, но не уметь ничего всерьёз. Даже сейчас, с появлением Foundation и Multimodal Models, нет массовых вакансий, где нужно уметь всё.
Где искать задачи и проекты:
- GitHub. Используйте теги machine-learning, open-source, good first issue.
- Kaggle, OpenML. Участвуйте в соревнованиях и совместных проектах по анализу данных.
- Фриланс-биржи. На Upwork, Freelancer, PeoplePerHour, Workana часто появляются заказы на ML-разработку, обучение моделей, создание аналитических инструментов.
- Профильные сообщества и форумы. Мониторьте Reddit, специализированные Telegram-каналы, Slack-группы.

С чего стоит начинать путь в ML в 2025 году
- Без базовых навыков разработки всё будет ломаться и тормозить.
- Python — основной язык.
- На старте нужно знать, как учатся модели, какие бывают, как их проверять.
- Для любой production-модели нужны API, Docker, базы, логирование.
- В продукте часто используют готовые модели через OpenAI/Anthropic API, а не обучают свои.
- Необязательно учить каждую новинку и читать 10 рассылок каждый день.
- Пет-проекты, опенсорс и фриланс дают реальный рост.
- Сейчас всё быстро меняется, важно уметь учиться и не паниковать.
Читайте также:
- 7 курсов, с которых реально стартуют в IT в 2025
- Великий ИИ-провал: почему 8 из 10 компаний, внедривших нейросети, не заработали ни цента
- История одного пет-проекта: как я утомился от SQL и создал ИИ-сервис для обучения
- DeepSeek или Claude: какая нейросеть напишет код, за который не стыдно?
- Рейтинг курсов по Machine Learning, включая бесплатные программы по машинному обучению

1К открытий5К показов

React — практически самостоятельный язык программирования. Готов проверить, хорошо ли ты знаешь паттерны?

Гиперконвергенция — современный способ сделать проще, эффективнее и быстрее работу всей IT-инфраструктуры. Рассказываем, что это такое и почему она выгодна бизнесу на примере vStack HCP.
Ещё немного плохих новостей о Google. Бывший инженер компании Правин Сешедри назвал причину её медленной гибели.
Узнайте, что такое Grafana, как она помогает в мониторинге и анализе данных, создавайте мощные дашборды и визуализируйте данные для повышения эффективности работы.